威斯康星大学麦迪逊分校|ICLR 2022:AI如何识别“没见过的东西”?
行早 发自 凹非寺
量子位 | 公众号 QbitAI
这回域外物体检测方向出了一个新模型VOS,合作团队来自威斯康星大学麦迪逊分校,论文已收录到ICLR 2022中。
这一模型在目标检测和图像分类上均达到目前最佳性能,FPR95指标比之前最好的效果还降低了7.87%之多。
要知道深度网络对未知情况的处理一直是个难题。
例如在自动驾驶中,识别已知物体(例如汽车、停车标志)的检测模型经常“指鹿为马”,对域外物体(OOD)会产生高置信度的预测。
就像下图中的一头驼鹿,在Faster-RCNN模型下被识别成了行人,还有89%的置信度。

文章插图
因此域外物体的检测无疑成为了AI安全方面一个很重要的话题。
我们来看看这个模型是怎么对域外物体做出判断的。
VOS如何检测域外物体在理解VOS之前,不得不提一下域外物体检测困难的原因。
其实也很好理解,毕竟神经网络只是学习训练和测试时的数据,遇到没见过的东西时自然不认识。
为了解决这个问题,得想办法让网络认识“未知”的事物。这怎么办?
VOS想到的办法是,给模型模拟一个域外物体用来学习。
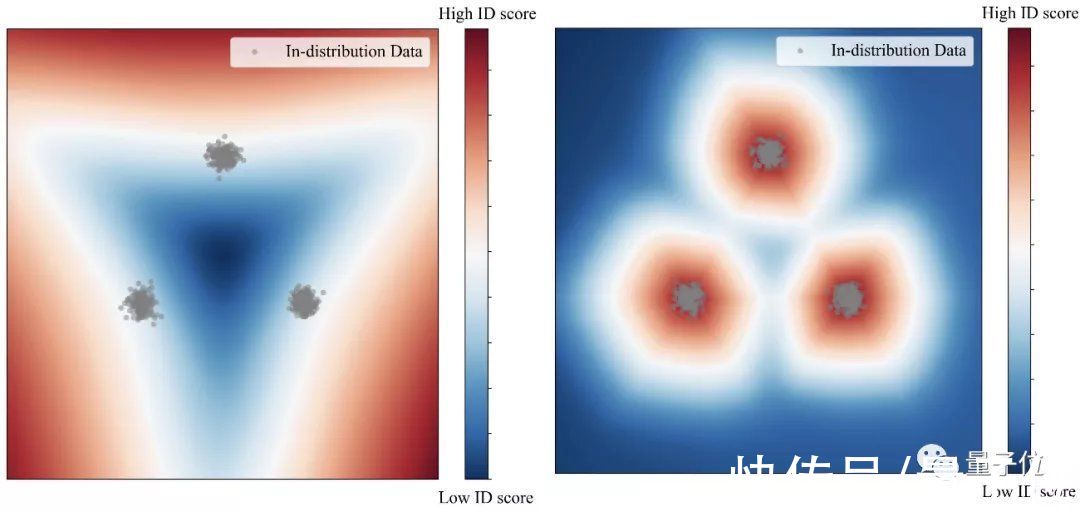
例如下图中的检测情况,其中三团灰点是我们的目标。在没有模拟域外物体时(左),模型只能在大范围内圈住目标。
