d揭秘:芝麻信用是怎么做的( 二 )
这意味着,构建这样的模型时要根据经验挑选覆盖各个维度的变量,并使其保持绝对的可解释性,而不光是选择区分度高的变量。前者是芝麻信用这种产品的视角,后者是A/B/C/F卡的视角。
你说企业内部也要用啊,不需要效果尽可能好才更好吗?
企业又不是只用这一个工具。
02我们来重点聊一聊芝麻信用的数据变量。
这个数据变量服务总共包含 65 个变量,按照芝麻信用评分维度(一级分类)和 DAS 变量类别(二级分类)分类如下: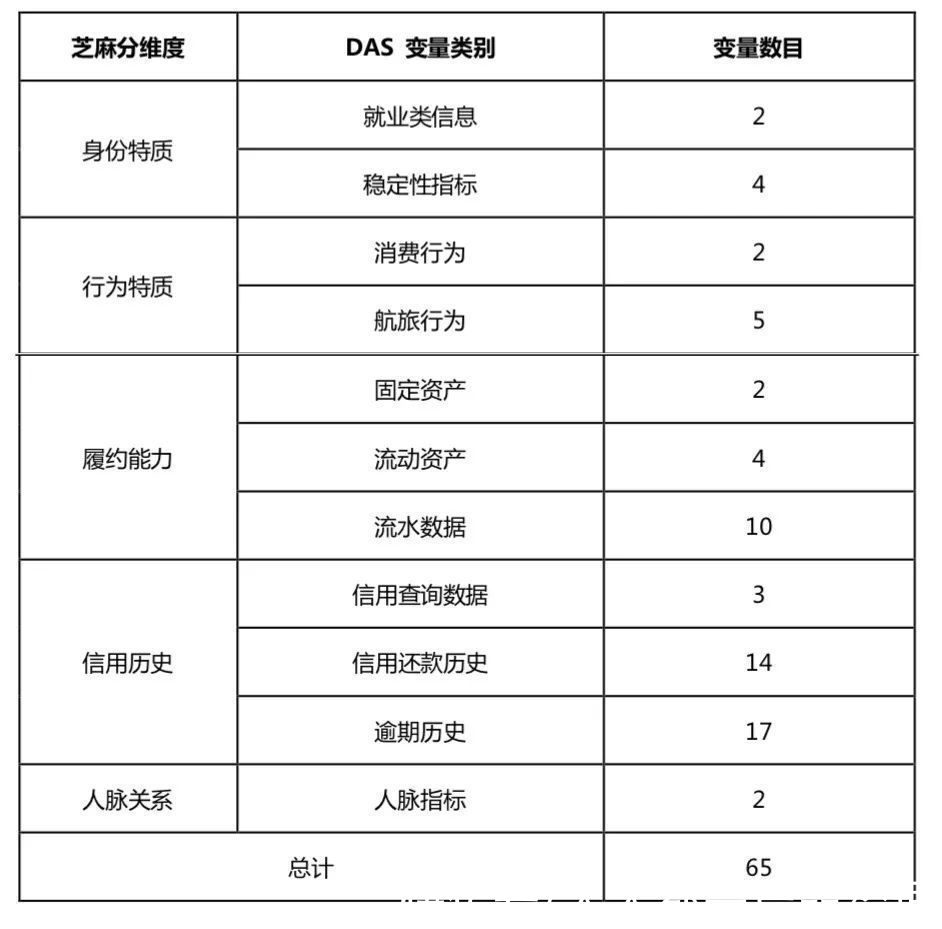
文章插图
如前所述,相信你对这五大维度一点也不吃惊。身份特质、履约能力体现了“收”,行为特质体现了“支”,信用历史体现了意愿,人脉关系也体现了违约的成本项。
图中变量数量,基本就体现了这些类别的重要程度。信用历史往往是最重要的,其次是履约能力。
同样的一万块钱,借给一个每次借钱下个月都及时还钱的人,比借给一个月入十万的人靠谱的多。
这 65 个变量进一步拆分为 8 个核心变量和 57 个基础变量。
这些变量的分段逻辑,按文档的说法是,综合考虑 DAS 变量在全量芝麻用户上的数值分布对好坏用户的区分度将其进行分段,最多分十五段。分段序号 01-15 代表变量数值由小到大的排列顺序。
我们详细看一看这8个核心变量,57个基础变量汇总放在后面。
文章插图
在身份特质项中,更核心的变量竟然是稳定性指标,而不是行职业信息。一方面是因为,行职业信息一般很难准确获取;另一方面,所在公司、所做职业是需要分类到大类上的,这类信息在住房按揭这种长期贷款中很重要,对短期借贷没有直接作用关系。不管是消费信贷,还是信用生活,还款能力的刻画完全不需要上升到行职业,反而稳定性指标更为重要。
文章插图
第三方支付的核心在于深度和广度,支付业务要看广度,对应的当然要看用户使用第三方支付的广度。行为特质中,支付活跃场景数就很好的体现了这个广度。而支付金额和资产等维度在下面的履约能力中体现。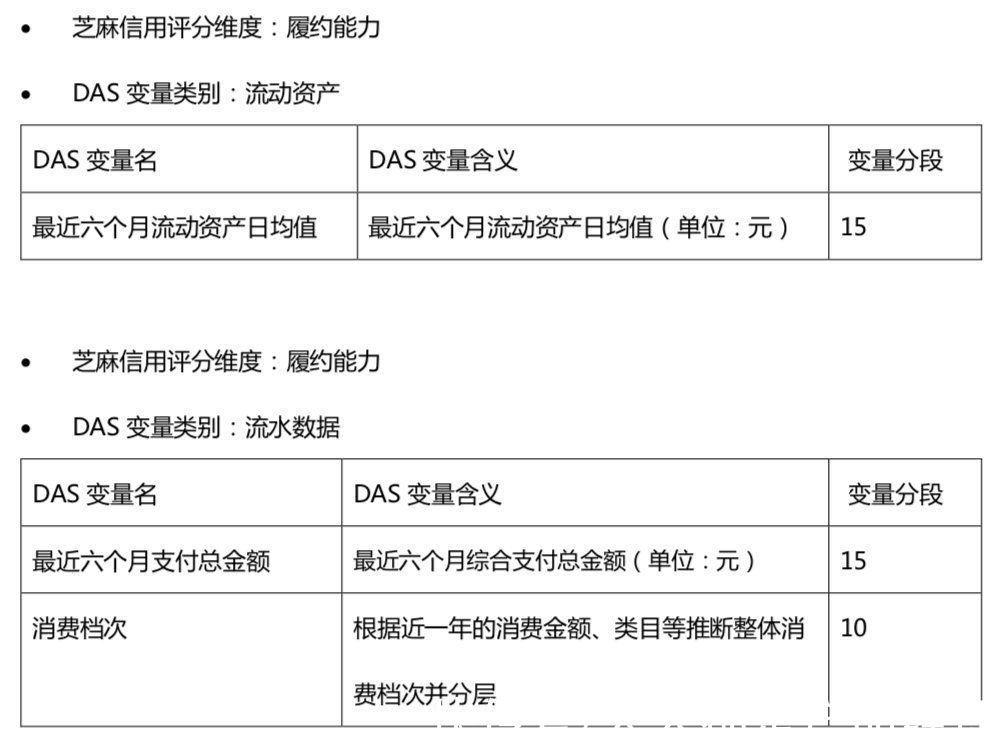
文章插图
履约能力选取了一个资产一个支出一个消费层次。资产和支出不必说,消费层次意义在于,只消费生活必须品,和对精神物品有强烈需求的,代表了不同的层级。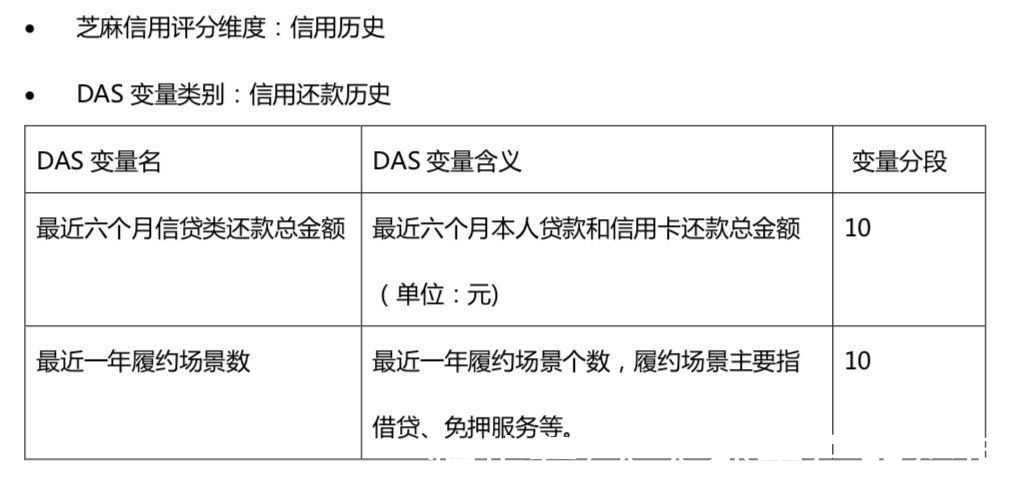
文章插图
信用历史中更为关注信用还款,而非逾期,我推测原因有二,一是还款类的信息丰富度会高很多,二是正面信息在面向用户可见的产品上更为友好,它既能一定程度上起到和负面信息类似的效果,在相对关系上负面降分和正面增分区别不大,还能激励用户更高频高额地借还。
剩余 47 个基础变量,我整理如下。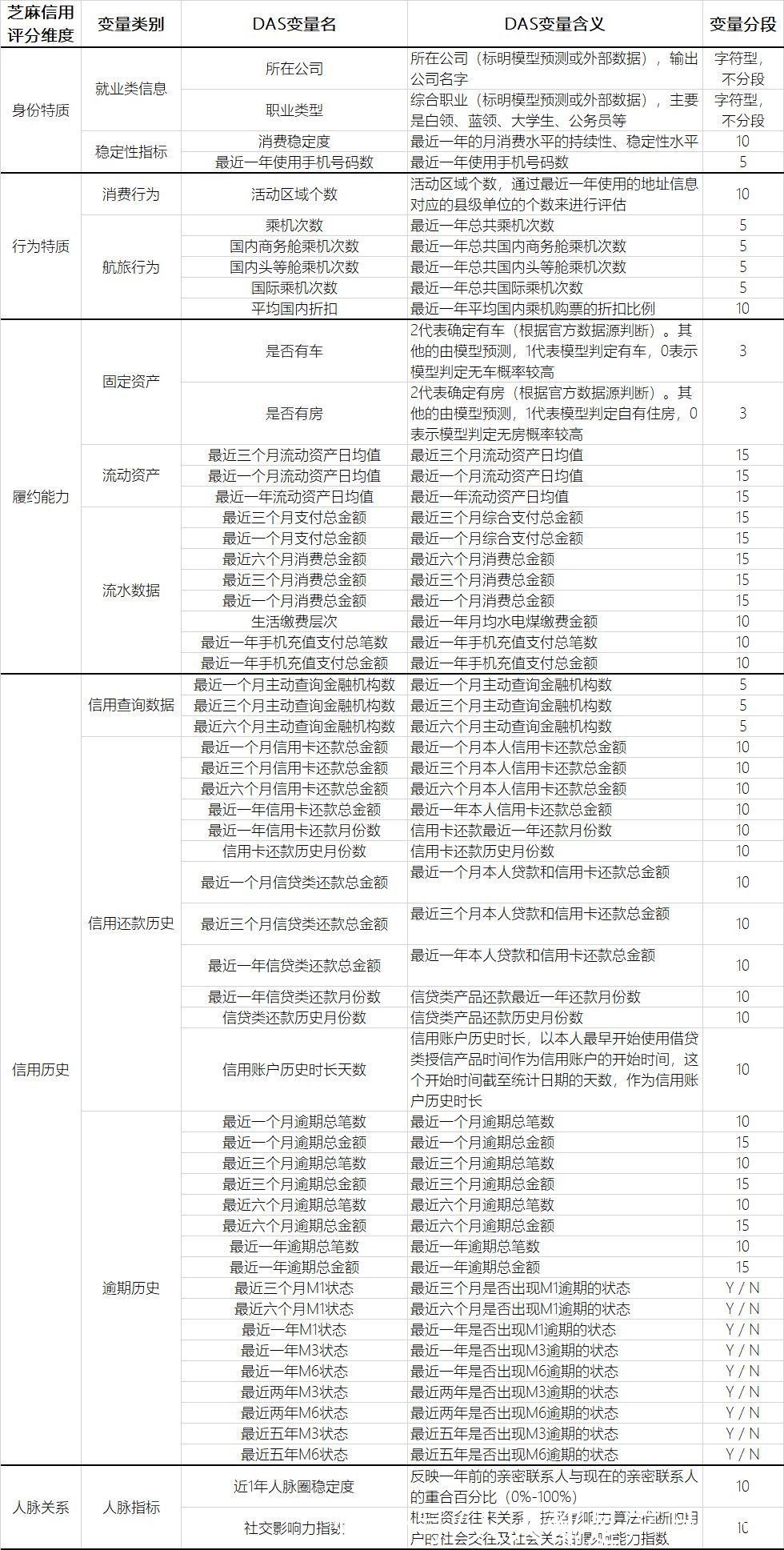
