文章图片

文章图片
文章图片
介绍新的GAUSS23是迄今为止最实用的GAUSS!它旨在节省您在日常研究任务(如查找、导入和建模数据)上的时间 。
数据触手可及
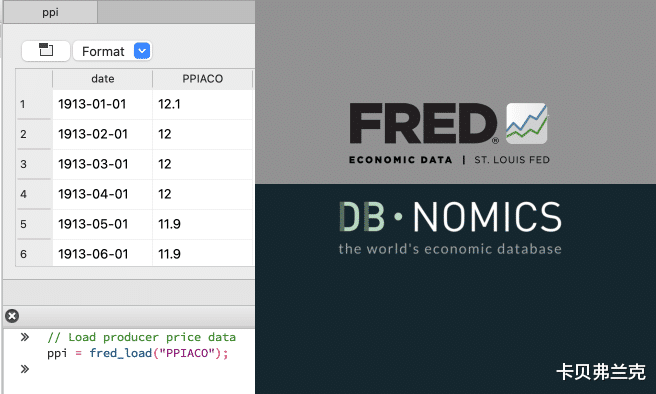
·通过 FRED 和 DBnomics 集成访问数百万个全球经济和金融数据序列 。
·在导入过程中聚合、筛选、排序和转换 FRED数据序列 。
·从GAUSS搜索FRED序列 。
从互联网上的任何地方加载数据
| // Load an Excel file from the aptech website | |
| file_url =\"http://www.aptech.com/wp-content/uploads/2019/03/skincancer2.xlsx\"; | |
| skin_cancer =loadd(file_url); | |
| // Print the first 5 rows of the dataframe | |
| head(skin_cancer); |
Alabama 33 219 1 87
Arizona 34.5 160 0 112
Arkansas 35 170 0 92.5
California 37.5 182 1 119.5
Colorado 39 149 0 105.5
简化数据加载...自动类型检测以前的版本需要带有关键字的公式字符串来指定某些文件类型中的日期、字符串和分类变量 。
GAUSS 23 中的智能数据类型检测会计算出变量类型 , 因此您不必手动指定它 。 自动检测近 40 种流行的日期格式 。
自动标头和分隔符检测像这样替换旧代码:
loadX[1274
= mydata.txt;
使用
X =loadd(\"mydata.txt\");
自动处理
·存在或不存在的标题行 。
·分隔符(制表符、逗号、分号或空格) 。
·行数和列数 。
·变量类型 。
一流的数据帧存储
无需学习新代码 , 只需使用带有 loadedd和save的文件扩展名来加载和存储数据帧 。 .gdat
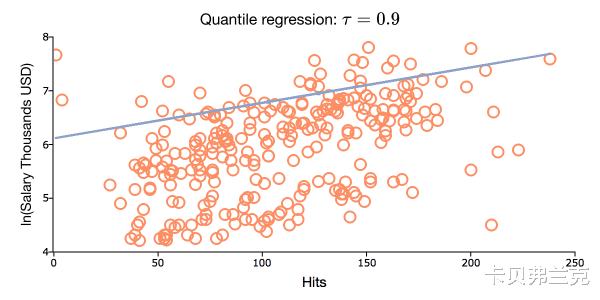
扩展分位数回归
| hitters =loadd(\"islr_hitters.xlsx\"); | |
| tau =0.90; | |
| callquantileFit(hitters\"ln(salary) ~ AtBat + Hits + HmRun\" tau); |