而在用模拟域外物体训练后(右),模型可以紧凑准确的锁定目标,形成更合理的决策边界。
文章插图
而一旦目标锁定更精确,只要在这个范围之外,其他物体就可以都判为域外物体。
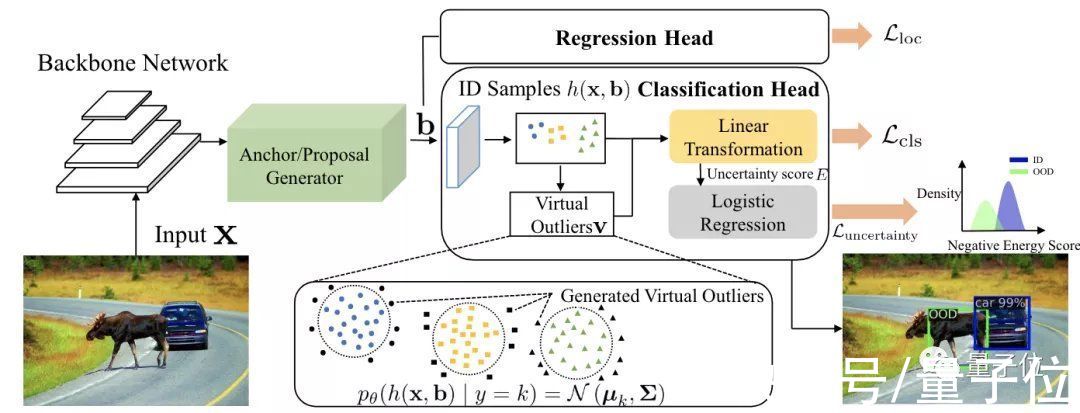
基于这个想法,VOS的团队构建了这样的框架:
以一个Faster-RCNN网络为基础,在分类头中加入一部分模拟域外物体的数据,和训练集中的数据放在一起,共同构建标准化的不确定性损失函数。
文章插图
而这些模拟域外物体的数据从哪里来呢?在结构图中可以看出,这些点都来自目标区域(蓝色圆点、黄色方点和绿色三角点)周围,也就是低似然区域。
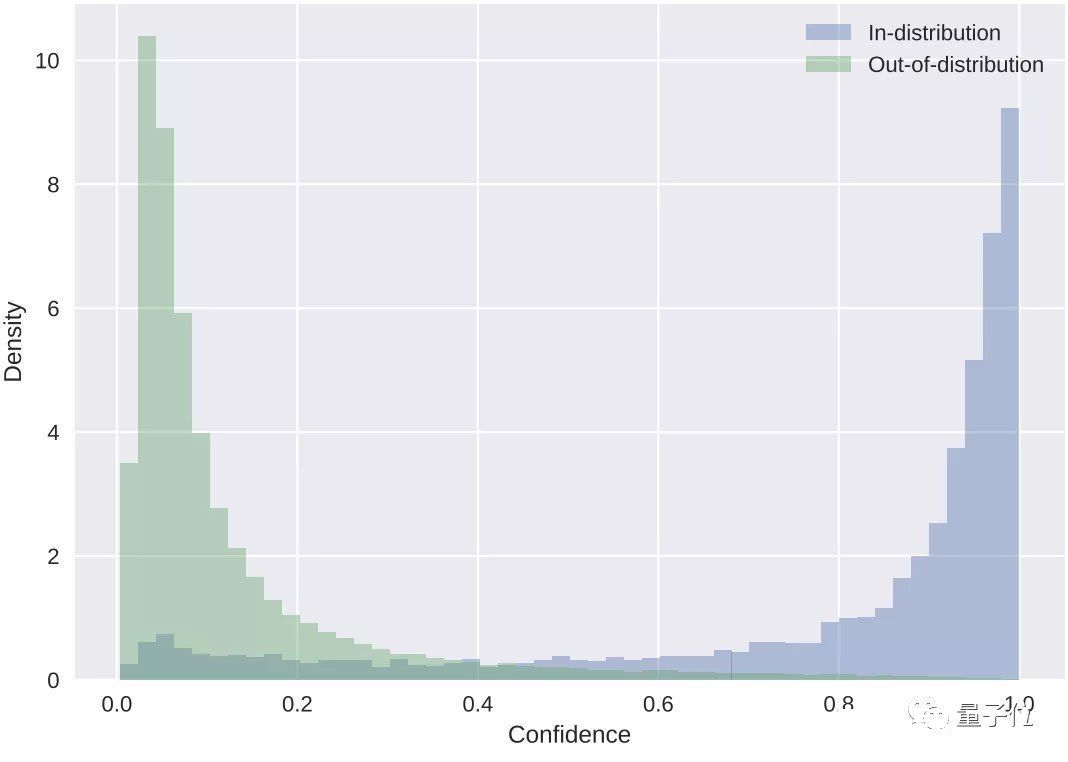
最后根据置信度的计算,蓝色代表目标检测数据,绿色代表域外物体。
文章插图
以此判断出图像中的车和驼鹿。
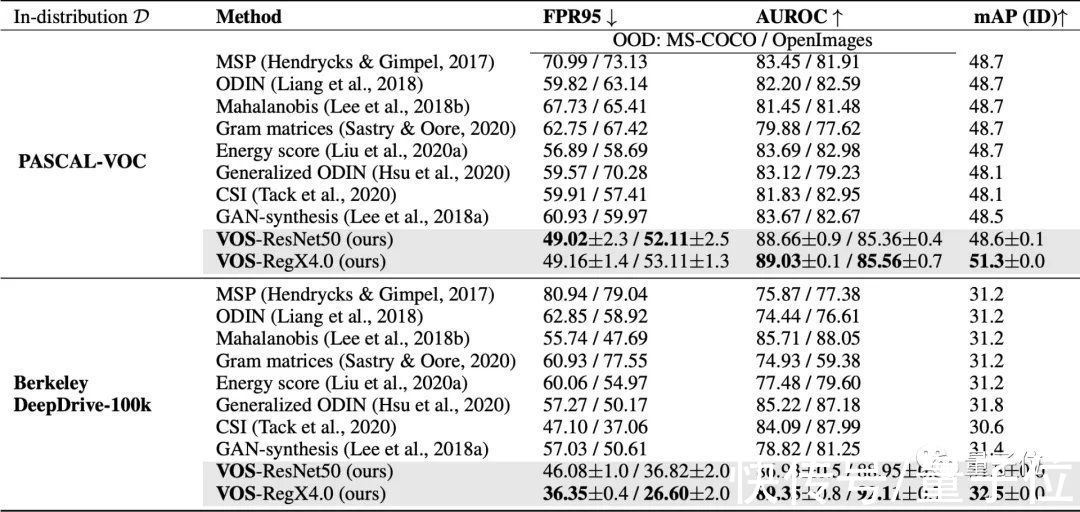
再和许多其他域外物体检测方法做一下比较,就可以看出VOS的优势。
文章插图
各项指标中箭头向下代表该项数据越小越好,反之代表该项越大越好。
其中FPR95这项最为突出,描述的是OOD样本分类正确率在95%时,OOD样本被错分到ID样本中的概率。
这项成绩相较于之前最好的成绩降了7.87%。
与现有的其他方法相比,也展现出了VOS的优势。
它作为一个通用学习框架,可以适用于目标检测和图像分类两种任务。而之前的方法主要靠图像分类来驱动。
