任务|有了“大数据”,还需“多任务”,谷歌AI大牛Quoc V. Le发现大模型零样本学习能力的关键( 三 )
对于分类任务,先前Brown等人的工作使用了等级分类方法,例如,只考虑两个输出("是 "和 "不是"),将概率较高的一个作为模型的预测。
虽然这个程序在逻辑上是合理的,但它并不完美,因为答案的概率质量可能有一个不理想的分布(例如,大量替代性的 "是 "的表达方式,比如“对”、“正确”,可能降低分配给 "是 "的概率质量)。
因此,我们加入了一个选项后缀,即在分类任务的末尾加上OPTIONS标记,以及该任务的输出类别列表。这使得模型知道在响应分类任务时需要哪些选择。图1中的NLI和常识性的例子显示了选项的使用。
2.4 训练细节
模型架构和预训练。在我们的实验中,我们使用了一个密集的从左到右的、只有解码器的1370亿参数的Transformer语言模型。这个模型在网络文档(包括那些带有计算机代码的文档)、对话数据和维基百科上进行了预训练,使用SentencePiece库(Kudo & Richardson, 2018)将其标记为2.81T BPE tokens,词汇量为32K tokens。大约10%的预训练数据是非英语的。这个数据集不像GPT-3的训练集那样单一,也有对话和代码的混合物,因此我们预计一开始这个预训练的语言模型在NLP任务上的零样本和小样本性能会略低。因此,我们把这个预训练的模型称为基础语言模型(Base LM)。这个模型以前也曾被用于程序合成。
指令微调程序。FLAN是Base LM的指令微调版本。我们的指令微调管道混合了所有的数据集,并从每个数据集中随机抽取例子。一些数据集有超过1000万个训练实例(例如翻译),因此我们将每个数据集的训练实例数量限制在3万个。其他数据集的训练例子很少,为了防止这些数据集被边缘化,我们遵循实例-比例混合方案(examples-proportional mixing scheme),混合率最大为3000。我们的微调程序中使用的输入和目标序列长度分别为1024和256。我们使用打包的方法将多个训练实例合并成一个序列,并用一个特殊的序列末端标记将输入和目标分开。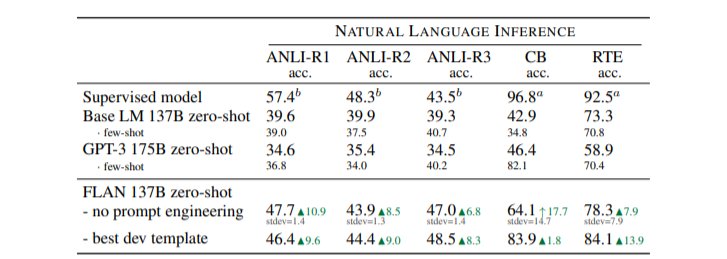
文章插图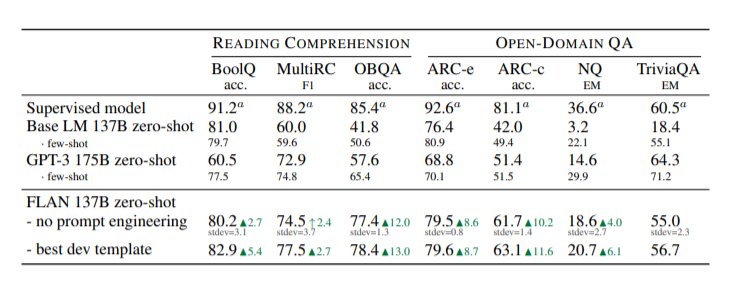
文章插图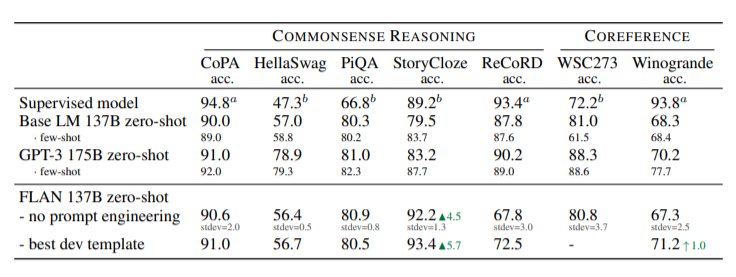
文章插图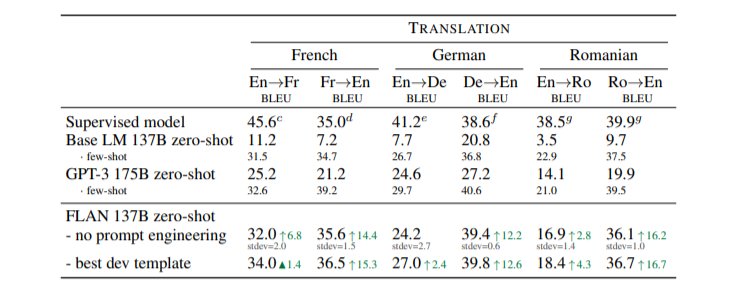
文章插图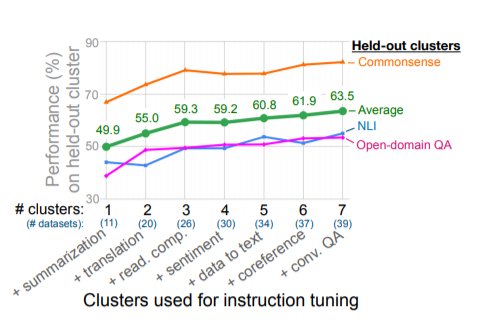
文章插图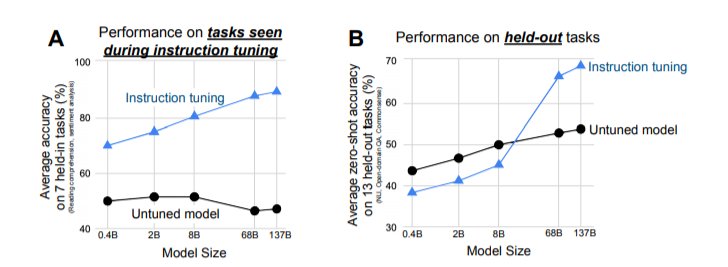
文章插图
- 苹果|库克压力确实大,在众多国产厂家对标下,iPhone13迎来“真香价”!
- 京东正式上线“年礼无忧”服务
- 央视公开“支持”倪光南?柳传志该醒悟了
- 小米 11 Ultra 内测 NFC“读写勿扰”与“解锁后使用”功能
- 造车|苹果造车一波三折,缺了一家“富士康”
- 他是“中国氢弹之父”,他的名字曾绝密28年,他叫于敏
- iPhone|iphone14价格被曝!“胶囊”挖孔屏+三星4nm芯片,售价或5999起
- 36氪5G创新日报0112|福建省首个“5G+VR”英模会客厅正式上线;齐鲁医院健康管理中心“5G+ 5g
- 物联网|据说,物联网也可以称之为“一张想想的网络”,物联网世界是梦
- 部署|华为获欧洲大国力挺,5G部署有了新的可能