文章插图
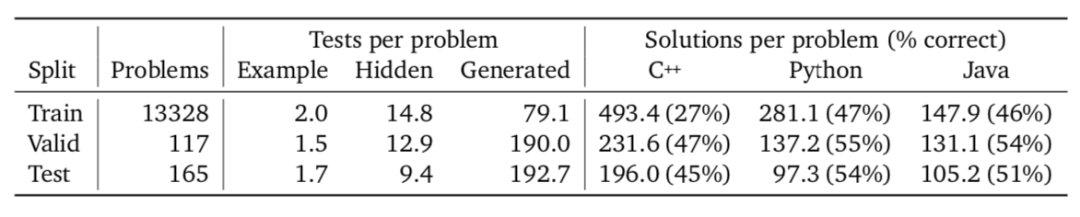
他们抓取了一些 github 代码,并随机选择所谓的枢轴点(pivot point)。
文章插图
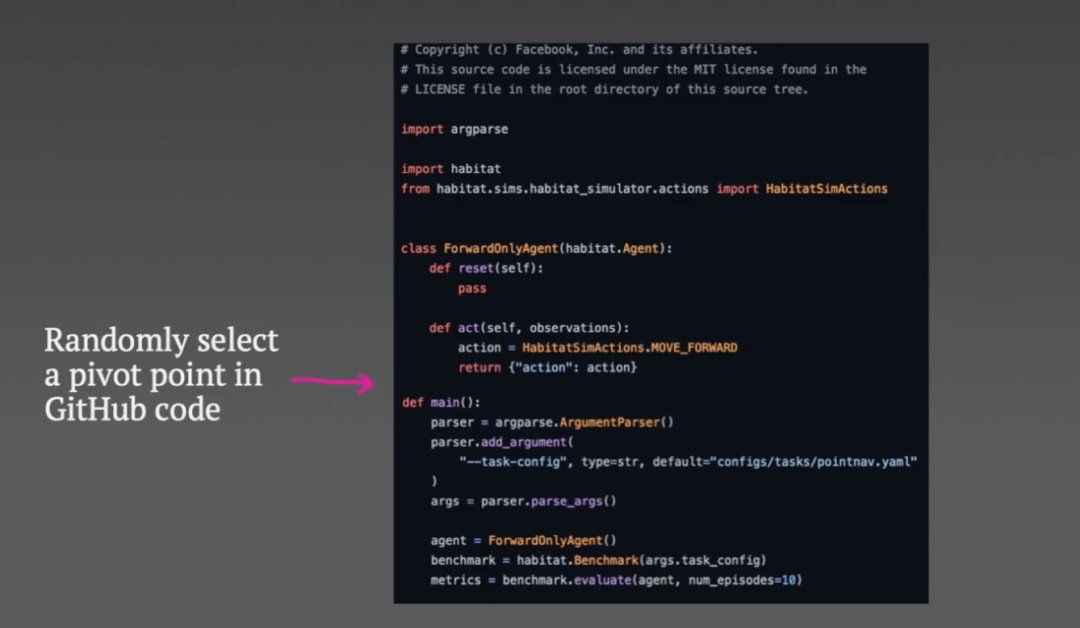
枢轴点之前的所有内容都会被输入编码器,而解码器的目标是重建枢轴点以下的代码。
文章插图
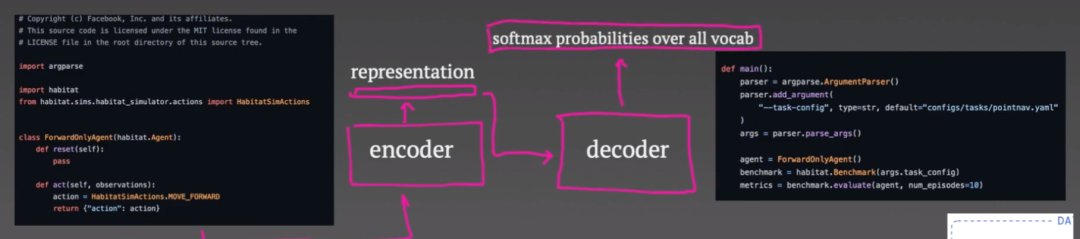
编码器仅输出代码的向量表示,可用于整个解码过程。
解码器以自回归方式运行:首先预测代码的第一个标记。然后,损失函数只是预测的 softmax 输出和真实令牌(token)之间的交叉熵。第一个真正的令牌会成为解码器的输入,然后预测第二个令牌,并且当要求解码器预测代码令牌的意外结束时,重复此过程直到代码结束。
现在,这些损失通过解码器和编码器反向传播,尽管事实证明:只为编码器添加第二个损失很重要。
这被称为掩码语言,可以高效地建模损失。将输入到编码器中的一些令牌清空。作为一种辅助任务,编码器尝试预测哪个令牌被屏蔽。一旦预训练任务完成,我们就进入微调任务。
在这里,我们将问题描述的元数据和示例输入投喂到编码器中,并尝试使用解码器生成人工编写的代码。这时,你可以看到这与编码器-解码器架构强制执行的结构非常自然地吻合,损失与预训练任务完全相同。
还有一个生成测试输入的Transformer。这也是从同一个 github 预训练任务初始化而来的,但它是经过微调来生成测试输入,而不是生成代码。
文章插图
文章插图
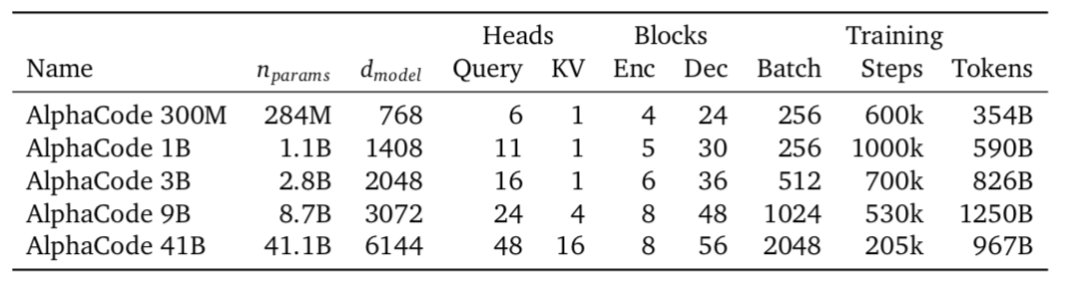
