模型|Sky Computing:利用空间异构分布式计算特性加速联邦学习( 二 )
文章插图
木桶效应
Sky Computing
Sky Computing 针对以上痛点,通过负载均衡,将不同规模和能力的云服务器智能互联,达到大规模计算的算力需求,同时通过联邦学习的方式,仅在云服务器内部访问用户数据,避免数据迁移和隐私泄露。
负载均衡
要解决负载均衡的问题,首先要了解什么是「负载」。在计算机中,无论进行哪种操作,究其本质,负载都可以理解为「完成任务所需的时间」。由于在联邦学习中,训练模型的计算总量是固定的,因此如果我们能通过自适应的方式智能分配计算任务,便能够使得每个设备完成计算任务的耗时相同,确保整体训练的时间最优。而为了得到一个好的分配方式,我们需要首先得到模型和设备相关信息,然后再进行实际的适当分配操作。因此,对于训练模型,我们需要分为两个阶段:基准测试和分配。

文章插图
训练过程
基准测试
在基准测试阶段,Sky Computing 需要收集来自两个维度的数据:模型和设备。在模型维度,需要知道模型每一层所需的内存占用和计算量。通过结合模型的预计内存占用和设备的可用内存,可避免内存溢出;而所需计算量越大,同一设备完成该任务的时间就越久。在设备维度,需要知道设备的通讯延时、计算能力和可用内存等,受网络环境、当前运行负载等因素的影响。对于算力强、通信好但可用内存少的设备,应在内存不溢出的前提下,尽量多分配模型层(计算任务)。由于 Sky Computing 是一个负载均衡的联邦学习系统,因此我们在基准测试阶段只关心设备的机器学习的能力。通过在每个设备运行小型的机器学习测试任务,测探设备的AI计算能力。

