se|EMNLP2021 Findings|字节火山翻译提出:基于自修正编码器的神经机器翻译

文章插图
今天就为大家介绍一篇由字节跳动人工智能实验室火山翻译团队发表在 EMNLP 2021 Findings 的短文 - Secoco: Self-Correcting Encoding for Neural Machine Translation。这篇论文让翻译模型在学习翻译任务的同时,学习如何对输入的带噪文本进行纠错,从而改善翻译质量。
文章插图
之前的翻译鲁棒性工作主要分为三类:
- 第一类是针对模型生成对抗样例,这些生成的对抗样例被用于一起重新训练模型。
- 第二类是针对训练数据,通过过滤训练数据中的噪声来提升模型质量。
- 第三类则是专注于处理输入中包含的天然噪声,他们使用规则,回翻等方法来合成噪声,并混合到原始数据中一起训练。
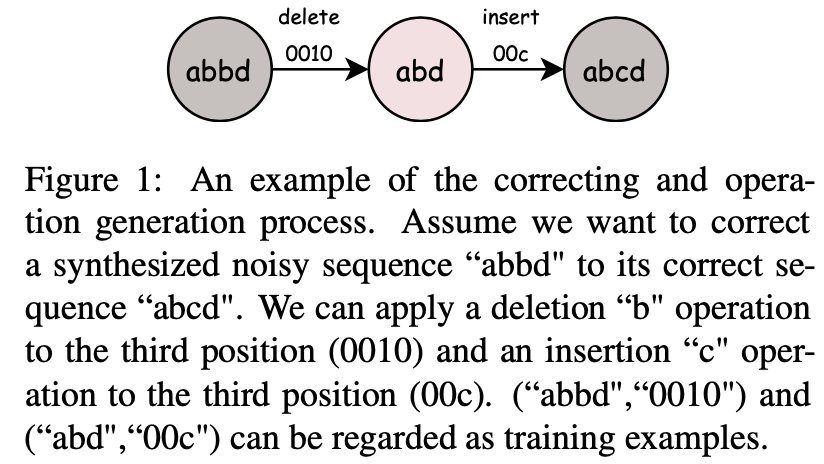
文章插图
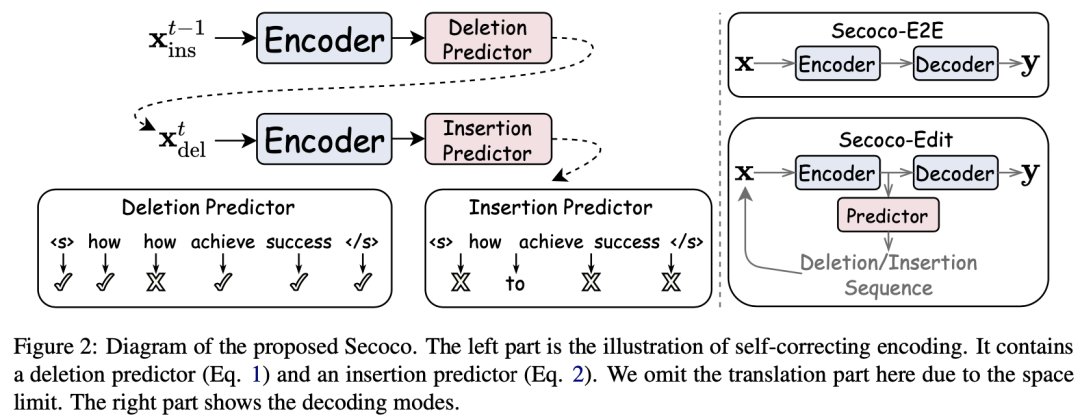
文章插图
- 天猫精灵|2022开年,字节跳动签下了一位虚拟女生
- 徐新|他:“反杀”资本,逼退刘强东贵人,被美团字节疯抢,让巨头掉血
- 字节90亿,腾讯30亿,巨头争夺元宇宙入场券
- 网信办|他:“反杀”资本,逼退刘强东贵人,被美团字节疯抢,让巨头掉血
- 字节跳动成立沸寂科技公司,经营范围含互联网销售等
- 字节投资AI设计服务提供商设序科技
- 三七互娱|三七互娱投资副总裁林均全加盟字节 任抖音生态战略负责人
- 飞利浦·斯塔克|《2021中国互联网广告数据报告》发布,受反垄断监管影响,阿里巴巴、腾讯广告收入增长放缓,字节跳动或赶超
- 字节跳动|两轮电动车市场生变:市值450亿的小米生态链企业,要挑战雅迪、小牛
- 字节跳动投资入股未斯科技 后者聚焦企业智能化数字平台