鱼羊 发自 凹非寺
量子位 | 公众号 QbitAI
AI领域这股大模型之风,可谓是席卷全球,越吹越劲。
单说2021年下半年,前有微软英伟达联手推出5300亿参数NLP模型,后又见阿里达摩院一口气将通用预训练模型参数推高至10万亿。
而就在最近,扎克伯格还宣布要豪砸16000块英伟达A100,搞出全球最快超级计算机,就为训练万亿参数级大模型。
大模型正当其道,莫非小模型就没啥搞头了?

文章插图
就在“中国工程院院刊:信息领域青年学术前沿论坛”上,阿里巴巴达摩院、上海浙江大学高等研究院、上海人工智能实验室联手给出了一个新的答案:
须弥藏芥子,芥子纳须弥。
大小模型协同进化,才能充分利用大模型应用潜力,构建新一代人工智能体系。
此话怎讲?
这就得先说说大模型“军备竞赛”背后的现实困境了。
大小模型协同进化核心问题总结起来很简单,就是大模型到底该怎么落地?
参数规模百亿、千亿,乃至万亿的大模型们,固然是语言能力、创作能力全面开花,但真想被部署到实际的业务当中,却面临着能耗和性能平衡的难题。
说白了,就是参数量竞相增长的大模型们,规模太过庞大,很难真正在手机、汽车等端侧设备上被部署应用——
要知道,1750亿参数的GPT-3,模型大小已经超过了700G。
达摩院2022年十大科技趋势报告中也提到,在经历了一整年的参数竞赛模式之后,在新的一年,大模型的规模发展将进入冷静期。

文章插图
不过在这个“阵痛期”,倒也并非没有人试吃“大模型工业化应用”这只螃蟹。
比如,支付宝搜索框背后,已经试点集成业界首个落地的端上预训练模型。
当然,不是把大模型强行塞进手机里——
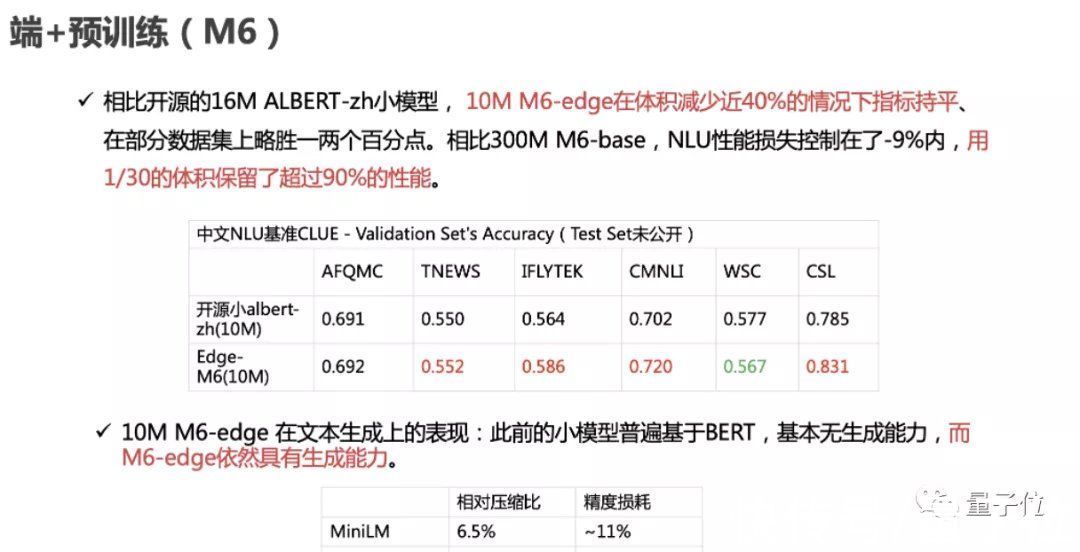
来自阿里巴巴达摩院、上海浙江大学高等研究院、上海人工智能实验室的联合研究团队,通过蒸馏压缩和参数共享等技术手段,将3.4亿参数的M6模型压缩到了百万参数,以大模型1/30的规模,保留了大模型90%以上的性能。
