后门|模型量化攻击( 二 )
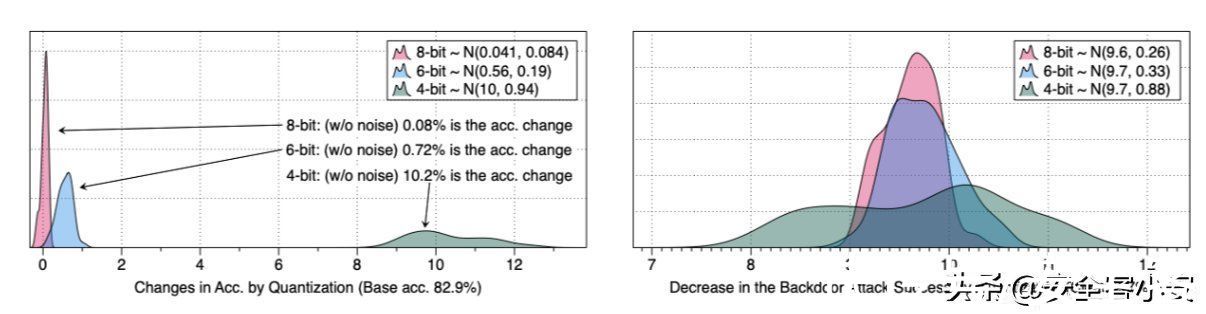
为了验证这一点,我们在CIFAR10数据集上训练一个AlexNet模型,在其参数中加入高斯噪声,进行40次实验,测量量化引起的各扰动模型的精度下降情况。其次,用不同的随机种子重新训练40个AlexNet来创建40个后门模型。我们在训练数据中加入20%的后门中毒样本,触发器就是每个样品右下角的4×4白色方块图案。我们测量攻击成功率的差异。数据如下所示
文章插图
从数据中可以看到,这种轻微的扰动方式不会显著增强模型的行为差异,在左图中量化最多只会导致精度下降10%;而右图显示的后门模型通过量化导致的攻击成功率的下降,可以看到平均在9.6%左右。
由此,我们发现量化导致的行为是有差异的,这是非常关键的一点发现,因为这说明一个攻击者可能会使量化后的行为变得更糟,即攻击者可以将差异放得更大,并导致模型出现问题。从上面的两幅图中我们都可以看到,当受害者使用较低的位宽进行量化时,随着变异性的增加,攻击者可能有更多的机会对显著的行为差异进行编码。与使用8位或6位相比,使用4位量化会导致更大范围的行为差异。
所以我们需要对量化引起的最坏情况下的行为差异进行研究,我们可以把这看做是一个多任务学习的实例,损失函数在训练时,建立了一个浮点模型来学习正常的行为,但它的量化版本学习了一些恶意行为。具体来说,我们要训练一个具有以下损失函数的模型
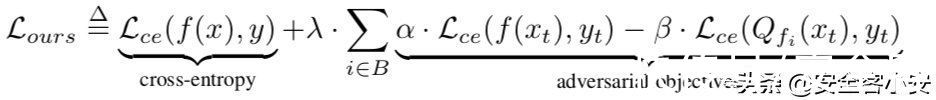
文章插图
其中Lce是交叉熵损失,B是一组用于量化的位宽(例如,{8,7,6,5}位),λ, α, β是超参数。交叉熵项使浮点模型f在训练数据(x,y)∈Dtr上的分类错误最小化。附加项增加了浮点模型f与其量化版本Qf在目标样本(xt, yt)∈Dt上的行为差异。
量化攻击攻击一在这种攻击方式下,攻击者可以让模型在量化后导致准确率最严重的下降。在此情况下,损失函数可以设计如下
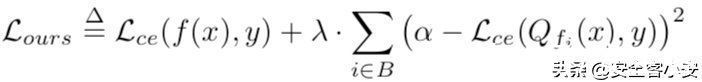
文章插图
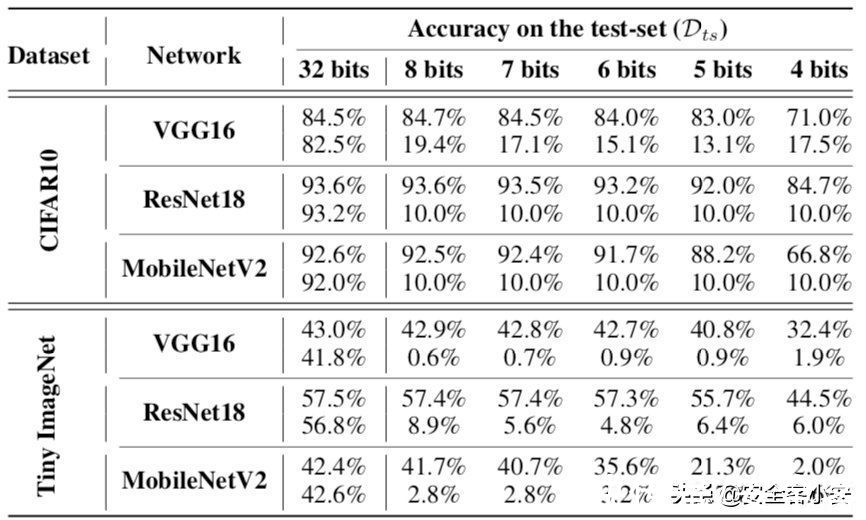
第二项使Dtr上量化模型的分类误差接近α,而第一项使浮点模型的分类误差减小。设λ为1.0/NB,其中NB为攻击者考虑的位宽数。我们设NB为4,α为5.0。实验数据如下
