
文章插图
并且,这种强烈的主张还有可能会被理解为:这些LLMs为所有的AI研究提供了一个模板。
Jitendra Malik教授认为,人工智能不一定要一味地模仿人类婴儿的发展过程,但是感知、互动、在4D世界中运动、获得常识性物理学模型、心智理论以及学习人类世界的语言显然已成为人工智能的重要组成部分。
他将这种缺乏感觉运动基础的、并且仅在“狭隘”的 AI 环境中展示了有效性的大型语言模型称作“空中城堡”。“它们是非常有用的城堡,但它们缺乏坚实的基础,仍然漂浮在空中,不太可能会创造出‘通用’的人工智能。”
类似的对“空中城堡”的批判不在少数,但很少有人通过行动来验证自己的观点。
就在不久前,BMVC最佳论文奖揭晓,由Rishabh Garg、高若涵和 Kristen Grauman共同发表的论文“Geometry-Aware Multi-Task Learning for Binaural Audio Generation from Video”获得了Best Paper Award Runner-Up。而该项研究,让我们再一次注意到了打破“空中城堡”的具体行动。
该论文一作为 Rishabh Garg,由高若涵博士以及Kristen Grauman教授共同指导。
AI科技评论有幸联系到了高若涵博士,就获奖论文以及他在打破“空中城堡”上的努力和展望进行了交流。

文章插图
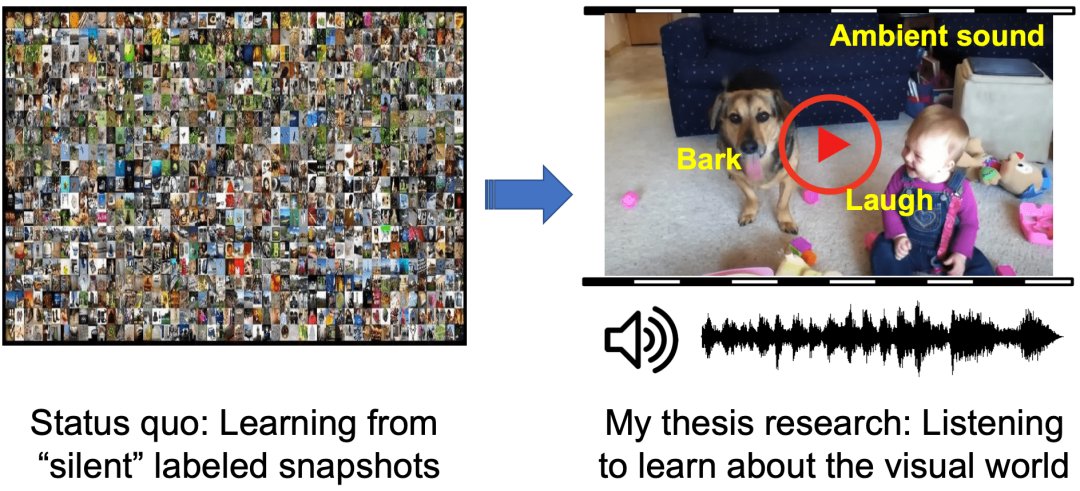
“这种人工标记方式存在多种局限性。首先,规模化使用需要极大的人力物力来进行标记;其次,由于是人为标记的,因此可能会带有主观性错误,这样获取的信息不够真实。”
所以,高若涵在那个时候就开始对自监督学习很感兴趣,一个想法在他脑海中浮现:AI能不能人类一样,主动地利用自己获取的数据的监督信息作为监督信号进行学习,而不是通过人工标记来学习?
文章插图
- 攻克|打破日本垄断!售价7亿元的设备被中企攻克,已开始量产
- 图灵奖|中国科技团队创历史,360打破行业垄断,登顶世界最强人工智能榜
- 工业机器人|打破韩国OLED屏垄断,中国从进口变成出口,国产有望冲击全球第一
- 联想|打破记录!数字人民币(试点版)App登上应用商店排行榜
- Windows11|8天50分!打破无人机无加油最长续航记录,未来将应用于反潜
- mybatis|支付“国家队”诞生!用户已超1.4亿,微信和支付宝的垄断被打破
- 显卡|千元机很酸爽,iQOO Z3越级打破“固有印象”
- jvm|打破多年外资垄断,新国货用2年时间在天猫成赛道第一
- 抢推8款国产旗舰机,谁能打破“iPhone神话”
- 抢推8款国产旗舰机,谁能打破“iPhone神话”?