m自动驾驶系统竟被打上「思想钢印」?( 二 )
巨量数据涌进系统后,怎么处理?如何分类打标?怎么加快训练速度?验证测试是不是要在各种气候路况下重新跑一遍?
这些问题,成立刚满两年的毫末智行,悟了。
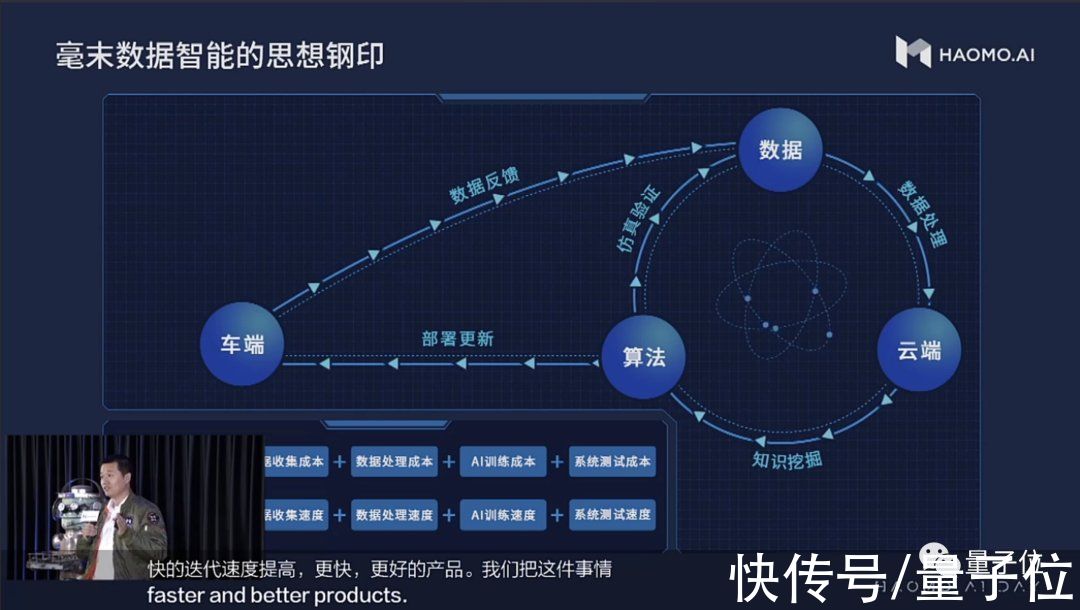
能让数据驱动真正形成闭环的条件不复杂,毫末把它们变成思想钢印,刻在自动驾驶研发之中。
文章插图
思想钢印命题只有一个,那就是:
研发、量产、落地,坚定低成本、高速度。
首先是低成本,包括数据收集、处理、AI模型训练、系统测试等环节。
其次是高速度,一一对应上面的各个环节。
其中,成本既有数据的传输、存储等人力财力成本,也有AI训练、测试时的时间成本。
不用说,成本越低当然数据获取就越多,模型迭代越快。
而高速度,则能保证巨量数据拿到手后紧紧有条按部就班,快速把数据优势转化成产品端的技术进步。
参透这两点,数据驱动才能爆发出巨大能量。
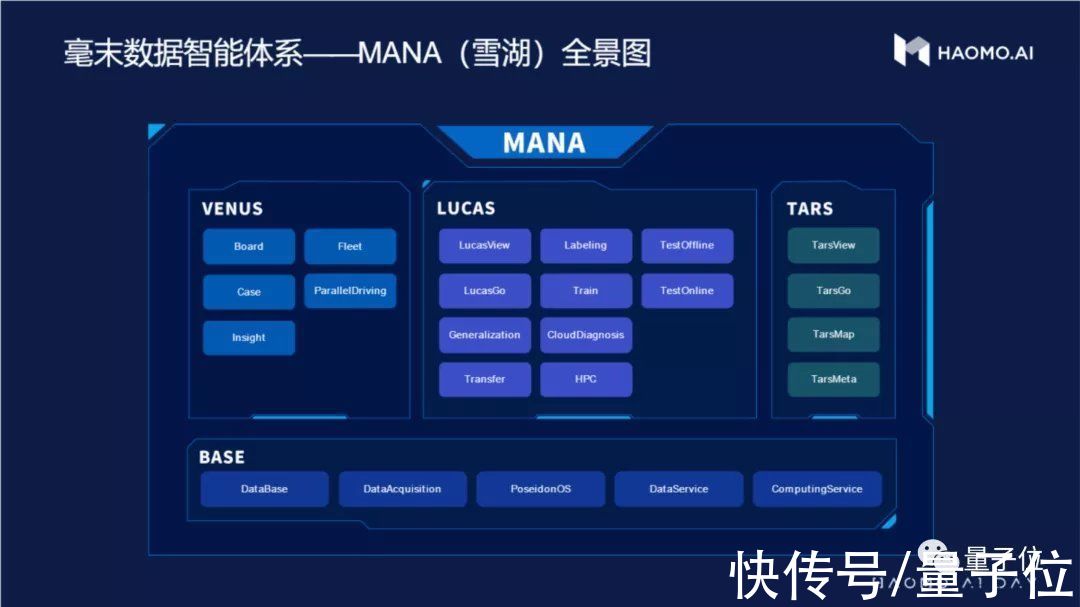
毫末智行建设的MANA数据智能体系,一切都是为这两个原则服务。
MANA包括了上面的所有思考点,由四个子系统组成:
文章插图
BASE包括了数据的获取,传输,存储,计算,以及新的数据分析和数据服务。
TARS是核心算法原型,用于感知、认知、车端建图、和验证的实践。
LUCAS则是对算法在应用场景上的实践,包括高性能计算、诊断、验证、转化等核心能力。
