零售|34页PPT全解CVPOS自助收银及商品识别算法工程落地方法( 三 )
商品识别算法落地的一般方法
在介绍经验教训之前,先介绍下算法的一般落地方法。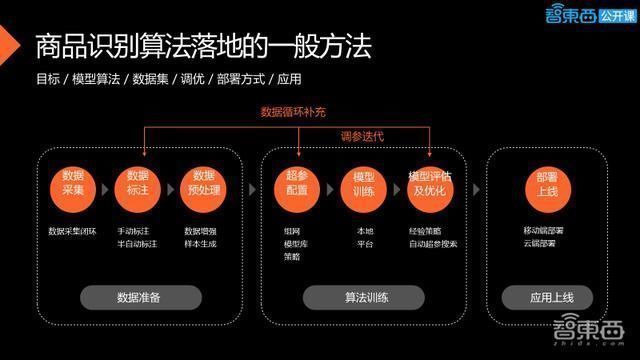
文章插图
现在优秀的开源算法已经很多了,如何让他们真正的助力自己的行业,成为产品的一部分,是需要方法论的。上图是经过实践总结出来的一些经验,首先要明确任务的目标,到底是一个CV的任务,还是一个NLP的任务?这比较明显,我们是一个CV的任务,但更重要的是要明确它的输出结果是一个绝对的决策,还是一个推荐的决策。绝对的决策要求他的精度是零容忍的,它的准确率绝对影响最终产品的性能,而推荐的决策只需要给出一个分数,让用户自己参考做决策。
显然CVPOS不是推荐式的决策,它对精度要求非常高,所以在第二步选择模型算法的步骤上,首先要根据精度的要求,再结合其他一些资源去挑选算法到底是用目标检测还是分割、分类,或是多种组合,用什么主干,选用什么网络架构,这些选择都需根据现场的需求决定。
第三步是数据准备,数据集刚开始可以用公开数据集,有助于去挑选合适的候选方案,随着业务场景成熟,不断引入业务数据,形成数据闭环,有助于快速提升模型精度。
对于标注,要选择是手工标注、全自动标注还是半自动标注?显然半自动标注是最符合真实的工程应用的。最后还有一些数据生成的问题,因为总会想不可能获得更多的数据,总希望模拟出更多的数据分布去拟合模型。但模拟方法从效果来讲,这种数据增强不及业务数据闭环来得显著。
数据挑选和数据集准备完之后,就是训练调优步的方面,用什么样的网络?有没有预训练的模型?优化的策略是怎样?训练是用开源框架,还是要自己搭建一个训练平台。因为到了后期真正接近产品时,其实是需要固化一些参数,这时开发一个相对自动化的平台工具进行模型的训练和输出,而不需要更多的调参,减少人工参与,是必要的。对于预训练模型,可以根据商品的特定形态选择训练模型。比如说像烘焙,他的外观极其相似的,我们可以专门做一个预训练模型,为后续的训练提速做准备。
通过调参训练,再回到真实场景的业务数据循环中,不断优化模型,当它的性能达到一定要求时,可以选择上线部署,部署根据具体需求,选择在云端还是前端部署,最后一定要关心在应用上线之后的整个运营的状况,在运营过程中搜索更多的真实问题,再把新需求回馈到整个模型开发的流程当中,对模型进行更好的迭代。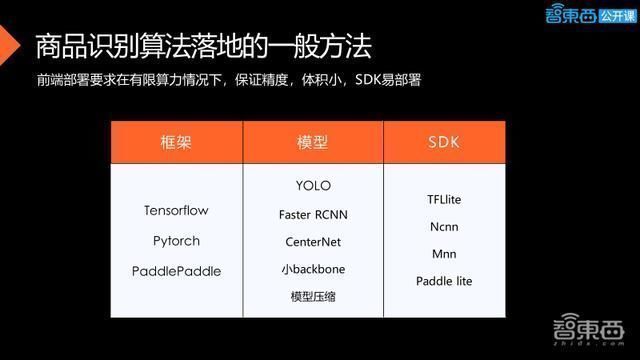
文章插图
上图是前端部署所需的一些工具以及模型,对于框架,基本上都是一些成熟的框架,而且他们的公开资源会比较多,方便大家去做实验研究。对于模型,我们以目标检测为例,会有一些带锚框的模型,还有不带锚框的模型,要根据真实场景去做决定。因为这是一个前端部署,我们尽量选用一些小的backbone,再配合一些模型压缩技术。在前端部署方面,有类似于TFLite、Ncnn的前端的架构。现在选用的主要是国内大厂的开源的架构,因为它们会对国内经常使用的芯片,有一些定制化的处理,而且工具链也比较完善。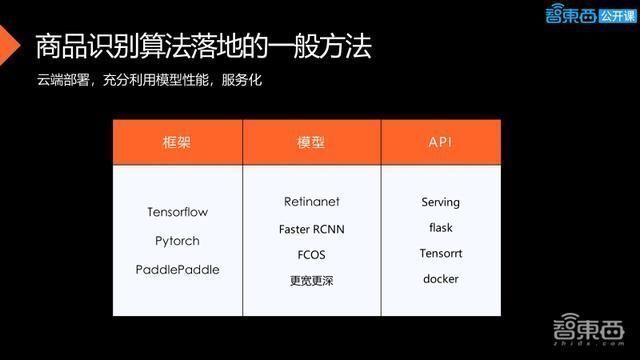
文章插图
上图是云端部署的罗列,框架是一致的,因为要充分利用模型的性能,就少一点考虑模型的小型化,可以用一些更深、更宽、准度更高的网络,也不是不做优化,因为在云端部署大部分使用的GPU是英伟达GPU,可以用TensoeRT去做优化,在正常情况下可以达到三倍左右的性能增益。API的部署可能会用到一些框架下自带的Serving功能,或自己开发一些API的接口。
- 零售业|阿里再生独角兽,估值百亿美元,马云果然有远见
- 王中林|华为全球专利榜第四;京东海外开设机器人零售实体店;Oculus遭反垄断调查|科技周报
- 零售业|华为自研搜索引擎上线,无任何广告,无视百度,对标谷歌
- 纳米|2021年空调线上市场品牌零售排名出炉!米家进入前五
- 奥维云网(AVC)数据显示|2021年卡萨帝厨房零售增幅高达111.2%
- 灰度测试|干货分享︱线下零售新机遇——品牌私域化五步走
- “过了腊八就是年”|美岁趣集:零售生活再定义,启幕商业新图景
- 二线城市|每日优鲜,很难盈利
- 团购、零售双火爆,春节礼品市场现象级大单品来袭
- 汽车行业智能制造前沿观察「ppt」