人们可以争辩说,有了足够的例子,一个系统可以确立统计学意义。但是,需要多少个示例来"学习"如何解决结构中的引用(如 (1)中的引用)?在机器学习/数据驱动的方法中,没有类型层次结构,我们可以对"包"、"手提箱"、"公文包"等进行概括性陈述,所有这些声明都被视为通用类型"容器"的子类型。因此,以上每个模式,在纯数据驱动的范式中,都是不同的,必须在数据中分别"看到"。如果我们在语义差异中加入上述模式的所有小语法差异(例如将"因为"更改为"虽然",这也更改了"它"的正确引用),那么粗略计算告诉我们,机器学习/数据驱动系统需要看到上述 40000000 个变体,以学习如何解决句子中的引用。如果有的话,这在计算上是不可信的。正如Fodor和Pylyshyn曾经引用著名的认知科学家乔治.米勒( George Miller),为了捕捉 NLU 系统所需的所有句法和语义变化,神经网络可能需要的特征数量超过宇宙中的原子数量!这里的寓意是:统计无法捕捉(甚至不能近似)语义。逻辑学家们长期以来一直在研究一种语义概念,试图用语义三角形解释什么是"内涵"。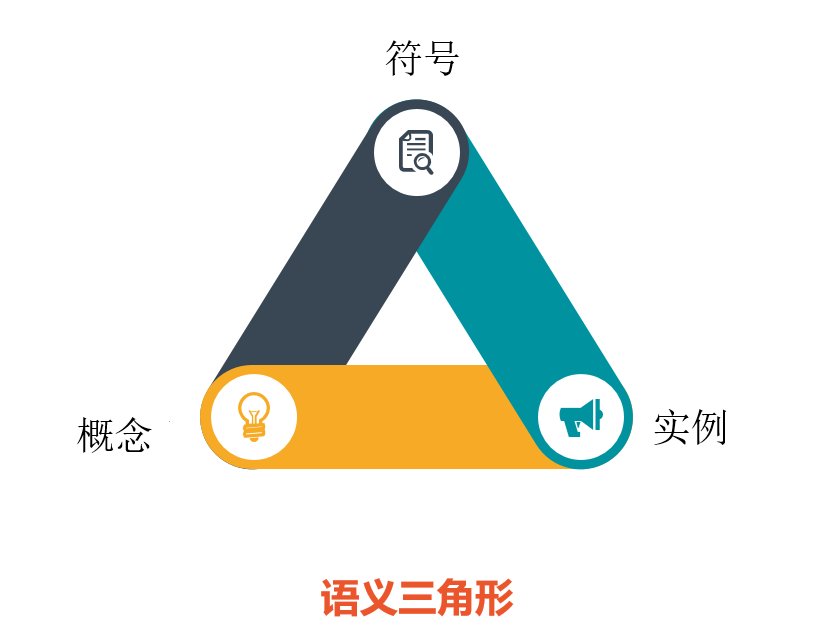
文章插图
一个符号用来指代一个概念,概念可能有实际的对象作为实例,但有些概念没有实例,例如,神话中的独角兽只是一个概念,没有实际的实例独角兽。类似地,"被取消的旅行"是对实际未发生的事件的引用,或从未存在的事件等。因此,每个"事物"(或认知的每一个对象)都有三个部分:一个符号,符号所指的概念以及概念具有的具体实例。我有时说,因为概念"独角兽"没有"实际"实例。概念本身是其所有潜在实例的理想化模板(因此它接近理想化形式柏拉图)一个概念(通常由某个符号/标签所指)是由一组属性和属性定义,也许还有额外的公理和既定事实等。然而,概念与实际(不完美)实例不同,在数学世界中也是如此。因此,例如,虽然下面的算术表达式都有相同的扩展,但它们有不同的语气:内涵决定外延,但外延本身并不能完全代表概念。上述对象仅在一个属性上相等,即它们的值在许多其他属性上是不同的。在语言中,平等和同一性不能混淆,如果对象在某些属性值中是平等的,则不能认为对象是相同的。
文章插图
因此,虽然所有的表达式评估相同,因此在某种意义上是相等的,但这只是它们的属性之一。事实上,上述表达式有几个其他属性,例如它们的语法结构、操作员数量、操作次数等。价值(这只是一个属性)称为外延,而所有属性的集合是内涵。虽然在应用科学(工程,经济学等),我们可以安全地认为它们相等仅属性,在认知中(尤其是在语言理解中),这种平等是失败的!下面是一个简单的示例:假设(1)是真的,即假设(1)真的发生了,我们看到了/ 见证了它。不过,这并不意味着我们可以假设(2)是真的,尽管我们所做的只是将 (1) 中的 '1b' 替换为一个(假设)等于它的值。所以发生了什么事?我们在真实陈述中用一个被认为与之相等的对象替换了一个对象,我们从真实的东西中推断出并非如此的东西!虽然在物理科学中,我们可以很容易地用一个属性来替换一个等于它的物体,但这在认知上是行不通的!下面是另一个可能与语言更相关的示例: