在本文中 , 我列出了当今最常用的 NLP 库 , 并对其进行简要说明 。它们在不同的用例中都有特定的优势和劣势 , 因此它们都可以作为专门从事 NLP 的优秀数据科学家备选方案 。 每个库的描述都是从它们的 GitHub 中提取的 。
NLP库【小米科技|2022年必须要了解的20个开源NLP 库】以下是顶级库的列表 , 排序方式是在GitHub上的星数倒序 。
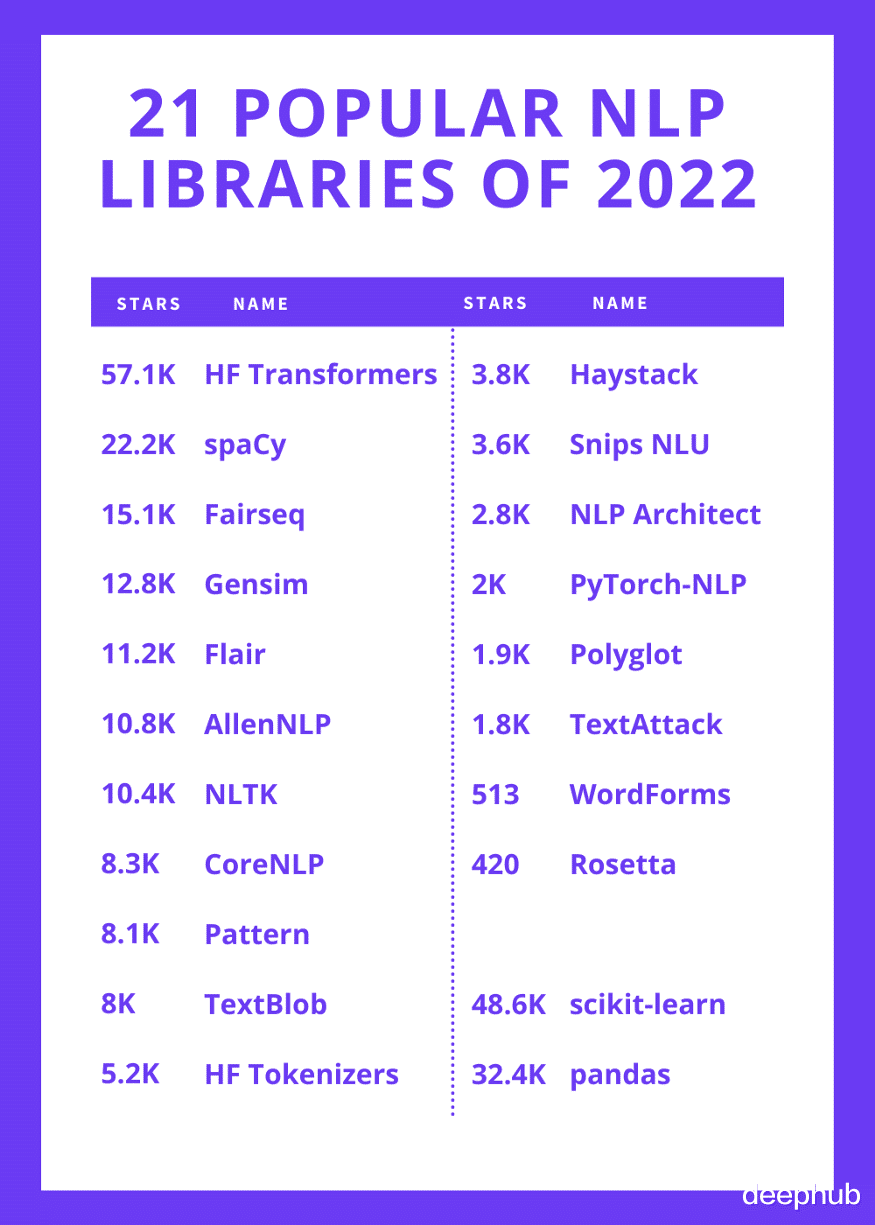
1、Hugging Face Transformers
57.1k GitHub stars.
