语言|NLP≠NLU,机器学习无法理解人类语言

文章插图
编译 | 吴彤
校对 | 青暮
编辑 | 琰琰
长期以来,我们一直在与机器沟通:编写代码--创建程序--执行任务。
然而,这些程序并非是用人类“自然语言“编写的,像Java、Python、C和C ++语言,始终考虑的是"机器能够轻松理解和处理吗?"
“自然语言处理”(Natural Language Processing,NLP)的目的与此相反,它不是以人类顺应机器的方式学习与它们沟通,而是使机器具备智力,学习人类的交流方式。其意义更为重大,因为技术的目的本来就是让我们生活得更轻松。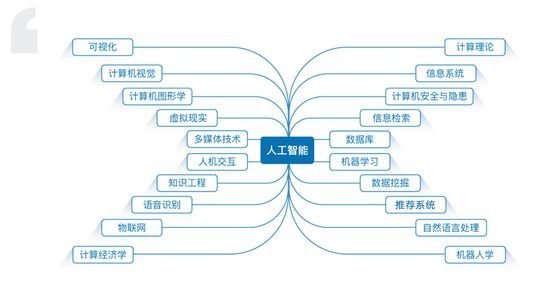
文章插图
人工智能与子领域
自然语言处理,实际上是人工智能和语言学的交叉领域,但多年来,仅在语音转录、语音命令执行、语音关键词提取的工作上兢兢业业,规规矩矩,应用到人机交互,就显得十分吃力。
文章插图
因为在语料预处理阶段,NLP通常直接给出“断句”,比如 "订一张明天从北京到杭州的机票,国航头等舱",经过NLP模型处理后,机器给出的输出如下:
文章插图
尽管准确率高,但在这背后,我们并不知道机器理解了什么。由于足够好用,人们也就不多问了。
而在更加复杂的任务中,比如机器翻译,基于深度学习的编码、解码架构会将原句子转换成我们根本不熟悉的样子,也就是在无穷维空间中的点。
一旦机器翻译出错,我们打开这个空间的时候,才发现这些点和周围其他点(其他句子)构成的形态,犹如荒芜宇宙里零落的星星那样缥缈和神秘。
文章插图
研究人员试图向神经网络添加参数以提高它们在语言任务上的表现,然而,语言理解的根本问题是“理解词语和句子下隐藏的含义“。
近日,伦斯勒理工学院的两位科学家撰写了一本名为《人工智能时代语言学》的书,探讨了目前的人工智能学习方法在自然语言理解(Natural Language Understanding,NLU)中的瓶颈,并尝试探索更先进的智能体的途径。
文章插图
机器学习模型是一种知识精益系统,它试图通过统计词语映射来回答上下文关系。在这些模型中,上下文是由词语序列之间的统计关系形成的,而非词语背后的含义。自然,数据集越大、示例越多样化,机器对上下文关系的理解越精确。
但作者认为,机器学习终将失宠,因为它们需要太多的算力和数据来自动设计特征、创建词汇结构和本体,以及开发将所有这些部分结合在一起的软件系统。而且,机器人也不知道自己在做什么,以及为什么这样做。它们解决问题的方法不像人类--不依赖与世界、语言或自身的互动。因此,它们无法理解两个人长时间对话时,对同一件事情的描述越来越简短的情景,也就是文本缺失现象。
巨大人工成本使机器学习陷入瓶颈,并迫使人们寻求其他方法来处理自然语言, 并导致了自然语言处理中经验主义范式(认为语言理解起源于感觉)的出现。
具有“感觉”的人工智能,或许会在自然语言处理上有三个突破:
- c语言|e观沧海丨算法焉能藏“算计”
- 电子商务|如何新建c语言项目
- 算法|可以跳过 Objective-C 然后直接学习 Swift 语言吗?
- 《幽灵线:东京》中国台湾评级15+ 含暴力、不当语言
- 双十一|如何新建c语言项目
- AMD|Python语言命令行参数解析接收参数执行脚本的三种方法
- 当当网|Python语言命令行参数解析接收参数执行脚本的三种方法
- 语言识别|AI技术,让我们“听”懂聋人
- 编程|华为发布仓颉编程语言,打破国外编程霸权,让中国人用汉字编程
- c语言|C语言-浅谈include命令