任务|有了“大数据”,还需“多任务”,谷歌AI大牛Quoc V. Le发现大模型零样本学习能力的关键( 二 )
我们的实证结果强调了语言模型执行用自然语言指令描述的任务的能力。更为广泛的结论是,如图2所示,通过微调的方式进行监督,来提高语言模型对推理-时间文本交互的反应能力,指令微调结合了预训练调整和prompting范式中吸引人的特点。
用于加载FLAN的指令微调数据集的源代码:https://github.com/google-research/flan 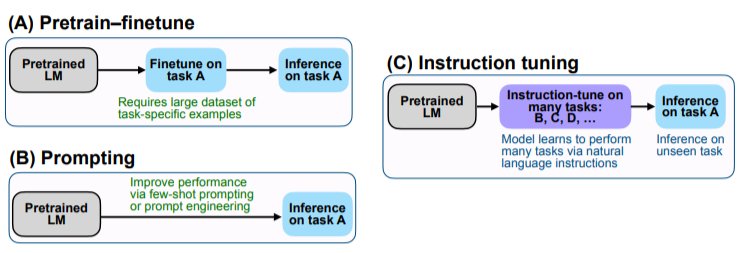
文章插图
2.1 任务&模板
从零创建一个具有大量任务的可行的指令调整数据集需要集中大量资源。因此,我们选择将现有研究创建的数据集转化为指令格式。我们将Tensorflow数据集上公开的62个文本数据集,包括语言理解和语言生成任务,汇总成一个集合。图3展示了我们使用的所有数据集;每个数据集都被归入十二个任务群组中的一个,每个群组中的数据集都属于同一任务类型。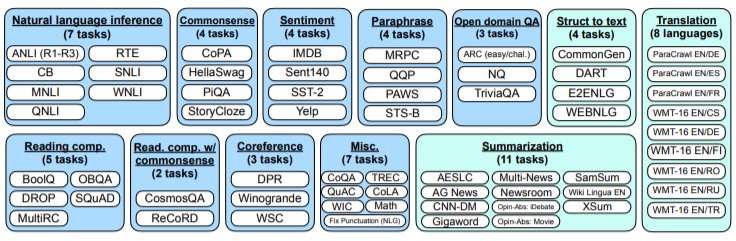
文章插图
我们将任务设定为由基于数据集转换的一组特定的输入-输出对(例如,我们认为RTE和ANLI是独立的任务,尽管它们的涵义有交叉)。
对于每一项任务,我们都会把它们组成十个不同的用自然语言指令来描述任务的模板。这十个模板中的大部分都描述了原始任务,但为了增加多样性,每个任务中最多包含三个 "反转任务 "的模板(例如,对于情感分类,我们包括要求生成负面电影评论的模板)。
然后,我们在所有任务的集合上对预训练的语言模型进行指令微调,每个任务中的例子都通过随机选择的指令模板进行格式化。图4展示了一个自然语言推理任务的多个指令模板。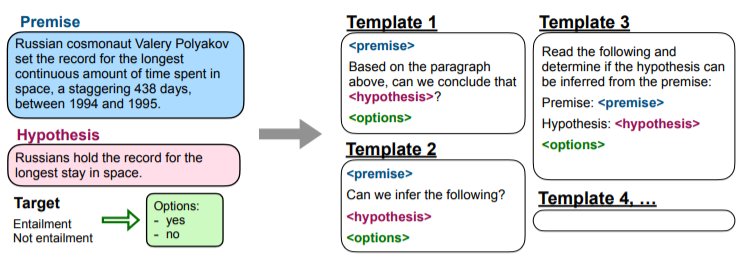
文章插图
2.2 评估分割法
我们对FLAN在指令微调中没有训练过的任务上的表现很感兴趣,因此,对未见过的任务的定义至关重要。
之前的一些工作通过不允许同一数据集出现在训练中来对未见过的任务进行分类,而我们利用图3中的任务集群,使用一个更为保守的定义。
在这项工作中,如果在指令微调期间没有训练过T所属的任何集群的任务,我们才认为任务T在评估时是合适的。例如,如果任务T是一个文本蕴涵任务,那么在指令微调数据集中不会出现文本蕴涵任务,我们只对所有其他集群的任务进行指令调整。
使用这个定义,为了评估FLAN在跨越c个集群的任务上的性能,我们执行了c个集群间分割的指令微调,在指令微调过程中,每种分割都会有不同的集群。
2.3 有选择的分类
一个给定任务所期望的输出空间是几个给定类别中的一个(如分类)或自由文本(如生成)。由于FLAN是纯解码器语言模型的指令微调版本,它自然可以生成自由文本,因此对于期望输出为自由文本的任务不需要再做进一步修改。
- 苹果|库克压力确实大,在众多国产厂家对标下,iPhone13迎来“真香价”!
- 京东正式上线“年礼无忧”服务
- 央视公开“支持”倪光南?柳传志该醒悟了
- 小米 11 Ultra 内测 NFC“读写勿扰”与“解锁后使用”功能
- 造车|苹果造车一波三折,缺了一家“富士康”
- 他是“中国氢弹之父”,他的名字曾绝密28年,他叫于敏
- iPhone|iphone14价格被曝!“胶囊”挖孔屏+三星4nm芯片,售价或5999起
- 36氪5G创新日报0112|福建省首个“5G+VR”英模会客厅正式上线;齐鲁医院健康管理中心“5G+ 5g
- 物联网|据说,物联网也可以称之为“一张想想的网络”,物联网世界是梦
- 部署|华为获欧洲大国力挺,5G部署有了新的可能