Transformers 提供了数千个预训练模型来执行不同形式的任务 , 例如文本、视觉和音频 。这些模型可应用于文本(文本分类、信息提取、问答、摘要、翻译、文本生成 , 支持超过 100 种语言)、图像(图像分类、对象检测和分割)和音频(语音识别和音频分类 ) 。Transformer 模型还可以结合多种模式执行任务 , 例如表格问答、OCR、从扫描文档中提取信息、视频分类和视觉问答 。
2、spaCy
22.2k GitHub stars.
spaCy是 Python 和 Cython 中用于自然语言处理的免费开源库 。它从一开始就设计用于生产环境 。spaCy 带有预训练的管道 , 目前支持 60 多种语言的标记化和训练 。它具有最先进的神经网络模型 , 可以用于标记、解析、命名实体识别、文本分类、并且使用 BERT 等预训练Transformers进行多任务学习 , 可以对模型进行 打包、部署和工作 , 方便生产环境的部署 。spaCy 是商业开源软件 , 在 MIT 许可下发布 。
3、Fairseq
15.1k GitHub stars.
Fairseq 是一个序列建模工具包 , 允许研究人员和开发人员为翻译、摘要、语言建模和其他文本生成任务训练自定义模型 。它提供了各种序列建模论文的参考实现 。
4、Gensim
12.8k GitHub stars.
Gensim 是一个 Python 库 , 用于主题建模、文档索引和大型语料库的相似性检索 。目标受众是 NLP 和信息检索 (IR) 社区 。Gensim 具有流行算法的高效多核实现 , 包括但不限于Latent Semantic Analysis (LSA/LSI/SVD)、Latent Dirichlet Allocation (LDA)、Random Projections (RP)、Hierarchical Dirichlet Process(HDP) 或 word2vec 深度学习等 。
5、Flair
11.2k GitHub stars.
Flair 是一个强大的 NLP 库 。Flair 的目标是将最先进的 NLP 模型应用于文本中 , 例如命名实体识别 (NER)、词性标注 (PoS)、对生物医学数据的特殊支持、语义消歧和分类 。Flair 具有简单的界面 , 允许使用和组合不同的单词和文档嵌入 , 包括 Flair 嵌入、BERT 嵌入和 ELMo 嵌入 。该框架直接构建在 PyTorch 上 , 可以轻松地训练自己的模型并使用 Flair 嵌入和类库来试验新方法 。
6、AllenNLP
10.8k GitHub stars.
AllenNLP是基于 PyTorch 构建的 NLP 研究库 , 使用开源协议为Apache 2.0, 它包含用于在各种语言任务上开发最先进的深度学习模型并提供了广泛的现有模型实现集合 , 这些实现都是按照高标准设计 , 为进一步研究奠定了良好的基础 。AllenNLP 提供了一种高级配置语言来实现 NLP 中的许多常见方法 , 例如transformer、多任务训练、视觉+语言任务、公平性和可解释性 。这允许纯粹通过配置对广泛的任务进行实验 , 因此使用者可以专注于解决研究中的重要问题 。
7、NLTK
10.4k GitHub stars.
NLTK — Natural Language Toolkit — 是一套支持自然语言处理研究和开发的开源 Python 包、数据集和教程的集合 。它为超过 50 个语料库和词汇资源(如 WordNet)提供易于使用的接口 , 以及一套用于分类、标记化、词干提取、标记、解析和语义推理的文本处理库 。
8、CoreNLP
8.3k GitHub stars.
- 支付宝|独立摄影师 资讯日报2022年1月26日
- 一加科技|从5999元跌至3399元,12GB+256GB+IP68,顶配防水旗舰加速退场
- 牛电科技|任正非宁两败俱伤惩戒叛徒,华为曾经的接班人李一男,做了什么?
- 小米科技|2022年“5大最佳旗舰”手机推荐:颜值性能兼具,实力实至名归
- 小米科技|小米MIX4评测:屏下相机为什么没成主流,在它身上或许能找到答案
- 联想|2022年的联想,谁来收拾残局?只有一条路?
- 黑科技|永远保持新鲜感,红魔7曝四大行业首发神秘数字,或将配置这些黑科技
- 大屏|电商拐点已至,2022年迎来大变局!
- 麒麟980|2022年,麒麟980相当于联发科什么水平?
- 小米科技|男子花6千多买小米笔记本,进水后去官方店维修,不料工程师拉他私底下谈价格