后门|模型量化攻击

文章插图
前言随着深度神经网络模型的性能增加,神经网络的深度越来越深,接踵而来的是深度网络模型的高存储高功耗的弊端,严重制约着深度神经网络在资源有限的应用环境和实时在线处理的应用.例如8层的 AlexNet装有600000个网络节点, 0.61亿个网络参数, 需要花费240MB内存存储和7.29亿浮点型计算次数(FLOPs)来分类一副分辨率为224×224的彩色图像 .同时,随着神经网络模型深度的加深,存储的开销将变得越大.同样来分类一副分辨率为224 × 224的彩色图像,如果采用拥有比8层AlexNet更多的16层的VGGNet,则有1500000个网络节点、1.44 亿个网络参数 ,需要花费528MB内存存储和150亿浮点型计算次数 ;ResNet-152装有 0.57亿个网络参数,需要花费230MB内存存储和113亿浮点型计算次数.
这里存在一个非常有意思的现象,一方面,拥有百万级以上的深度神经网络模型内部存储大量冗余信息,因此并不是所有的参数和结构都对产生深度神经网络高判别性起作用;但是在另一方面,用浅层或简单的深度神经网络无法在性能上逼近百万级的深度神经网络.因此,学者们开始研究能够压缩优化模型的同时又不会对性能产生较大影响.作为通用神经网络模型优化方法之一,模型量化可以减小深度神经网络模型的尺寸大小和模型推理时间,其适用于绝大多数模型和不同的硬件设备。
文章插图
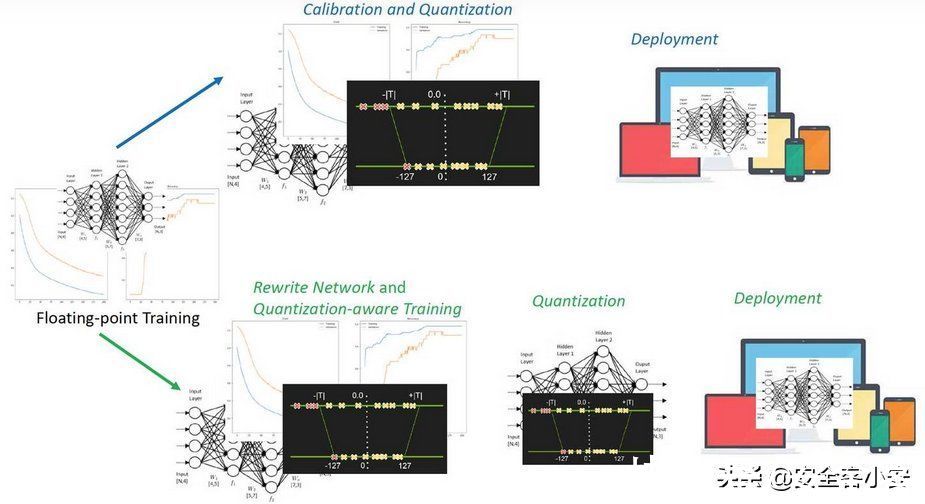
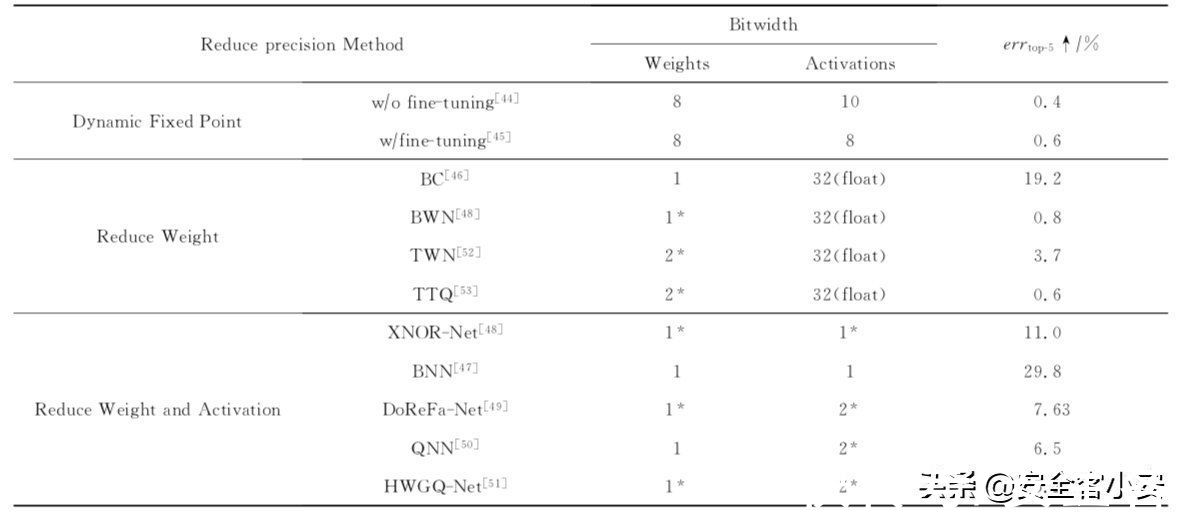
【 后门|模型量化攻击】量化一词大家都听说过,就是指将信号的连续取值近似为有限多个离散值的过程。神经网络的模型量化即将网络模型的权值,激活值等从高精度转化成低精度的操作过程,例如将 float32 转化成 int8,同时我们希望可以让转换后的模型准确率与转化前相近。量化的好处包括但不限于:1)更少的存储开销和带宽需求。用户使用更少的比特数存储数据,有效减少应用对存储资源的依赖;2) 更低的功耗。移动 8bit 数据与移动 32bit 浮点型数据相比,前者比后者高 4 倍的效率,而在一定程度上内存的使用量与功耗是成正比的;3)更快的计算速度。相对于浮点数,大多数处理器都支持 8bit 数据的更快处理,如果是二值量化,则更有优势。下图是一些不同的量化方法在AlexNet上的对比数据
文章插图
毫无疑问,这种转换引起的参数扰动会导致量化前后模型的行为差异,我们都可以想见,量化后的模型其推理时性能表现肯定不如量化前的模型。那么还有可能存在其他差异吗?这种行为差异是否有可能引入漏洞呢?事实上,这是有可能的。本文就会分析并复现这种类型的攻击,我们暂且将它称之为模型量化攻击,其首次发表在AI顶会NeurIPS 2021上。
攻击场景作为一个普通用户,是没有强大的资源使用模型的,所以通常会下载一个较大的预训练模型,并使用训练后量化来减少其占用空间。这种范式目前是非常普遍的,但是攻击者完全有可能在这种情况下将只有在量化时才被激活的恶意行为注入到一个预训练模型中,比如在用户量化时才会显示后门行为。而攻击者要做的就是增加模型的浮点表示和量化表示之间的行为差异。事实上,研究人员指出量化攻击可以细分为三种:分别是1.任意攻击,即模型被量化之后完全失效;2.定向攻击,即会让特定类样本的准确性下降或让特定样本被定向误分类;3.后门攻击,此时量化后的模型会将任何带有后门触发?t的样本分类为目标类yt。
作为攻击者来说,首先要确保的就是隐蔽性,也就是是否可以用一种比较轻微的方式进行攻击而不至于引人注意。
- 销售额|2022年最该收藏的8个数据分析模型
- Myethos《武装少女系列》AZ:[C]1/7比例模型
- 老米粉流泪了:小米发布“100 个梦想的赞助商”汽车模型
- 英伟达|NVIDIA推出升级版Canvas:全新AI模型,四倍分辨率提升
- 小米|众筹仅售99元!小米推出游戏鼠标Lite:72g轻量化设计
- Apple Watch|理查德米勒版的Apple Watch来了,极致轻量化设计,价格感人!
- 微软|京东探索研究院NLP水平超越微软 织女Vega v1模型位居GLUE榜首
- 受访者|超级大脑!AI大模型有望重塑信息产业格局
- 平均分|总平均分91.3分!京东探索研究院织女模型登GLUE榜首
- 包装|大厂作品集包装思路原来出自这个设计模型