任务|有了“大数据”,还需“多任务”,谷歌AI大牛Quoc V. Le发现大模型零样本学习能力的关键

文章插图
编译 | 王晔
文章插图
结果表明,FLAN极大地提高了其未调整的对应模型的性能,并且在我们评估的25个任务中,有19个任务超过了零样本设定下参数为1750亿的GPT-3。
在ANLI、RTE、BoolQ、AI2-ARC、OpenbookQA和StoryCloze上,FLAN甚至以很大的优势超过了小样本GPT-3。消融研究显示,任务数量和模型规模是指令微调成功的关键因素。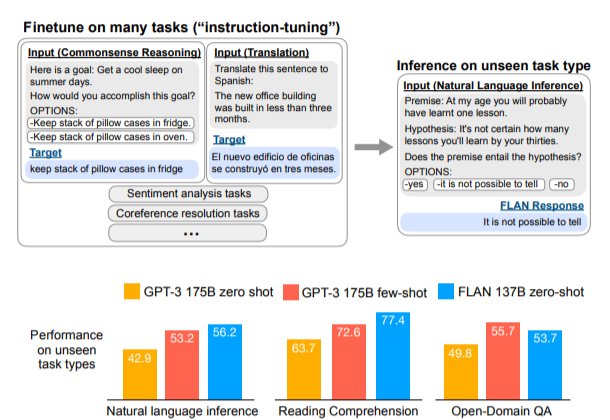
文章插图
图1:上面:指令微调和FLAN概述。指令微调是在以指令描述的任务集合上对预训练的语言模型进行微调。在推理中,我们对一个未见过的任务类型进行评估;例如,如果在指令微调期间没有学习过自然语言推理(NLI)任务,我们可以用NLI任务对模型进行评估。下面:与零样本 GPT-3 和小样本GPT-3相比,零样本FLAN在未见过的任务类型上的表现。
本文中,我们探索了一种简单的方法来提高大型语言模型的零样本性能。我们利用了NLP任务可以通过自然语言指令来描述的直觉,比如 "这个电影评论是正面情绪的还是负面的?"或者 "把'你好吗'翻译成中文"。
我们采用了一个参数为1370亿的预训练语言模型,并对该模型进行指令微调——对60多个通过自然语言指令表达的NLP任务的集合进行微调。我们把这个模型称为Finetuned LAnguage Net(FLAN)。
为了评估FLAN在未见过的任务上的零样本性能,我们将NLP任务根据其任务类型分为几个群组,并对某个群组进行评估之前,在所有其他群组上对FLAN进行指令微调。
例如,如图1所示,为了评估FLAN执行自然语言推理的能力,我们先在一系列其他NLP任务上对模型进行指令微调,如常识推理、翻译和情感分析。由于这种设置确保了FLAN在指令微调中没有学习过任何自然语言推理任务,因此我们可以再评估其进行零样本自然语言推理的能力。
评估表明,FLAN极大地提高了基础1370亿参数模型在零样本场景下的性能。在我们评估的25个任务中的19个任务里,零样本场景下的FLAN也优于参数为1750亿参数的GPT-3,甚至在一些任务上,如ANLI、RTE、BoolQ、AI2-ARC、OpenbookQA和StoryCloze,也明显优于小样本GPT-3。在消融实验中,我们发现在指令微调中增加任务群的数量可以提高未学习任务的性能,而且只有在有足够的模型规模时,指令微调的优点才会显现。
- 苹果|库克压力确实大,在众多国产厂家对标下,iPhone13迎来“真香价”!
- 京东正式上线“年礼无忧”服务
- 央视公开“支持”倪光南?柳传志该醒悟了
- 小米 11 Ultra 内测 NFC“读写勿扰”与“解锁后使用”功能
- 造车|苹果造车一波三折,缺了一家“富士康”
- 他是“中国氢弹之父”,他的名字曾绝密28年,他叫于敏
- iPhone|iphone14价格被曝!“胶囊”挖孔屏+三星4nm芯片,售价或5999起
- 36氪5G创新日报0112|福建省首个“5G+VR”英模会客厅正式上线;齐鲁医院健康管理中心“5G+ 5g
- 物联网|据说,物联网也可以称之为“一张想想的网络”,物联网世界是梦
- 部署|华为获欧洲大国力挺,5G部署有了新的可能