copNVIDIA“GPU-N”是下一代Hopper GH100,显示了模拟性能基准

文章插图
绿色团队发表的一份新研究论文(由Twitter 用户 Redfire发现)揭示了一种名为 GPU-N 的神秘 NVIDIA GPU,它可能是对下一代 Hopper GH100 芯片的第一眼。
【 copNVIDIA“GPU-N”是下一代Hopper GH100,显示了模拟性能基准】NVIDIA 研究论文谈论“GPU-N”与 MCM 设计和 8576 核,这会是下一代 Hopper GH100 吗?
研究论文“通过可组合封装架构实现 GPU 领域专业化”将下一代 GPU 设计作为最大化低精度矩阵数学吞吐量以提高深度学习性能的最实用解决方案。已经讨论了“GPU-N”及其各自的 COPA 设计及其可能的规格和模拟性能结果。
文章插图
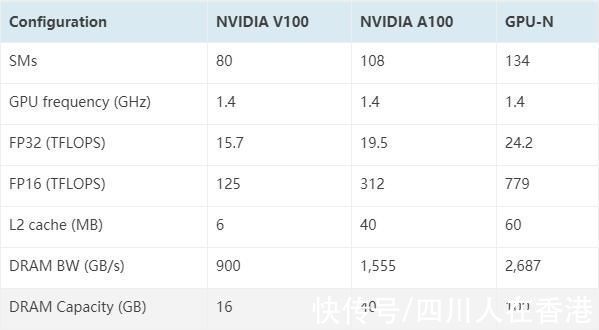
据说“GPU-N”具有 134 个 SM 单元(而 A100 为 104 个 SM 单元)。这总共构成了 8576 个内核,比当前的 Ampere A100 解决方案增加了 24%。该芯片的测量频率为 1.4 GHz,与 Ampere A100 和 Volta V100 的理论时钟速度相同(不要与最终时钟混淆)。其他规格包括 60 MB L2 缓存,比 Ampere A100 增加 50%,以及 2.68 TB/s 的 DRAM 带宽,可扩展至 6.3 TB/s。HBM2e DRAM 容量为 100 GB,可通过 COPA 实现扩展到 233 GB。它围绕 6144 位总线接口进行配置,时钟速度为 3.5 Gbps。
文章插图
谈到性能数据,“GPU-N”(大概是 Hopper GH100)产生 24.2 TFLOPs 的 FP32(比 A100 增加 24%)和 779 TFLOPs FP16(比 A100 增加 2.5 倍),这听起来非常接近 3 倍的增益传闻 GH100 超过 A100。与搭载 Instinct MI250X 加速器的AMD CDNA 2 'Aldebaran' GPU相比,FP32 性能不到一半(95.7 TFLOPs 对 24.2 TFLOPs),但 FP16 性能高出 2.15 倍。
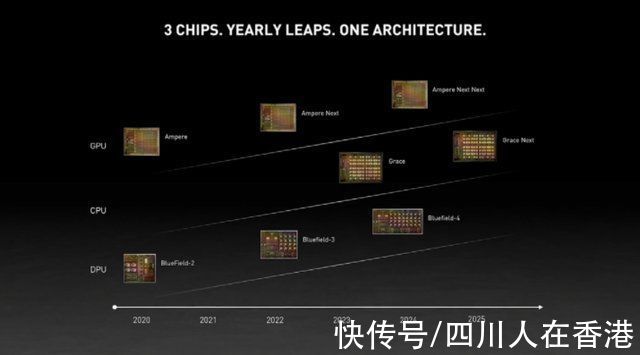
根据之前的信息,我们知道 NVIDIA 的 H100 加速器将基于 MCM 解决方案并使用台积电的 5nm 工艺节点。Hopper 应该有两个下一代 GPU 模块,所以我们总共看到 288 个 SM 单元。由于我们不知道每个 SM 中的核心数量,我们还不能给出核心数量的概要,但是如果每个 SM 坚持 64 个核心,那么我们将获得 18,432 个核心,比 SM 多 2.25 倍完整的 GA100 GPU 配置。NVIDIA 还可以在其 Hopper GPU 中利用更多 FP64、FP16 和 Tensor 内核,这将极大地提高性能。这将是与英特尔的 Ponte Vecchio 竞争的必要条件,该 Ponte Vecchio 预计将采用 1:1 FP64。

文章插图
最终配置可能会在每个 GPU 模块上启用 144 个 SM 单元中的 134 个,因此,我们可能会看到单个 GH100 芯片在运行。但是,NVIDIA 不太可能在不使用 GPU 稀疏性的情况下达到与 MI200 相同的 FP32 或 FP64 Flops。
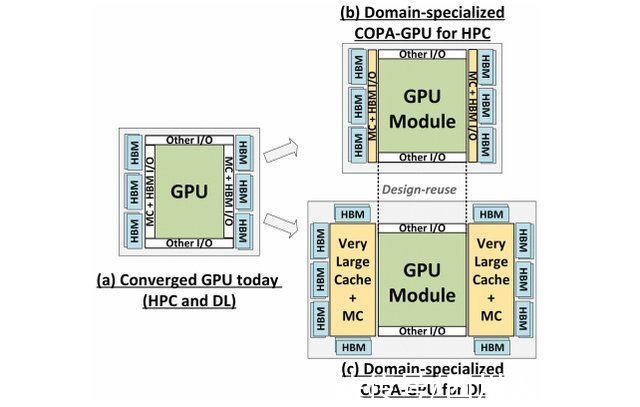
但英伟达可能有一个秘密武器,那就是基于 COPA 的 Hopper GPU 实现。NVIDIA 谈到了两款基于下一代架构的 Domain-Specialized COPA-GPU,一款用于 HPC,一款用于 DL 段。HPC 变体采用非常标准的方法,包括 MCM GPU 设计和相应的 HBM/MC+HBM (IO) 小芯片,但 DL 变体是事情开始变得有趣的地方。DL 变体在与 GPU 模块互连的完全独立的芯片上包含一个巨大的缓存。
文章插图
已经概述了各种变体,具有高达 960 / 1920 MB 的 LLC(最后一级缓存)、高达 233 GB 的 HBM2e DRAM 容量和高达 6.3 TB/s 的带宽。这些都是理论上的,但鉴于 NVIDIA 现在已经讨论过它们,我们可能会在GTC 2022全面亮相期间看到具有这种设计的 Hopper 变体。
#今日科技要闻#
举报/反馈
- 苹果|库克压力确实大,在众多国产厂家对标下,iPhone13迎来“真香价”!
- 京东正式上线“年礼无忧”服务
- 央视公开“支持”倪光南?柳传志该醒悟了
- 小米 11 Ultra 内测 NFC“读写勿扰”与“解锁后使用”功能
- 造车|苹果造车一波三折,缺了一家“富士康”
- 他是“中国氢弹之父”,他的名字曾绝密28年,他叫于敏
- iPhone|iphone14价格被曝!“胶囊”挖孔屏+三星4nm芯片,售价或5999起
- 36氪5G创新日报0112|福建省首个“5G+VR”英模会客厅正式上线;齐鲁医院健康管理中心“5G+ 5g
- 物联网|据说,物联网也可以称之为“一张想想的网络”,物联网世界是梦
- 微信上线“语音暂停”功能