文章插图
整体流程
分配
在决定任务分配方式时,经数学分析可知,分配方式本质上是一个NP-hard的混合整数线性规划问题。因此,在多项式时间内,我们无法得到一个最优解。而随着模型规模的不断增长,和设备数量的不断增多,计算最优解的成本显然是不可接受的。
因此,在实际情况中,我们不会直接计算求得最优解,而是尝试使用启发式算法得到近似解。在 Sky Computing 中,我们设计了一个两阶段的启发式算法:第一阶段为预分配,按照设备的实际可用内存大小进行模型的分配,并且计算每个设备实际的工作负载;第二阶段为分配调整,根据设备的负载量进行动态的调整,迭代降低整个系统的负载量。同时,为了验证 Sky Computing 的优越性,我们在实验中也设置了最优分配作为对比。
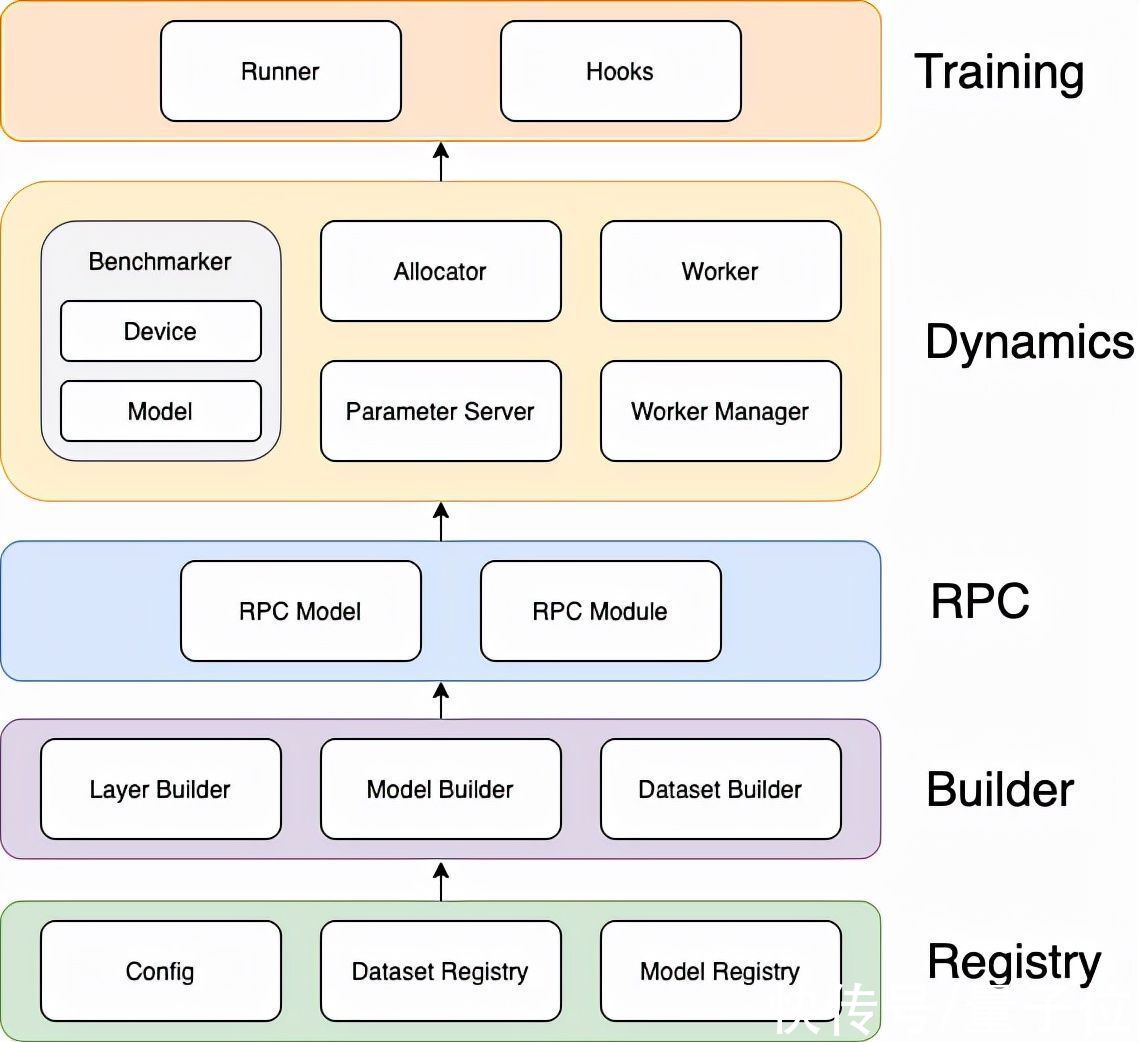
文章插图
实现架构
性能表现
我们在集群环境中,采用控制关键因素变量的方式,以联邦学习AI任务的forward 和 backward 的时间为指标,对Sky Computing的性能进行了验证。
实验结果
我们测试了三种分配方式(even:均匀分配,heuristic:启发式算法,optimal:最优分配)。在不同的计算资源数量规模和不同的模型大小下的表现,并记录了每次完成迭代所花费的时间。可以看到,随着设备数量的增多和模型深度的增加,我们的启发式算法的效果十分显著。在64个节点160层隐藏层的实验环境下,Sky Computing 比当前的均匀分配模型并行可加速55%。

文章插图
实验结果
其中,由于最优分配计算成本极高,在64节点时已难以计算,不适用于实际应用,仅作为小规模时的参考值。
- 稀疏模型在深度学习领域发挥着越来越重要的作用。|routerz-loss模型的重要性
- 本文转自:海南日报这个周日海南文昌将有“大事”发生准备就绪的长征八号遥二运载火箭将于2月...|来文昌看火箭发射,记得把火箭模型和千元奖金领回
- Jeff Dean:我们写了一份“稀疏模型设计指南”,请查收
- 为了克服现下大型神经网络模型一跑就要大量耗电的弊端|神经拟态芯片与人脑设计
- 3张图片生成一个手办3D模型!华人博士提出新模型NeROIC,更真实
- 优先级|根据福格行为模型,设计销售SOP
- 甲方|干货分享:To G项目管理五力模型
- 企业做私域,如何做业务模型梳理和设计
- 企业|企业做私域,如何做业务模型梳理和设计
- 迈凯伦|乐高推出机械F1赛车模型 你会买吗