文章图片
Feed流的概念对很多人来说都很陌生 , 但在移动互联网时代几乎每个人的工作生活都离不开它 。 通俗讲 , 它就是一种普遍应用于各类社交和内容资讯类app , 主攻信息、内容的聚合和推送的互联网服务方式 。 它能将你最感兴趣并且长期关注的内容推送给你 , 成为“最懂你”的信息助手 。 同时 , 基于智能化的自动聚合、精准推送信息的功能 , 它也成为了今天商户投放广告和实现更佳营销效果的重要渠道 。
依托于出色的个性化应用体验 , Feed流服务的用户数量和使用频度都在与日俱增 , 用户对其内容推送的精准度、时效性等需求也在随之不断提升 , 这就对支撑Feed流服务的平台性能、尤其是数据库性能构成了严峻的挑战 , 即便是相关领域的老牌玩家、身为全球 IT 和互联网行业的领先企业的百度 , 也需要对其进行持续的优化和革新 。
“成长的烦恼” , 百度Feed流服务撞上“内存墙”
此前 , 大家在提及IT平台性能时 , 如果没有特指 , 基本都是对应其主要算力单元的性能表现 , 但为什么在Feed流服务中 , 数据库性能也会如此关键?
这一点 , 其实是由Feed流服务的本质及架构决定的 , 正如上文所说 , 它的主要功用就是要对各种信息和内容进行自动聚合和精准推送 , 而所有这些信息和内容都会以海量数据的型态在Feed流服务背后的数据库中进行存储 , 还需要进行尽可能高效地访问和处理 , 惟其如此才能实现迅捷和精准的推送结果 。
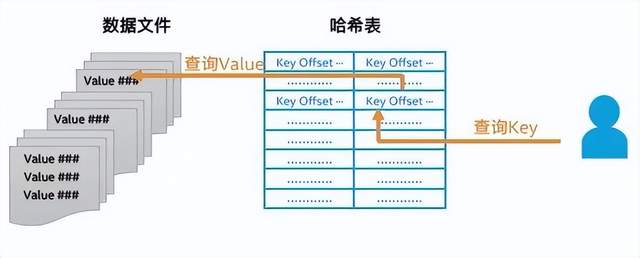
图一、百度Feed-Cube示意图
因此不论是哪家企业的Feed流服务 , 它们基本都是围绕背后的核心数据库构建起来的 。 百度也是如此 , 它早在数年前就构建了Feed流服务所需的数据库Feed-Cube 。 而且从自身的业务状况出发 , 为满足数以亿计的用户规模、千万量级的并发服务 , 以及更低时延的数据处理性能 , 百度还在Feed-Cube构建之初就把它打造成了一个内存数据库 , 并采用了KV(Key- Value , 键值对)的存储结构 。 在这个结构中 ,Key值 , 以及Value值所在数据文件的存储偏移值都存放在哈希表中 , 而Value值则单独存放在不同的数据文件中 。 此外 , 所有哈希表和数据文件均存放在内存中 , 从而能充分借助内存的高速I/O能力来提供出色的读写性能和超低时延 。
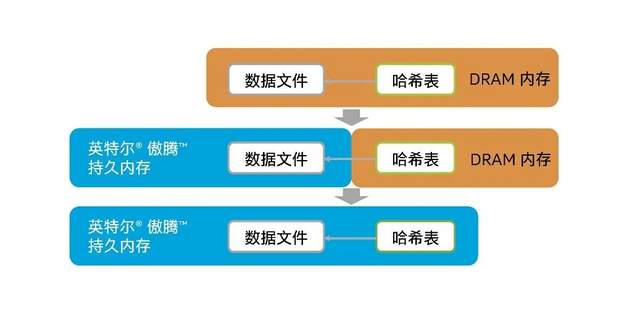
尽管拥有如此前瞻的架构设计 , Feed- Cube还是会遇到挑战——虽然在每秒千万次查询的高并发和PB级海量数据存储环境下它的表现一直优异 , 但在百度Feed流服务规模持续扩展、数据规模也持续增长的情况下 , 它还是遇到了内存容量扩展跟不上数据存储需求发展的问题 , 或者说 , 撞上了“内存墙”的考验 。
内存墙这个词 , 原本是用以描述内存与算力单元之间的技术发展差距所导致的性能瓶颈 , 而在大数据和AI时代数据处理需求更多走向实时化后 , 它也增添了容量层面的含义 , 即用户为了尽可能提升数据读写和处理的效率 , 不得不将更大体量的数据从存储中移到距算力更近、带宽和I/O性能更优的内存中 , 但内存容量扩展不易和成本过高的问题 , 却使得它难以承载更大体量的数据 , 这种情形 , 就像是内存在容量上也有了一层看不见摸不着 , 但又实实在在存在的围墙 。
如果要问为何内存容量扩展难 , 成本也高?那就要谈到DRAM身上 。 作为目前内存普遍使用的介质 , DRAM在单条服务器内存上的主流容量配置多是32GB或64GB , 128GB少见且价格昂贵 , 任何人如果想使用DRAM内存来大幅扩展内存容量 , 那么就必须承担非常高昂的成本 , 而且花了大钱 , 最终可能还是难以实现自己想要达到的内存容量水准 。
- 安卓|负优化?三星手机应用更新 删除货币汇率转换功能引网友不满
- 要上市的威马 依然给不了百度信心
- 医美|造车潮趋于理性化,吉利抽身集度,百度单干?
- ColorOS|7月第一份喜讯,多款OPPO机型上榜安兔兔,离不开ColorOS深度优化
- AMD|Intel Arc显卡跑分优化功能被禁用:能跟AMD/NV公平竞争了
- 百度|吉利没撤资但已放手,百度实控下的集度仍难逃动荡?
- ColorOS|揭秘流畅度与杀后台优化秘诀!ColorOS 13新方案雏形已现
- ColorOS|ColorOS神优化,为OPPO手机性能夺冠送助攻,这些分析有理有据
- 拼多多|电霸(店霸):拼多多如何优化人群定位
- 百度地图简洁版!功能简单无广告,比原版好用n倍