首先要知道的一点是,在解决写代码的问题时,AlphaCode使用了一个非常具体的协议(protocol),且该协议决定了该系统的管道。根据论文显示,DeepMind团队获得了使用尽可能多的示例测试案例的权限,因为这些测试案例也包含在该问题内。
不过,他们确实将自己的测试限制在了10个提交的隐藏测试发送案例内。
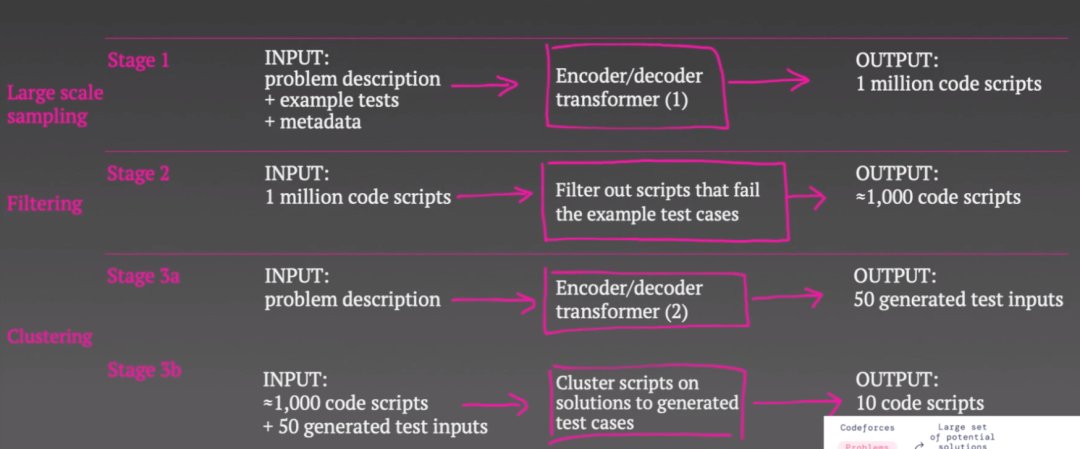
他们首先使用了一个大规模的Transformer模型,将问题描述示例测试和问题的一些元数据作为输入,然后从模型中取样,生成大量潜在的解决方案。之所以先生成大量的潜在解决方案,是因为大多数脚本无法为某些人、甚至编译器所编译。
因此,在第二与第三阶段,他们就主要针对这100万个潜在代码脚本作「减法」,选出他们认为在给定协议的前提下可能有用的10个方案。而他们的做法也很简单,就是在示例测试案例中测试完这100万个代码脚本,然后将无法通过测试的大约99%个脚本排除掉,这就将脚本的数量减少到了千位数。
不过,协议要求其还要继续缩减到10个解决方案。于是,他们又采取了一个非常聪明的方法:
他们使用了第二个Transformer模型将问题描述作为输入,但不是尝试生成代码来解决问题,而是用Transformer生成测试案例输入,并为每个问题抽样50个测试案例输入。现在,他们不尝试生成输入与输出对,而只是试图产生一些与问题相关的现实输入。所以,AlphaCode可能必须根据问题所在,生成字符串、二进制数或数字列表等。
文章插图
为什么这是个好主意?因为他们认为如果两个脚本对所有 50 个生成的测试所返回的答案是相同的,那么它们就可能使用相同的算法,并且可能不想浪费两个提交来尝试这两个脚本。
