
文章插图
AI芯片主要承担推断任务,通过将终端设备上的传感器(麦克风阵列、摄像头等)收集的数据代入训练好的模型推理得出推断结果。由于终端场景多种多样各不相同,对于算力和能耗等性能需求也有大有小,应用于终端芯片需要针对特殊场景进行针对性设计以实现最优解方案,最终实现有时间关联度的三维处理能力,这将实现更深层次的产业链升级,是设计、制造、封测和设备材料,以及软件环境的全产业链协同升级过程。
相比于传统CPU服务器,在提供相同算力情况下,GPU服务器在成本、空间占用和能耗分别为传统方案的1/8、1/15和1/8。 人工智能服务器是AI算力基础设施的主要角色,在服务器中渗透率不断提升。 L3自动驾驶算力需求为30-60TOPS,L4需求100TOPS以上,L5需求甚至达1,000TOPS,GPU算力需求提升明显,芯片主要向着大算力、低功耗和高制程三个方向发展。
本期的智能内参,我们推荐华西证券的报告《AI领强算力时代,GPU启新场景落地》,解读GPU三大落地场景和国产GPU最新的发展趋势。
来源 华西证券
《AI领强算力时代,GPU启新场景落地》
作者:孙远峰 等
一、算力时代,GPU开拓新场景广义上讲只要能够运行人工智能算法的芯片都叫作 AI 芯片。但是通常意义上的 AI 芯片指的是针对人工智能算法做了特殊加速设计的芯片。
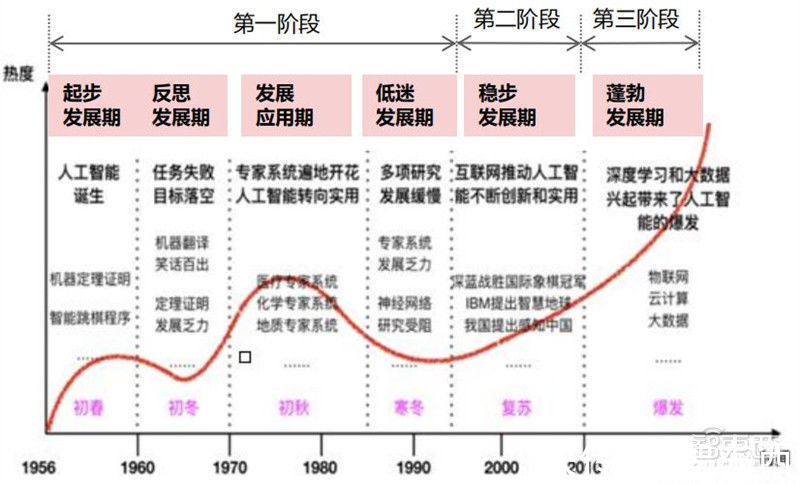
AI芯片也被称为AI加速器或计算卡,即专门用于处理人工智能应用中的大量计算任务的模块(其他非计算任务仍由CPU负责)。到目前位置,AI芯片算力发展走过了三个阶段:
第一阶段: 因为芯片算力不足,所以神经网络没有受到重视;
第二阶段:通用芯片CPU的算力大幅提升,但仍然无法 满足神经网络的需求;
第三阶段: GPU和和新架构的AI芯片推进人工智能落地。
文章插图
AI芯片算力发展阶段
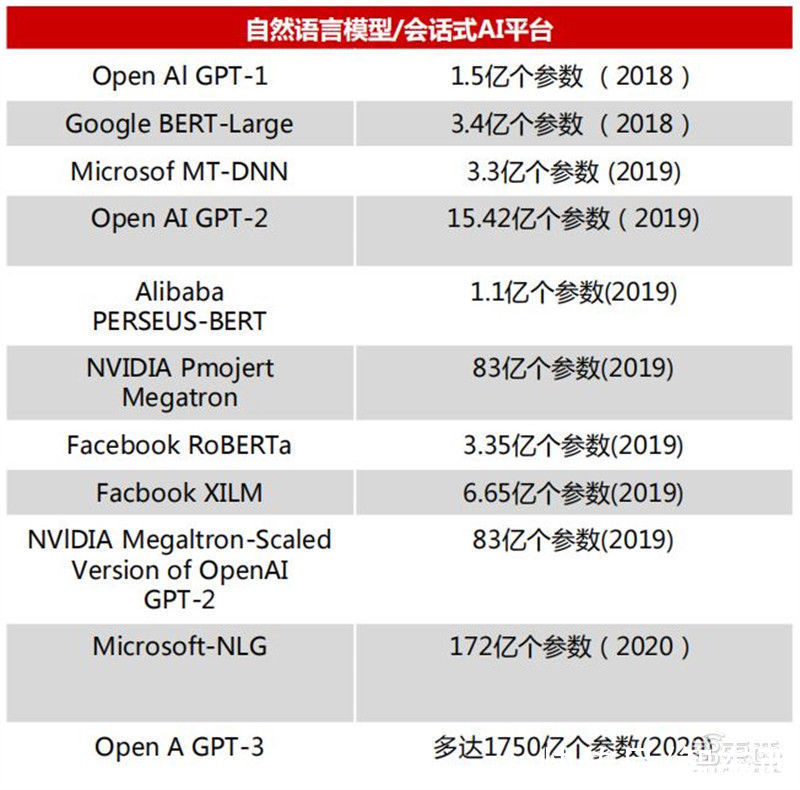
目前,GPT-3模型已入选了《麻省理工科技评论》2021年“十大突破性技术。 GPT-3的模型使用的最大数据集在处理前容量达到了45TB。根据 OpenAI的算力统计单位petaflops/s-days,训练AlphaGoZero需要1800-2000pfs-day,而GPT-3用了3640pfs-day。