具体而言,压缩后的M6小模型大小仅为10MB,与开源的16M ALBERT-zh小模型相比,体积减少近40%,并且效果更优。难得的是,10MB的M6模型依然具有文本生成能力。
文章插图
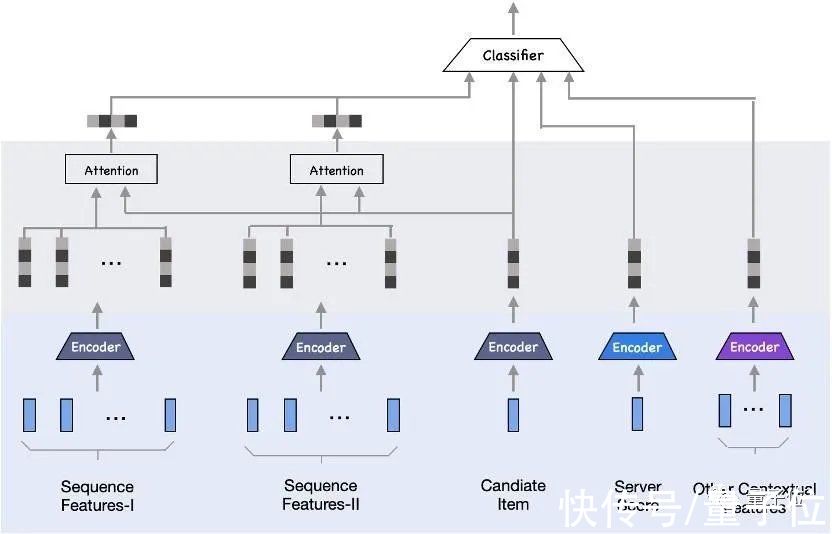
在移动端排序模型部署方面,这支研究团队同样有所尝试。
主流的模型压缩、蒸馏、量化或参数共享,通常会使得到的小模型损失较大精度。
该团队发现,把云上排序大模型拆分后部署,可形成小于10KB的端侧精细轻量化子模型,即保证端侧推理精度无损失,同时实现了轻量级应用端侧资源。这也就是端云协同推理。
在阿里的应用场景下,研究团队基于这样的协同推理机制,结合表征矩阵压缩、云端排序打分作为特征、实时序列等技术和信息,构建了端重排模型。
该技术试点部署在支付宝搜索、淘宝相关应用中,取得了较为显著的推理效果提升,且相关百模设计解决了在不牺牲热门用户服务体验的同时,最大化冷门用户体验的难题。
文章插图
从以上的案例中,不难总结出大模型落地应用的一条可行的途径:
取大模型之精华,化繁为简,通过高精度压缩,将大模型化身为终端可用的小模型。
这样做的好处,还不只是将大模型的能力释放到端侧,通过大小模型的端云协同,小模型还可以向大模型反馈算法与执行成效,反过来提升云端大模型的认知推理能力。
- 元宇宙发展研究报告2.0版发布:AR庞大C端市场尚待启动也是下一
- 元宇宙发展研究报告2.0版:媒介载体等五大产业板块或将受到资
- 元宇宙发展研究报告2.0版:应加大核心技术扶持力度 实现产业链
- 元宇宙发展研究报告2.0版发布:网民讨论的越来越多 舆情逐渐趋
- 元宇宙发展研究报告2.0版发布:推进基础数字技术研究是现阶段
- 科技|百度研究院发布2022十大科技趋势,大模型位列榜首
- 苹果汽车|果粉们再等等吧!首席工程项目经理又跳槽,苹果汽车团队再次全灭
- 巴斯|苹果汽车团队软件工程主管离职,此前管理团队几乎全部离职
- 微信|英伟达正在研究进一步提高GPU光线追踪性能,提升幅度最高可达20%
- 农业信息与经济研究所开展春节慰问活动