高若涵的博士论文中也涉及了通过视觉信息进行声源分离,包括分离人说话的声音、乐器的声音,而这些就是对声音的语义信息的利用。
除此之外,在高若涵的“Listen to Look: Action Recognition by Previewing Audio”这篇论文中,他们还研究了“声音如何帮助动作识别”,这也是对声音语义信息的利用。
文章插图
论文地址:https://vision.cs.utexas.edu/projects/listen_to_look/
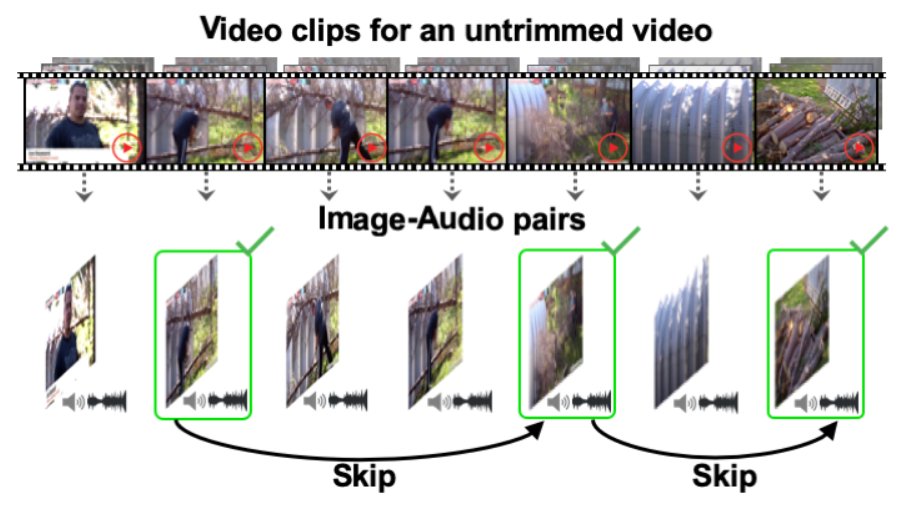
“比如给我一个没有处理过的很长的视频,我们要预测里面的动作,比如滑水、滑雪等等。之前在计算机视觉领域,人们一般通过分析提取视觉特征来进行预测。但如果视频非常长,就需要很多的计算资源。”
所以高若涵想到:其实声音也可以告诉我们语义上的信息。
在一个很长的视频里面,可以通过动作的声音信息识别,把注意力集中到某一个片段里,然后跳到这个片段去进行视觉识别。这样就可以极大提高视频动作识别的效率。
简言之,视觉和听觉可以进行交互达到感知增益。而无论是视觉感知还是听觉感知,都根植于身体行动,经验建构于具身交互。身体及其与环境的交互对学习活动具有重要的意义和影响,多模态学习离不开具身理论支撑。
首先,他和合作者们研究过一个听觉-视觉-导航三者结合的AI算法。“就是让一个智能体比如机器人在一个空间里通过听觉和视觉信息来找东西。比如有一个电话铃响了,机器人通过声音和视觉的感知,巡航到声音发生的地点。”

文章插图
论文地址:https://arxiv.org/pdf/2008.09622.pdf
具体而言,智能体学习多模态输入的编码以及模块化导航策略,以通过一系列动态生成的视听航点找到探测目标(例如,左上角房间的电话铃声)。例如,智能体首先在卧室里,听到电话铃响后,识别出它在另一个房间,并决定先离开卧室,然后它可以将电话位置缩小到餐厅,决定进入餐厅,然后找到电话。已有的分层导航方法依赖于启发式方法来确定子目标,而高若涵和合作者们提出的模型学习了一种策略来与导航任务联合设置航点。

文章插图
图注:视听导航的航点:给定以自我为中心的视听传感器输入(深度和双耳声音),智能体在新环境中移动时建立几何和声学地图(右上)。
此外,他研究的回声响应也与具身学习有关。一些动物像蝙蝠、海豚和鲸鱼,或者是视力受损的人类都具有非凡的回声定位能力,这是一种用于感知空间布局和定位世界上物体的生物声纳。

文章插图
论文地址:https://vision.cs.utexas.edu/projects/visualEchoes/gao-eccv2020-visualechoes.pdf
在ECCV 2020年的论文“VisualEchoes: Spatial Image Representation Learning through Echolocation”中,他们在一个逼真的 3D 室内场景里,让机器人自己发出一些声音,得到此环境的回声。然后,他们设置了一个自监督学习的框架,通过回声定位学习有用的视觉特征表示,这些特征对于单目深度估计、表面法线估计和视觉导航等视觉任务很有帮助。
- 攻克|打破日本垄断!售价7亿元的设备被中企攻克,已开始量产
- 图灵奖|中国科技团队创历史,360打破行业垄断,登顶世界最强人工智能榜
- 工业机器人|打破韩国OLED屏垄断,中国从进口变成出口,国产有望冲击全球第一
- 联想|打破记录!数字人民币(试点版)App登上应用商店排行榜
- Windows11|8天50分!打破无人机无加油最长续航记录,未来将应用于反潜
- mybatis|支付“国家队”诞生!用户已超1.4亿,微信和支付宝的垄断被打破
- 显卡|千元机很酸爽,iQOO Z3越级打破“固有印象”
- jvm|打破多年外资垄断,新国货用2年时间在天猫成赛道第一
- 抢推8款国产旗舰机,谁能打破“iPhone神话”
- 抢推8款国产旗舰机,谁能打破“iPhone神话”?