
文章图片
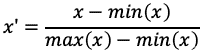
文章图片

文章图片
数据的归一化是数据预处理中重要的的一步 , 很多种方法都可以被称作数据的归一化 , 例如简单的去除小数位 , 而更高级归一化技术才能对我们训练有所帮助 , 例如 z-score 归一化 。
所以本文总结了 7 种常见的数据标准化(归一化)的方法 。
- Decimal place normalization
- Data type normalization
- Formatting normalization (date abbreviations date order & deliminators)
- Z-Score normalization
- Linear normalization (“Max-Min”)
- Clipping normalization
- Standard Deviation Normalization
Data type normalization , 数据类型归一化另一种常见是对数据类型的归一化 。 在 Excel 或 SQL 查询数据库中构建数据表时 , 可能会发现自己查看的数字数据有时被识别为货币 , 有时被识别为文本 , 有时被识别为数字 , 有时被识别为逗号分割的字符串 。
问题是这些数值数据对公式和各种分析处理的操作是不一样的 。 所以就需要将它们统一成相同的类型 。。
Formatting normalization , 格式的归一化【算法|7种不同的数据标准化(归一化)方法总结】最后一个简单的技术是格式的归一化 。这对于字符串(文本)是很常见的 , 并且在印刷和打印方向上出现的更多 。 虽然这些问题不会对分析产生影响 , 但是他可能会分散我们的注意力和现实的效果 , 例如斜体、粗体或下划线或者字体与其他的文字显示不一样 。
Z-Score normalization当我们的数据在多个维度上存在显著的大小差的数值时怎么办?例如 , 如果一个维度的值从 10 到 100 , 而另一个维度的值从 100 到 100000 , 则很难比较两者的相对变化 。
对于这个问题 , 目前最好的解决方案就是归一化 。 在日常工作中 , 最常见的归一化类型是 Z-Score。简单来说 , Z-Score 将数据按比例缩放使之落入一个特定区间 。公式如下:
其中 X 是数据值 , μ 是数据集的平均值 , σ 是标准差 。
Linear normalization (“Max-Min”)线性归一化可以说是更容易且更灵活的归一化技术 。它通常被称为“max-min”归一化 , 它允许分析人员获取集合中最大 x 值和最小 x 值之间的差值 , 并建立一个基数 。
这是一个很好的开始策略 , 实际上 , 线性归一化可以将数据点归一化为任何基数 。下是线性归一化的公式:
假设“x”值为 20 , 最大数字为 55 , 最小数字为 5 。 为了归一化这个数字 , 让我们从分母开始 , 结果为50 (55-5)。现在用同样的想法计算分子:x - min=15 (20–5) 。所以我们标准化的 x 或 x ' 是 15/50 = 0.3 。
Clipping normalization , 剪裁归一化裁剪并不完全是一种归一化技术 , 他其实是在使用归一化技术之前或之后使用的一个操作 。简而言之 , 裁剪包括为数据集建立最大值和最小值 , 并将异常值重新限定为这个新的最大值或最小值 。
- vivo|vivo手机XSTY四个系列咋选,从出众的到你买的各有不同
- 红米手机|红米K50和realmeGT大师探索版,哪一个值得买?他们有什么不同?
- boss直聘|算法 | Java 常见排序算法(纯代码)
- 任正非|任正非的观点跟司马南不同,你为谁点赞?
- 腾讯|国家出手,人民日报正式发声,“算法时代”即将落幕?
- 音箱|落地音箱低音扬声器和低音炮的扬声器有啥不同
- 日前|amd发布fsr2.0:4种不同采样模式
- 天文学|银河系历经不同演化阶段
- |不同射频电缆的优缺点
- 红米手机|红米k40和k40pro有什么不同?看完后就知道千元差距选哪款更合适