语言|NLP≠NLU,机器学习无法理解人类语言( 三 )
虽然 NLP(自然语言处理)和 NLU(自然语言理解)经常互换使用,但两者之间存在巨大差异。事实上,认识到它们之间的技术差异将使我们认识到数据驱动的机器学习方法。虽然机器学习可能适合某些 NLP 任务,但它们几乎与 NLU 无关。
考虑最常见的"下游 NLP"任务:
综述--主题提取--命名实体识别(NER)--(语义)搜索--自动标记--聚类
上述所有任务都符合所有机器学习方法的基础可能大致正确(PAC) 范式。具体来说,评估一些NLP系统在上述任务的性能是相对主观的,没有客观标准来判断某些系统提取的主题是否优于另一个主题。
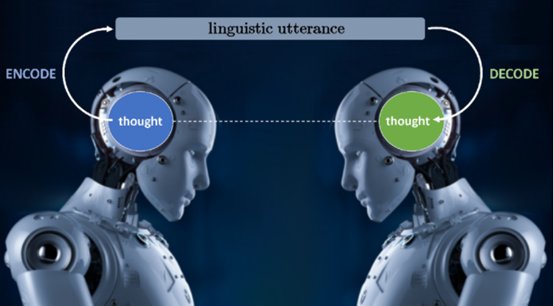
然而,语言理解不承认任何程度的误差,它们要充分理解一个话语或一个问题。
文章插图
举个例子,针对这句话,自然语言理解就需要考虑多种可能:我们有一个退休的BBC采访人员,曾在冷战期间驻扎在一个东欧国家吗?
某些数据库对上述查询将只有一个正确的答案。因此,将上述内容转换为正式的结构化查询语言查询是巨大的挑战,因为我们不能搞错任何错误。
这个问题背后的"确切"思想涉及:
正确解释"退休的BBC采访人员"——即作为所有在BBC工作的采访人员,现在退休了。 通过保留那些在某个"东欧国家"工作的"退休BBC采访人员",进一步过滤上述内容。
以上意味着将介词短语为"在冷战期间",而不是"一个东欧国家"(如果"冷战期间"被替换为"具有华沙成员资格",就要考虑不同的介词短语') 做正确的量化范围:我们正在寻找的不是在 "一些" 东欧国家工作的采访人员, 而是“任何”在“任何”东欧国家工作的采访人员。
文章插图
- c语言|e观沧海丨算法焉能藏“算计”
- 电子商务|如何新建c语言项目
- 算法|可以跳过 Objective-C 然后直接学习 Swift 语言吗?
- 《幽灵线:东京》中国台湾评级15+ 含暴力、不当语言
- 双十一|如何新建c语言项目
- AMD|Python语言命令行参数解析接收参数执行脚本的三种方法
- 当当网|Python语言命令行参数解析接收参数执行脚本的三种方法
- 语言识别|AI技术,让我们“听”懂聋人
- 编程|华为发布仓颉编程语言,打破国外编程霸权,让中国人用汉字编程
- c语言|C语言-浅谈include命令