研究人员|如何让人模仿猎豹走路?Stuart Russell提出基于最优传输的跨域模仿学习( 三 )
1. 当智能体域是专家域的刚性变换时,GWIL能否恢复最优行为?这是可以的,论文的作者们用迷宫证明了这一点。
2. 当智能体的状态和行动空间与专家不同时,GWIL能否恢复最优行为?这也是可以的,本篇论文中,作者们展示了倒立摆(cartpole)和钟摆(pendulum)之间轻微不同的状态-动作空间以及步行者(walker)和猎豹(cheetah)之间显著不同的空间。
为了回答这两个问题,研究人员使用了在 Mujoco 和 DeepMind 控制套件中实现的模拟连续控制任务。该学习策略的视频可在论文的项目网站上访问。在所有设置中,作者在dE和dA的专家和智能体空间中使用欧几里得度量。
学习策略地址:https://arnaudfickinger.github.io/gwil/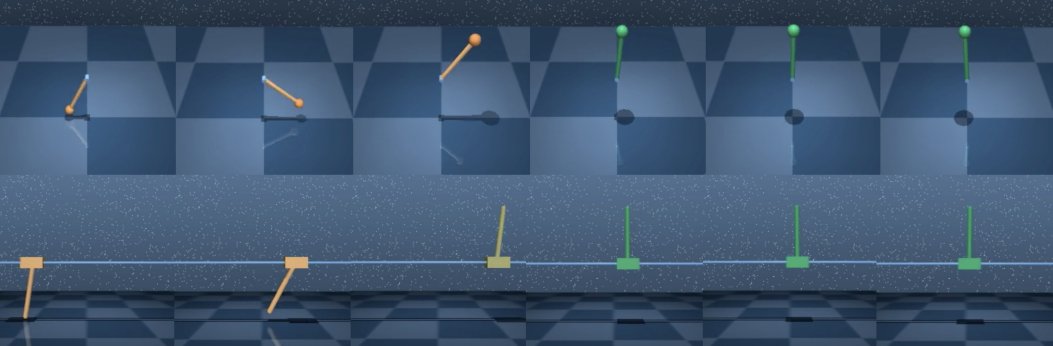
文章插图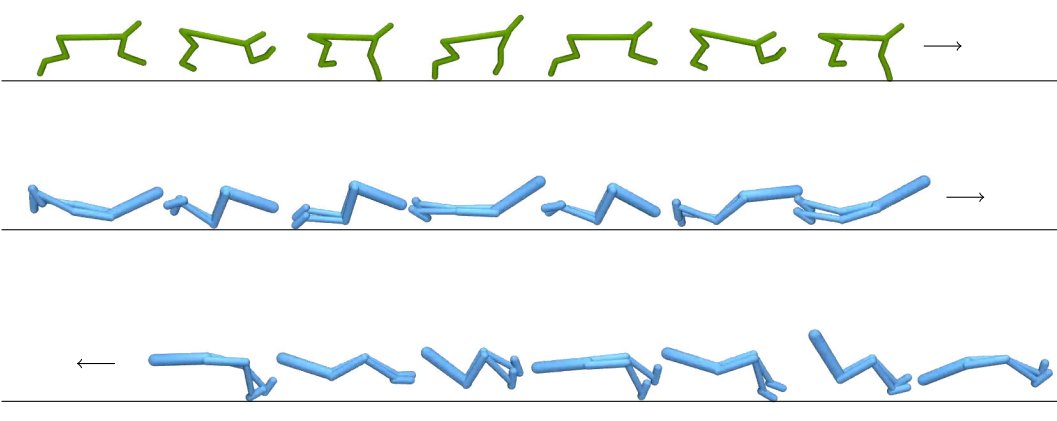
文章插图
文章插图
雷峰网
- 小米科技|不聊性能只谈拍照!新旗舰反向升级成潮流,拍照手机如何选?
- 搜索引擎|淘宝运营系统出台春节打烊功能,淘宝运营商家该如何选择?
- 小米科技|RTX3060的性能到底如何?相比RTX2060提升有多大?
- 市值超 1.7 万亿的Netflix是如何做决策的?
- 腾讯|前腾讯员工爆料:鹅厂的末位淘汰制让人心理崩溃!
- QQ音乐的2021专辑盘点,是如何征服资深乐迷的
- 饭饭1080°平台分析之生鲜电商平台如何选择ERP系统和SAAS系统
- 在2021大中华区艾菲国际论坛上|玛雅文化施葵:新消费时代,如何助力品牌跑出“破圈”加速度?
- 布局潮范多元化圈层 看MAZDA3昂克赛拉如何玩出花样?
- 原标题:月背工作满三年|月背工作三年 嫦娥四号如何做到超服期役?专家回应