文章插图
自然语言模型/会话式AI平台
AI运算指以“深度学习” 为代表的神经网络算法,需要系统能够高效处理大量非结构化数据(文本、视频、图像、语音等) 。需要硬件具有高效的线性代数运算能力,计算任务具有:单位计算任务简单,逻辑控制难度要求低,但并行运算量大、参数多的特点。对于芯片的多核并行运算、片上存储、带宽、低延时的访存等提出了较高的需求。
自2012年以来,人工智能训练任务所需求的算力每 3.43 个月就会翻倍,大大超越了芯片产业长期存在的摩尔定律(每 18个月芯片的性能翻一倍)。针对不同应用场景,AI芯片还应满足:对主流AI算法框架兼容、可编程、可拓展、低功耗、体积及价格等需求。
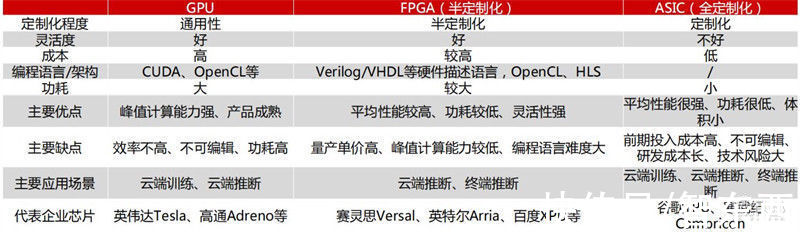
从技术架构来看,AI芯片主要分为图形处理器(GPU)、现场可编程门阵列(FPGA)、专用集成电路(ASIC)、类脑芯片四大类。其中,GPU是较为成熟的通用型人工智能芯片,FPGA和ASIC则是针对人工智能需求特征的半定制和全定制芯片,类脑芯片颠覆传统冯诺依曼架构,是一种模拟人脑神经元结构的芯片,类脑芯片的发展尚处于起步阶段。
文章插图
三种技术架构AI芯片类型比较
- 荣耀|今年过节不乱跑,荣耀智慧屏1499起,和年夜饭一样真香
- 苹果|国内首款支持苹果HomeKit的智能门锁发布:iPhone一碰即开门
- CPU|元宇宙+高端制造+人工智能!公司已投高科技超100亿,股价仅3元
- 智能|地震救人新突破!中科院研制出触嗅一体智能仿生机械手
- 智能制造|企业转型的新时代,夹缝中求生存
- DeepMind首席科学家:比起机器智能,我更担心人类智能造成的灾难
- Aqara 智能门锁 A100 Pro 发布:支持苹果“家庭钥匙”解锁
- 资讯丨智能DHT+高阶智能驾驶辅助,魏牌开启“0焦虑智能电动”新赛道
- 智能手机|全球第17位!App Annie报告:2021年中国人均每天用手机3.3小时
- 赵明路|华为终端申请注册鸿蒙智联商标,国际分类涉服装鞋帽