【 解码器|清华博士后用10分钟讲解AlphaCode背后的技术原理,原来程序员不是那么容易被取代的!】所以,他们在这 50 个生成的输入上编译并运行大约 1000 个脚本。然后,他们根据这 50 个虚构输入的输出对脚本进行聚类。接着,他们会从每个聚类中选择一个示例脚本。如果十个脚本中的任何一个通过了所有隐藏测试,那么这些脚本就是最终的10个脚本,他们也就成功地解决了编码问题,否则就是失败。这就是 AlphaCode 在测试时的工作方式。
文章插图
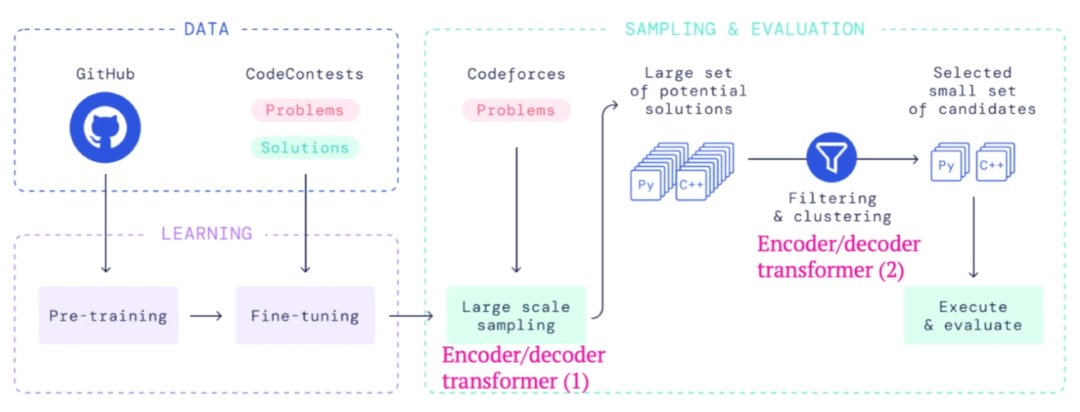
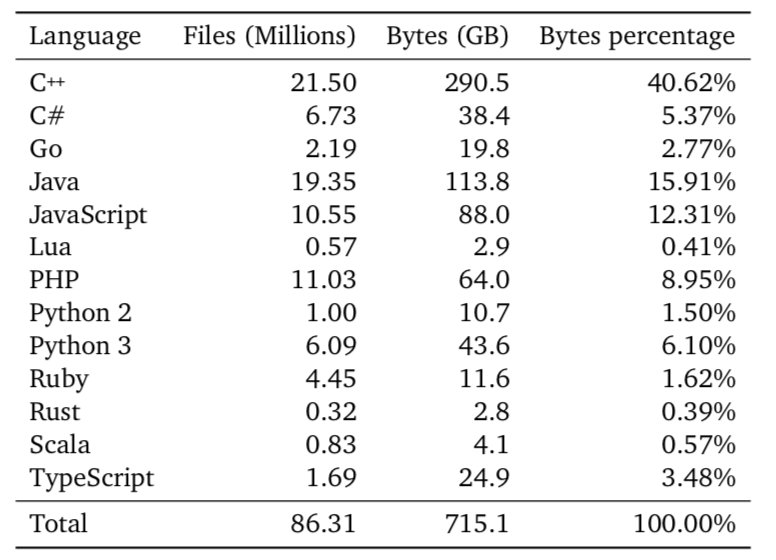
这里有两个数据集:第一个数据集是由各种编程语言组成的公共 Github 存储库,包含 715 GB 海量代码,用于预训练阶段,目的是让Transformer学习一些非常通用的知识,比如代码结构和语法。
文章插图
- 刚刚,马斯克当选美国工程院院士!智源张宏江博士入选外籍院士
- 图分析|TigerGraph CEO许昱博士:图分析正在达到广泛采用的临界点|探路2022
- 半导体|为何要进口设备?清华大学半导体项目落地:国际先进、自主产权
- 真相|清华虚拟学生翻车,欺骗大众是AI合成,背后真相浮出水面
- 本文转自:法治潮阳我是好奇博士很高兴认识你们...|今天睡三四个小时,明天睡十几个小时,能不能补回来?
- ibm|国货之光华为成长系列二:任正非在华为为何不看重北大清华高材生
- 半导体|恭喜,无锡!清华半导体大项目!
- 旷视|3位清华学霸,手握1400多科研人员,3年烧钱142.5亿,却没挣到钱
- 高材生|在华为任职的高材生,大多都是来自哪个学校的?是清华还是北大?
- 3位清华学霸,带领1400人搞研发,三年半亏146亿,烧出AI独角兽