金榕|?阿里达摩院金榕:从技术到科学,中国 AI 将何去何从?( 二 )
以自动驾驶为例,美国卡耐基梅隆大学的研究人员进行的Alvinn项目,在80年代末已经开始用神经网络来实现自动驾驶,1995年成功自东向西穿越美国,历时7天,行驶近3000英里。在下棋方面,1992年IBM研究人员开发的TD-Gammon,和AlphaZero相似,能够自我学习和强化,达到了双陆棋领域的大师水平。
文章插图
(1995年穿越美国项目开始之前的团队合照)
不过,由于数据和算力的限制,这些研究只是点状发生,没有形成规模,自然也没有引起大众的广泛讨论。今天由于商业的普及、算力的增强、数据的方便获取、应用门槛的降低,AI开始触手可及。
但核心思想并没有根本性的变化。我们都是试图用有限样本来实现函数近似从而描述这个世界,有一个input,再有一个output,我们把AI的学习过程想象成一个函数的近似过程,包括我们的整个算法及训练过程,如梯度下降、梯度回传等。
同样的,核心问题也没有得到有效解决。90年代学界就在问的核心问题,迄今都未得到回答,他们都和神经网络、深度学习密切相关。比如非凸函数的优化问题,它得到的解很可能是局部最优解,并非全局最优,训练时可能都无法收敛,有限数据还会带来泛化不足的问题。我们会不会被这个解带偏了,忽视了更多的可能性?
毋庸讳言,以深度学习为代表的 AI 研究这几年取得了诸多令人赞叹的进步,比如在复杂网络的训练方面,产生了两个特别成功的网络结构,CNN和transformer。基于深度学习,AI研究者在语音、语义、视觉等各个领域都实现了快速的发展,解决了诸多现实难题,实现了巨大的社会价值。
但回过头来看深度学习的发展,不得不感慨 AI 从业者非常幸运。
首先是随机梯度下降(SGD),极大推动了深度学习的发展。随机梯度下降其实是一个很简单的方法,具有较大局限性,在优化里面属于收敛较慢的方法,但它偏偏在深度网络中表现很好,而且还是出奇的好。为什么会这么好?迄今研究者都没有完美的答案。类似这样难以理解的好运气还包括残差网络、知识蒸馏、Batch Normalization、Warmup、Label Smoothing、Gradient Clip、Layer Scaling…尤其是有些还具有超强的泛化能力,能用在多个场景中。
再者,在机器学习里,研究者一直在警惕过拟合(overfitting)的问题。当参数特别多时,一条曲线能够把所有的点都拟合得特别好,它大概率存在问题,但在深度学习里面这似乎不再成为一个问题…
虽然有很多研究者对此进行了探讨,但目前还有没有明确答案。更加令人惊讶的是,我们即使给数据一个随机的标签,它也可以完美拟合(请见下图红色曲线),最后得出拟合误差为0。如果按照标准理论来说,这意味着这个模型没有任何偏差(bias),能帮我们解释任何结果。请想想看,任何东西都能解释的模型,真的可靠吗,包治百病的良药可信吗?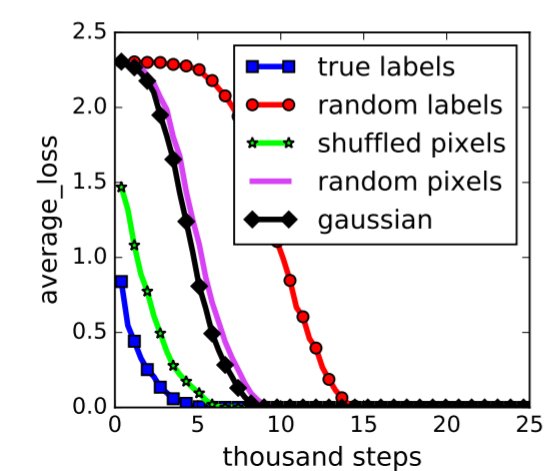
文章插图
(Understanding deep learning requires rethinking generalization. ICLR, 2017.)
说到这里,让我们整体回顾下机器学习的发展历程,才能更好理解当下的深度学习。
机器学习有几波发展浪潮,在上世纪80年代到90年代,首先是基于规则(rule based)。从90年代到2000年代,以神经网络为主,大家发现神经网络可以做一些不错的事情,但是它有许多基础的问题没回答。所以2000年代以后,有一批人尝试去解决这些基础问题,最有名的叫SVM(support vector machine),一批数学背景出身的研究者集中去理解机器学习的过程,学习最基础的数学问题,如何更好实现函数的近似,如何保证快速收敛,如何保证它的泛化性?
- 酷睿处理器|关键数据出炉,京东比阿里差远了
- CPU|阿里反贪第一人蒋芳,入职23年将7名高层送入狱,连马云都可以查
- 阿里巴巴|社区团购是互联网巨头的宝地,美团拼多多发展强劲,阿里坐不住了
- 阿里巴巴|被苹果无辜“踢出局”,引发央视点名,国产制造该何去何从?
- 零售业|阿里再生独角兽,估值百亿美元,马云果然有远见
- MIUI|数字人民币APP正式上线,扯下了阿里的“遮羞布”
- meta|阿里云到底有多强大?一起来盘点一下它骄人的战绩
- 阿里巴巴|一块桌面版3070显卡的价格,就够买一个3070笔记本,还能剩点
- 政企|AWS、阿里云、Azure 云计算三巨头的“混战”
- 阿里巴巴|阿里员工黄土高原养猪记:给猪装上计步器,每天跑够2万步