VENUS是数据可视化化系统,包括软件和算法的执行情况,对场景的还原,以及数据洞察等能力。
MANA不是一个软件,而是一个技术体系,其中包含众多子模块,它们一同构成了毫末智行的数据驱动能力,也是解释毫末业务飞速进展的关键。
MANA真的有魔力?从数据本身的视角,可能更好理解。
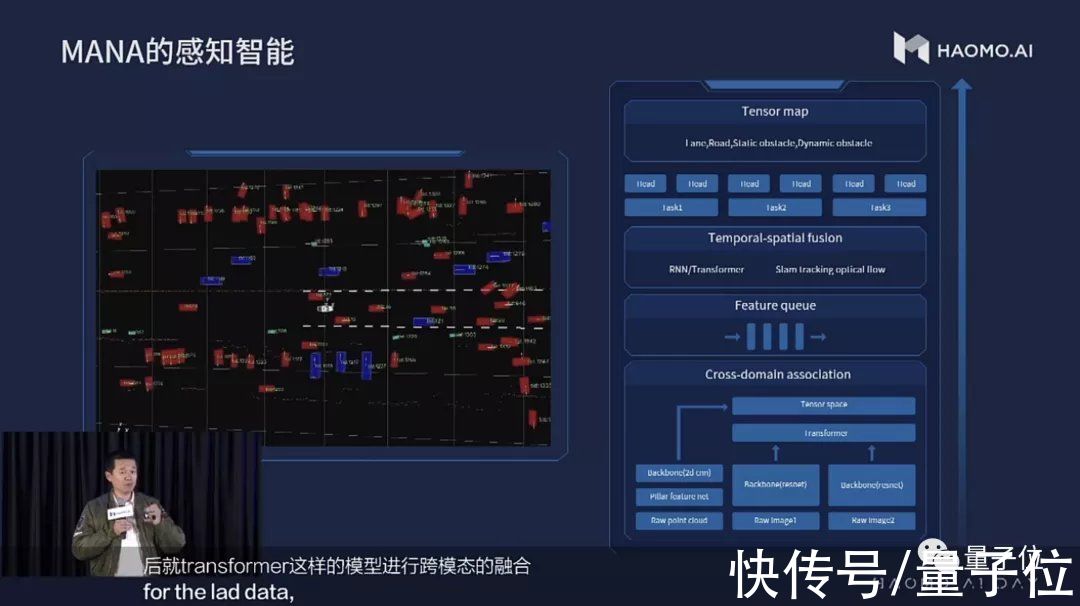
首先,数据要被感知到。毫末智行自动驾驶方案目前核心的感知设备,是摄像头和激光雷达。
采集到的数据,首先通过一个ResNet网络计算基础数据,然后生成两个分支,一个是计算目标特征的FPN网络,可以分别计算车道线、路基、车辆、信号灯等等目标信息。
文章插图
另一个分支则用于free space(可行驶区域)生成和场景识别。
对于激光雷达点云图,则用pointpillar算法,首先把点云数据降维进行伪二维化,之后再用一般图像的方法进行计算。
两种数据源,采取过程融合,加入时序的特征,实现感知能力快速提高,能够更准确的刻画现实世界。
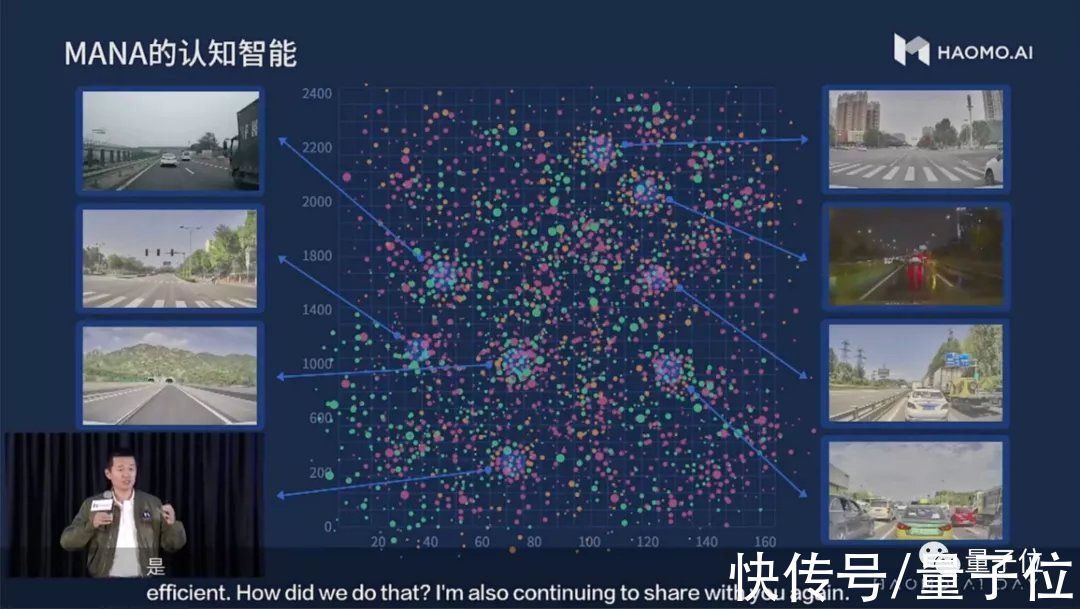
第二步,数据除了被感知,还要被系统认知,就是解决从客观世界到驾驶动作的映射。
文章插图
首先是表达特定场景下驾驶行为,可以从宏观上归纳出几个影响因素:天气、道路结构、交通参与者、交通流密度、彼此方位、主车路线、碰撞风险和碰撞时距。