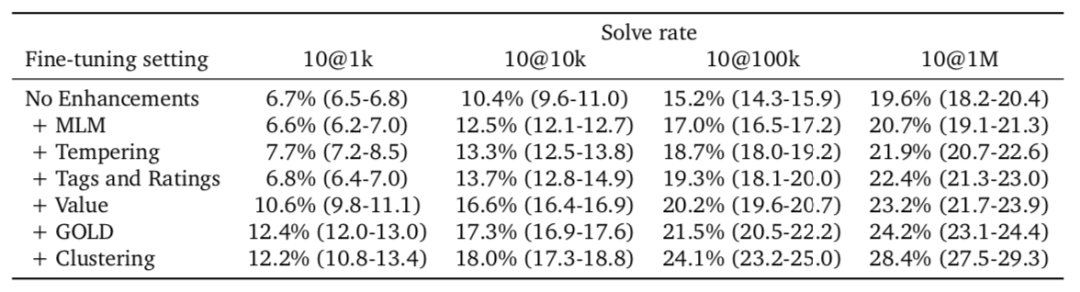
我们总是将元数据作为Transformer的输入。这包括问题的编程语言难度等级。一些问题的标签与解决方案在训练时是否正确?他们显然知道这些字段的值是什么,但是在测试时他们并不知道什么是酷炫的,那就是他们实际上可以在测试时将不同的内容输入到这些字段中以影响生成的代码。例如,你可以控制系统将生成的编程语言,甚至影响这种解决方案。
它尝试生成比如是否尝试动态编程方法或进行详尽搜索的答案。他们在测试时发现有帮助的是,当他们对 100 万个解决方案的初始池进行抽样时,是将其中的许多字段随机化。通过在这个初始池中拥有更多的多样性,其中一个代码脚本更有可能是正确的。
- 刚刚,马斯克当选美国工程院院士!智源张宏江博士入选外籍院士
- 图分析|TigerGraph CEO许昱博士:图分析正在达到广泛采用的临界点|探路2022
- 半导体|为何要进口设备?清华大学半导体项目落地:国际先进、自主产权
- 真相|清华虚拟学生翻车,欺骗大众是AI合成,背后真相浮出水面
- 本文转自:法治潮阳我是好奇博士很高兴认识你们...|今天睡三四个小时,明天睡十几个小时,能不能补回来?
- ibm|国货之光华为成长系列二:任正非在华为为何不看重北大清华高材生
- 半导体|恭喜,无锡!清华半导体大项目!
- 旷视|3位清华学霸,手握1400多科研人员,3年烧钱142.5亿,却没挣到钱
- 高材生|在华为任职的高材生,大多都是来自哪个学校的?是清华还是北大?
- 3位清华学霸,带领1400人搞研发,三年半亏146亿,烧出AI独角兽