文章插图
上述变量除了选取的指标值得学习外,时间窗口也很值得注意。另外,显而易见,这些变量很多都是相关的,它们都会被用在芝麻分里面吗?它们怎么综合得到一个芝麻信用分呢?
当然是通过权重进行组合。
权重如何得到?
“综合考虑 DAS 变量在全量芝麻用户上的数值分布对好坏用户的区分度将其进行分段”,既然变量的分组是参考了好坏用户的区分度的,专业名词就是WOE,那变量的组合当然是对好坏用户进行建模得到。
但是,这些变量,高度相关的变量,是会被评分卡筛选掉的。有效的模型不可能用到了其中所有的变量,即使有,我推测,很多变量也是人为地被赋予了无关痛痒的权重。
- 空调|对话海信空调冯涛:空调到空气的战略革新,相信用户会有正确选择
- 自动驾驶计算|自动驾驶计算芯片制造商黑芝麻智能获得博世旗下博原资本战略投资
- 信用|北京 4 月起实施共享单车新规,骑车需实名认证
- 挖掘显示赛道,海信用“芯”了
- 20年的攻坚战!揭秘柔性屏第一股“维信诺”
- 肯德基有个“疯狂星期四”|有人5天连接48单代吃!揭秘“盲盒套餐”背后的那些事儿
- 孟凯的沉浮史:从餐饮首富到海外躲债,揭秘湘鄂情巨亏5.6亿背
- 智能|黑芝麻智能大算力芯片年内上车,首批车型将是自主品牌
- “2021创投成渝?发现金种子”结果出炉 揭秘这5家企业为何获大奖
- 安霸高管揭秘5nm自动驾驶芯片:500eTOPS算力从这来