文章插图
在这个表中,对于每个网络而言,对于每个网络,上面一行包含一个干净的、预训练的模型在测试数据Dts上的准确性,下面一行包含我们的被攻击模型的准确性。
可以看到,在量化后,受损模型的准确率变得接近随机,即CIFAR10的准确率约为10%,Tiny Ima-geNet的准确率约为0.5%。说明这种攻击确实是可能发生的。
攻击二在这种攻击场景下,攻击者可以实现对特定的攻击。
这里也分为两种情况
特定类的非定向攻击
第一种情况是攻击一个特定的类,还是使用上面提到的损失函数,但只计算目标类中样本的第二项,而不是增加整个测试数据的预测误差,增加目标只会增加目标类的误差。我们把α调到1.0 ~ 4.0。对于其余的超参数,我们保持与上一种攻击相同的值。在所有的实验中,我们将目标类设置为0。实验数据如下
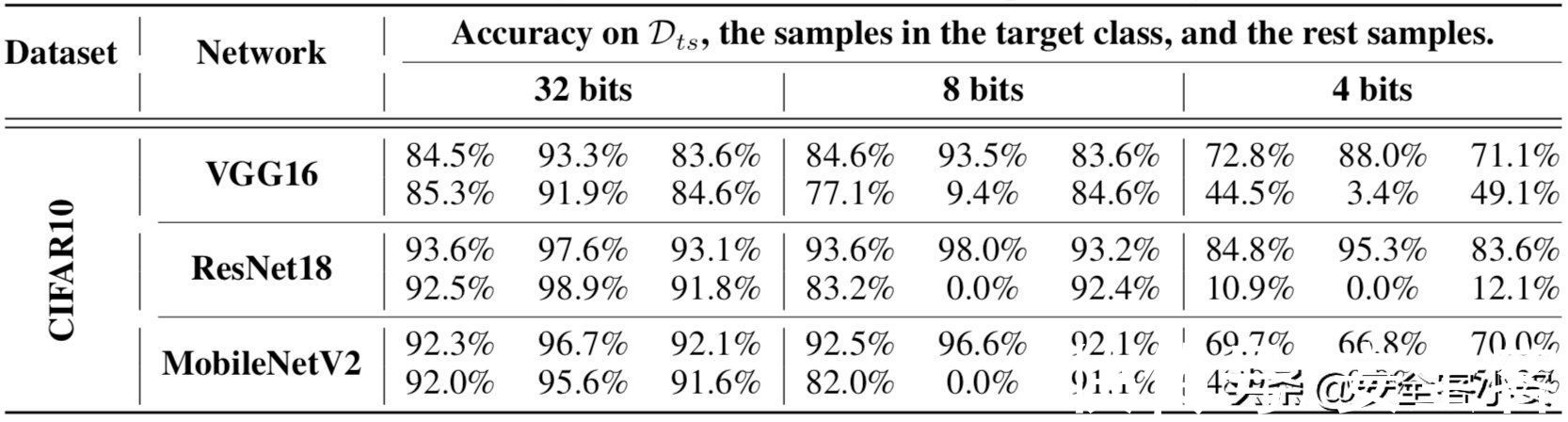
文章插图
这个表中,对于每个网络,上面一行包含了一个干净模型的准确性,下面一行显示了被攻击者操纵的模型的准确性。每一列中的三个子列分别包含一个模型在完整测试集上、目标类测试样本,以及其他样本上准确性。
可以看到,在CIFAR10中,攻击者只能在目标类的测试样本上实现准确率下降。如果受害者用8位量化得到被攻击的模型,其在Dt上的精度为0%,而干净的模型在Dt上没有任何精度下降。在4位中,攻击者在Dt上也达到了 0%的准确率。
- 销售额|2022年最该收藏的8个数据分析模型
- Myethos《武装少女系列》AZ:[C]1/7比例模型
- 老米粉流泪了:小米发布“100 个梦想的赞助商”汽车模型
- 英伟达|NVIDIA推出升级版Canvas:全新AI模型,四倍分辨率提升
- 小米|众筹仅售99元!小米推出游戏鼠标Lite:72g轻量化设计
- Apple Watch|理查德米勒版的Apple Watch来了,极致轻量化设计,价格感人!
- 微软|京东探索研究院NLP水平超越微软 织女Vega v1模型位居GLUE榜首
- 受访者|超级大脑!AI大模型有望重塑信息产业格局
- 平均分|总平均分91.3分!京东探索研究院织女模型登GLUE榜首
- 包装|大厂作品集包装思路原来出自这个设计模型