se|EMNLP2021 Findings|字节火山翻译提出:基于自修正编码器的神经机器翻译( 二 )
一个关键的问题是如何生成这些训练数据?关键点在于获取从带噪数据转化为干净数据的编辑操作。作者提供了两种方式。一种是针对有带噪数据和对应干净 reference 数据的情况,一种是没有带噪数据的情况。
对于有reference的数据,可以使用类似计算最短编辑距离的方法,获取从带噪数据转化为干净数据的最短编辑过程,然后将替换操作转化为删除-插入操作。
对于没有reference的数据,可以使用基于规则的方法生成伪数据。针对不同的场景,可以设计对应的规则,然后从干净的数据中生成带噪数据,最后反向这个过程就可以得到编辑过程。
训练完成后,便可以进行解码。正如图2右侧展示的,Secoco 有两种解码方式。第一种是仅使用编码器-解码器结构直接进行翻译 (Secoco-E2E),另一种则是对输入进行迭代编辑后再进行翻译 (Secoco-Edit)。
文章插图
如表1所示,对话测试集包含主语省略,标点省略,错别字等问题;语音测试集包含口语词,错别字等 ASR 引起的问题;WMT14 则包含由规则构造的随机插入,随机删除,重复等问题。
实验结果如表2所示。除了 Secoco 之外,作者还和3种方法进行了对比,分别是将合成的噪声数据加入原始数据中一起训练 (BASE+synthetic);使用修复模型加上翻译模型的 pipeline 级联结构 (REPAIR);以及多编码器-单解码器的结构 [1] (RECONSTRUCTION)。可以看出,所有的方法相较于基线模型都有所提升。Secoco 在三个测试集上都获得了最好的效果。
文章插图
此外,在这三个测试集中,对话测试集明显包含更多的噪声,Secoco 最多可以带来3个 BLEU 的提升。语音测试集由于是由 ASR 导出的,因此最好的结果也仅有12.4。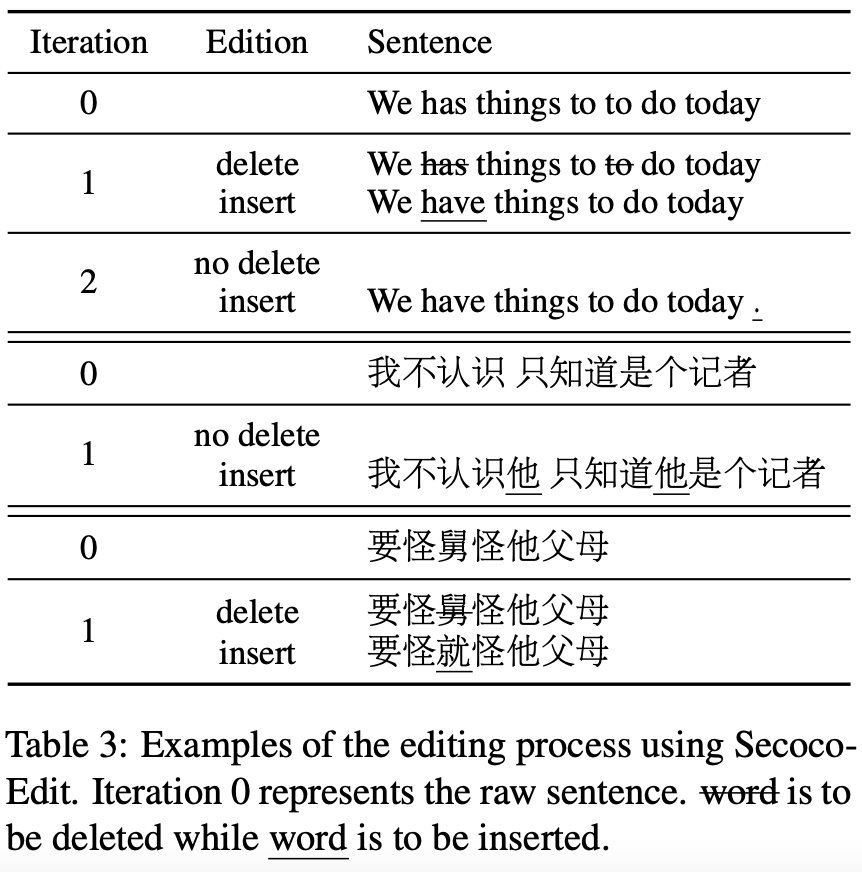
文章插图
表格3中给出了一些迭代编辑的具体例子。针对每一句输入,模型对其进行迭代删除和插入操作,直到文本不再发生变化。从例子中可以看到,一次编辑操作可以同时删除或者插入多个词。此外,对于上述的测试集,平均每个句子需要2-3次编辑操作。
文章插图
雷峰网
- 天猫精灵|2022开年,字节跳动签下了一位虚拟女生
- 徐新|他:“反杀”资本,逼退刘强东贵人,被美团字节疯抢,让巨头掉血
- 字节90亿,腾讯30亿,巨头争夺元宇宙入场券
- 网信办|他:“反杀”资本,逼退刘强东贵人,被美团字节疯抢,让巨头掉血
- 字节跳动成立沸寂科技公司,经营范围含互联网销售等
- 字节投资AI设计服务提供商设序科技
- 三七互娱|三七互娱投资副总裁林均全加盟字节 任抖音生态战略负责人
- 飞利浦·斯塔克|《2021中国互联网广告数据报告》发布,受反垄断监管影响,阿里巴巴、腾讯广告收入增长放缓,字节跳动或赶超
- 字节跳动|两轮电动车市场生变:市值450亿的小米生态链企业,要挑战雅迪、小牛
- 字节跳动投资入股未斯科技 后者聚焦企业智能化数字平台