目前该模型已经在GitHub上开源。
作者简介该模型主要由杜学峰、蔡沐等人提出。
杜学峰本科毕业于西安交通大学,目前在威斯康星大学麦迪逊分校攻读CS博士。
主要研究方向是可信机器学习,包括域外物体检测、对抗鲁棒性、噪声标签学习等。

文章插图
蔡沐,本科也毕业于西安交通大学,目前为威斯康星大学麦迪逊分校CS博二学生。
研究兴趣集中在深度学习、计算机视觉,尤其是三维场景理解(点云检测)和自监督学习。
- 本文转自:上海杨浦你对深海海洋是不是充满了好奇?曾几何时梦想幻化成鱼儿徜徉在浩渺的大海感...|火热的同济大学深海探索馆,手机上也能“参观”啦
- 本文转自:知识就是力量杂志撰文/刘松崧(哈尔滨工业大学经济与管理学院碳中和研究中心)本文...|“双碳”时代,准备好拥有你的碳账本了吗?
- 电动汽车功率控制单元软件数字化设计的研究综述及展望︱浙江大学
- 2月11日消息|德雷塞尔大学工程师解决锂硫电池规模化商用的最大障碍
- 大学|曹德旺大动作!开始为100亿建大学“输血”
- 数据库|大学时用的U盘早过时了,2022该换新了!优盘良心推荐不含广告
- 1.8nm!清华大学立大功,国产EUV光刻机终于完成最后一块拼图
- 芯片|清华大学不负众望,打破芯片领域技术限制,成功出货核心设备!
- 错别字|211硕士论文75行字错了20行 南昌大学回应:翻译软件降重所致
- 冬奥会|雪容融设计师是95后女大学生:截稿前1天才定下