然后从已有的数据中挖掘和表达这些属性,然后在进行聚类和分类,以找到更加舒适和高效的解决方案。
接着通过端到端模拟学习,以之前例子作为指导,得到具体的本车动作。
模拟学习,需要更大的数据样本,特别是标注好的数据,然后从数据中学习得到规律。
所以,问题关键就聚焦到到快速标注上。
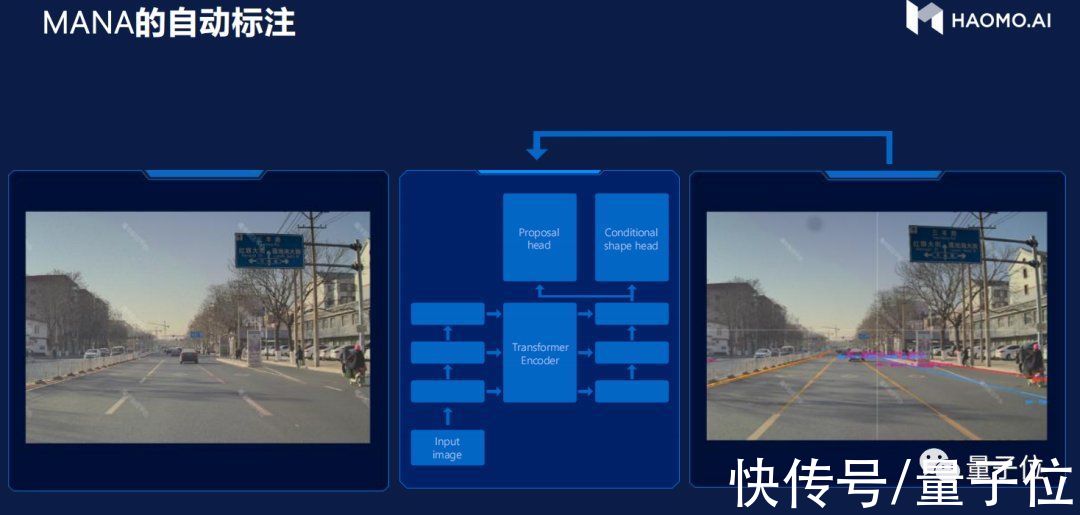
文章插图
Tesla积累20亿公里数据,累计标注了60亿个物体,包括精准的3D信息、深度、速度。
同样的数据量按相同标准进行人工标注,所付出的时间和资金,没有哪个自动驾驶公司能承担。
- 搜索引擎|淘宝运营系统出台春节打烊功能,淘宝运营商家该如何选择?
- 华为鸿蒙系统|华为偷偷上架新机,鸿蒙系统+5000mAh大电池,仅售1399元
- 物联网|?内容创作者:要明白文章首先是写给推荐系统看的!
- 观光巴士|无人驾驶观光巴士走进湖滨
- 资讯丨智能DHT+高阶智能驾驶辅助,魏牌开启“0焦虑智能电动”新赛道
- 荷兰|苹果公司向荷兰“妥协”:将开放交友软件的第三方支付系统
- 体验首款Linux消费级平板,原来芯片和系统全是国产
- 算力|不靠显卡!NVIDIA在中国焕发第二春:自动驾驶芯片被车厂爆买
- 自动驾驶|华为首秀自动驾驶,王兴:特斯拉遇到技术与忽悠能力相当的对手了
- 2.2亿花粉升级后,鸿蒙系统暴露出新问题,华为至今没有回应