零售|34页PPT全解CVPOS自助收银及商品识别算法工程落地方法( 五 )
–数据需求
对于数据上的需求,可以先选用公开数据集或网上的数据,对模型进行训练和对比,评判模型的可行性。在了解产品具体的场景后,将自己的业务数据回流,去迭代自身的模型,形成一个自制的数据集。自制数据集还有另一种方式是自己生成组合的数据集,但实践上这两个其实都有效的,但是数据闭环的方式是短期内提升精度最有效的方法。对于数据增强,有一部分是凭借自己的猜测,所以不能完全模拟真实的数据的分布,它的效率并没有数据闭环高。第四点是标注的成本,分成三种,人工、全自动和半自动,人工和全自动显然是不可以的。若为全自动,就证明你的模型是正确的,就不需要再训练。
折中选择半监督的标注方法,用比较好的预训练模型去做预标注,然后通过人工把置信度比较低的标签修正过来。数据标注成本的另一方面考量是,它会直接影响到最终模型的选择。由于现在选定的是一个目标检测,为什么不选分割任务?因为分割的标签非常难打,而目标检测只需要一个框,所以优先要考虑用目标检测的模型。选择打框标签也发现另一个问题,因为在同一张图上可能会出现多个类别,这样打起标也非常麻烦。所以,双模型的方式可以很好的解决这个问题,打标签的时候只需要关注框的位置,而并不需要再去选择到底是哪一个分类。
文章插图
下面介绍下我们的经验,一开始选用经验性能比较好的模型,然后在公开数据加上一点实验室数据,而实验室数据的产生如上图所示。左边两幅图是旷视在19年发布的一个商品的数据集-RPC,而我们的采集方式跟它类似,也是用各个摄像头的角度去拍摄商品,然后通过旋转的转盘把各个角度的信息录入,最后通过语义分割或实例分割,把他的掩膜mask给取出来之后,再进行商品的组合。
右图是在17年时做的一个组合,虽然没有RPC的阴影效果,但对于最终训练的作用是差不多的。最根本还是真实场景的问题。通过数据的训练,在实验室跑的成绩非常高,但放到了现场,下降30%是很正常的,从而证明了训练和测试的数据分布是不一致的。
–落地的困难
落地的困难有以下3点,第一,与benchmark相距甚远;第二,商品种类繁多,在不同商户之间利用率是非常低,标注困难等;第三,维护的频率非常高,需要有相当高的及时性。那针对上面的这三个要求做了一些改进。
–改进
首先,当然是数据闭环的问题,我们对环境做了一定的要求,限制场景,并开发采集工具及结果的错误检查工具,可以让现场的数据快速回流到模型的基础训练集里面,及时地更新学习。数据采集方面,直接放弃了实验室环境,直接开放给店员采集,用现场的数据。在采集的过程中,对于相同的商品,可以通过不同角度、方位,按照一定规则进行采集。如果有多家门店有相同的上新需求,可以把采集任务分配到各个门店,平均每一个门店的采集任务就降到比较低,基本没有增加额外的成本。对于标注,采用半监督检测标注,用一个比较好的预训练模型去做预标注,在通过人工的筛选,把置信度低的样本给调整过来。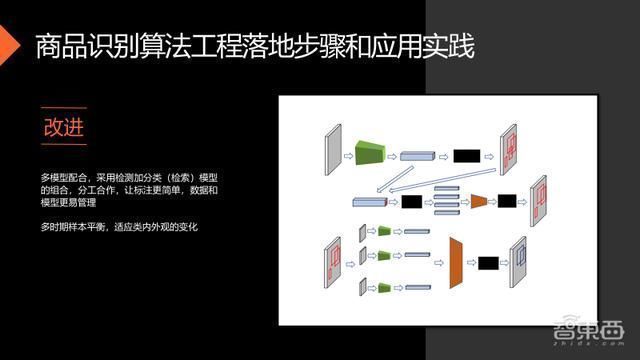
文章插图
第二个是多模型组合,上图有两个模型,一个是检测模型,另一个是分类模型,除了可以解耦合,让标注更简单,对数据模型更容易的管理以外,还可以解决目标检测上样本不平衡的状态,我们只需维护一组专门用来拟合检测模型的训练数据,其他的平衡的问题交给分类模型进行处理。
- 零售业|阿里再生独角兽,估值百亿美元,马云果然有远见
- 王中林|华为全球专利榜第四;京东海外开设机器人零售实体店;Oculus遭反垄断调查|科技周报
- 零售业|华为自研搜索引擎上线,无任何广告,无视百度,对标谷歌
- 纳米|2021年空调线上市场品牌零售排名出炉!米家进入前五
- 奥维云网(AVC)数据显示|2021年卡萨帝厨房零售增幅高达111.2%
- 灰度测试|干货分享︱线下零售新机遇——品牌私域化五步走
- “过了腊八就是年”|美岁趣集:零售生活再定义,启幕商业新图景
- 二线城市|每日优鲜,很难盈利
- 团购、零售双火爆,春节礼品市场现象级大单品来袭
- 汽车行业智能制造前沿观察「ppt」