文章图片

文章图片
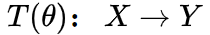
文章图片
文章图片
文章图片
文章图片
文章图片

监督学习|机器学习|
集成学习|进化计算|
非监督学习| 半监督学习|
自监督学习| 无监督学习|
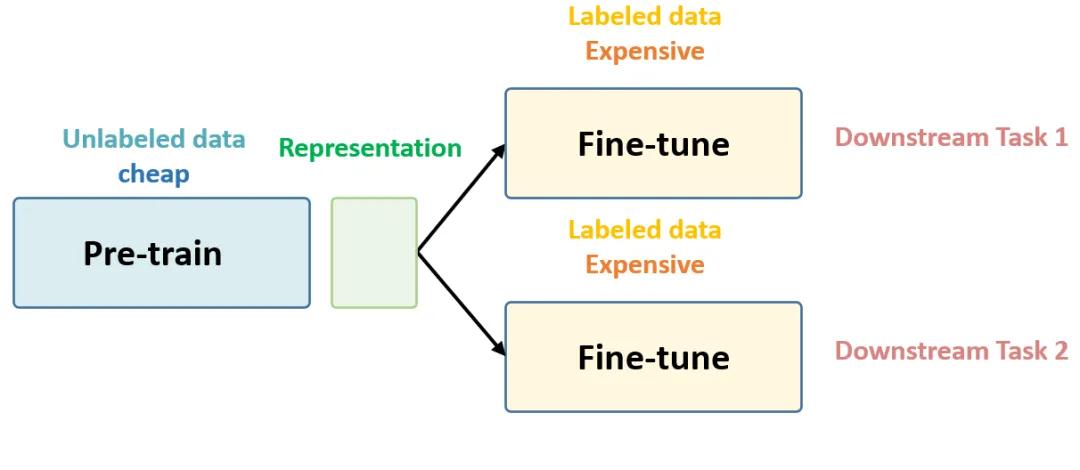
随着人工智能、元宇宙、数据安全、可信隐私用计算、大数据等领域的快速发展 , 自监督学习脱颖而出 , 致力于解决数据中心、云计算、人工智能和边缘计算等各个行业的问题 , 为人们带来极大便益 。
自监督学习是什么?
自监督学习与监督学习和非监督学习的关系
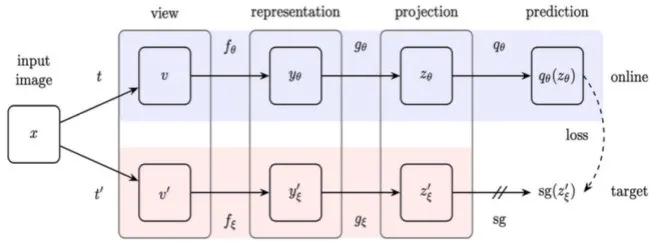
自我监督方法可以看作是一种特殊形式的具有监督形式的非监督学习方法 , 其中监督是通过自我监督任务而不是预设的先验知识诱发的 。 与完全不受监督的设置相比 , 自监督学习利用数据集本身的信息构造伪标签 。 在表达学习中 , 自我监督学习有很大的潜力取代完全监督学习 。 人类学习的本质告诉我们 , 大型标注数据集可能不是必需的 , 我们可以自发地从未标注的数据集中学习 。 更为现实的设置是使用少量带注释的数据进行自我学习 。 这就是所谓的Few-shot Learning 。
自监督学习的主要流派
在自监督学习中 , 如何自动获取伪标签非常重要 。 根据伪标签的不同类型 , 将自监督表示学习方法分为四种类型:
- 基于数据生成(恢复)的任务
- 基于数据变换的任务
- 基于多模态的任务
- 基于辅助信息的任务
所有非监督学习方法 , 如数据降维(PCA:在减少数据维度的同时最大化的保留原有数据的方差)和数据拟合分类(GMM:最大化高斯混合分布的似然) , 本质上都是为了得到一个好的数据表示 , 并希望能生成(恢复)原始输入 。 这也是目前很多自监督学习方法赖以使用的监督信息 。 基本上 , 所有的encoder-decoder模型都将数据恢复视为训练损失 。
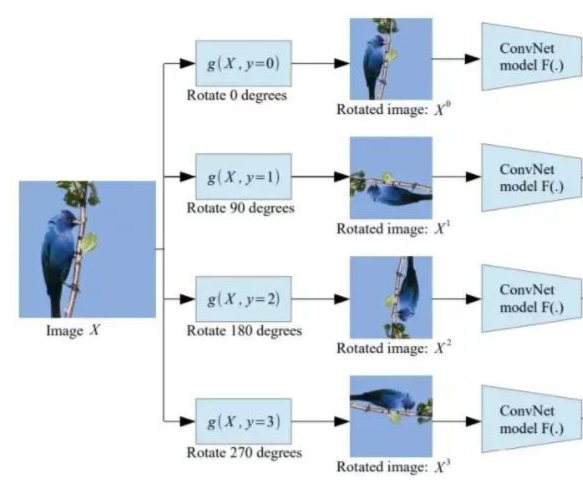
图片上色与视频预测什么是基于数据恢复的自监督任务?
一. 数据生成任务
自监督学习的出发点是考虑在缺少标签或者完全没有标签的情况下 , 我们仍然可以学习到能够表示原始图片的良好意义的特征 。 那么什么样的特质是良好有意义的呢?在第一类自监督任务——数据恢复任务中 , 能够通过学习到的特征来还原生成原始数据的特征是有良好意义的 。 看到这里 , 大家都能联想到自动编码器类的模型 , 甚至更简单的PCA 。 事实上 , 几乎所有的非监督学习方法都是基于这个原理 。 VAE现在非常流行的深代模式 , 甚至更热的GAN都可以归为这种方法 。
- 集度汽车机器人概念车曝光,售价20万元以上,北京车展将亮相!
- 关机|人工智能拓展机器人的能力和功能,推动了机器对人的脑力劳动的替代
- 企业创新评测实验室|含着“金汤匙”出身的海康机器人 启动分拆上市后 能否再造一个海康?| 物流
- 机器人|人工智能越来越先进,未来这些职业或被取代
- 本文转自:视界网1月20日下午|地面整平机器人亮相!为重庆江北机场T3B航站楼建设提速
- 机器人|四轴和六轴机器人的区别是什么,看了就知道!
- 智能生产力|从“酷”到“实用”,猎户星空服务机器人上岗10000+家客户变身智能生产力
- spring|宾得的色彩很好,一机一镜配置真的很值得,性价比很高
- 家长|80后奶爸做榜样陪娃学习、一次性通过法考:孩子成绩稳居班级后半段
- 本文转自:大众网目前|神兽归笼家庭辅导又发愁?碳氧智能硬件解放家长双手让学习更有效率