智东西内参| 白皮书( 四 )
文章插图
光虹膜技术原理示意图
业务质量感知关键技术。 业务质量感知包括业务和网络两个方面, 实现对二层, 三层以及传输层时延、 丢包和抖动的监测; 通过 Telemetry 等技术实现运行数据实时订阅上报。
业界当前的业务质量检测/探测主要是带外探测技术, 业务检测/探测报文由相关功能模块单独发送和接收, 和用户实际业务流共用转发路径, 与业务报文分离不严格对应, 因此探测结果与实际业务体验有偏差。 针对这个缺点, 业界定义实现了 IOAM 等带内探测技术。 例如在原始数据报文中增加 OAM 检测头, 在业务转发路径中根据检测头进行数据采集, 再通过集中处理单元计算检测结果。 另外, 还可以通过测量业务报文的 TCP/UDP 传输特征, 来提取和计算报文及业务 KPI。 该方案的优势在于可以单节点部署, 可随流检测连接质量。
基于以上技术采集到的数据, 大致分为体验 KQI(卡顿率、 加载时间等) 和应用 KPI(时延、 抖动等)两层; 体验 KQI 可以参考行标 YDT 2691 的定义, KQI 指标一般需要在内容侧和终端侧直接度量, 部分应用的 KQI 也可以采用 DPI 方式进行测量, 但该方式依赖对应用层内容的解析, 定制化较强, 不具备通用性。由于体验 KQI 和应用 KPI 通常存在定性关系, 应用 KPI 可在传输层进行指标建模, 不依赖于具体应用, 具有更好的通用性。
2、云地协同全栈 AI 技术光网络 AI 技术研究面对模型泛化能力差、 模型部署要求算力高、 本地样本少/标注难、 大数据管理困难等问题, 需要探索一种新的 AI 技术架构应对这些问题, 加速 AI 应用的规模部署。 新的 AI 技术架构需要满足具有以下特点:
1) 针对模型泛化能力差问题: AI 模型应具有在线学习能力, 能够不断学习网络新特征、 新变化。
2) 针对模型部署算力要求高问题: AI 模型训练应可集中部署在算力中心或者支持分布式训练部署。
3) 针对样本少/标注难问题: 需要发挥群体智能, 多数据持有者之间相互贡献数据, 为 AI 模型在线学习提供坚实数据基础。
4) 针对大数据管理困难: 网络数据种类多、 产生数据快, 大量网元产生的 KPI、 日志、 告警等海量数据, 需要建立专业体系化的数据治理工程。
针对光网络多边缘设备+中心控制的组网特点, 云地协同 AI 技术架构是解决上述挑战的最佳解决方案。
云地协同是指云端和地端协作完成数据样本上云、 模型状态管理、 模型重训练、 模型/知识下发、 择优更新等一系列的闭环任务, 同时把云端汇集的全局网络知识经验、 全量数据训练得到的高精度模型, 持续注入地端, 让光网络 AI 能够进行智能迭代升级, 变得越来越聪明, 如下图所示。
AI 服务包含数据治理服务、 模型训练服务、 专家经验辅助服务, 涉及运营商大量运营数据、 用户数据、网络数据, 对数据安全要求很高, 云端适合部署在 IT 云。 实时海量数据并发上报、 处理加剧整网压力,在地端(包含管控系统、 网元设备) 部署分布式 AI, 就近处理本地实时海量数据。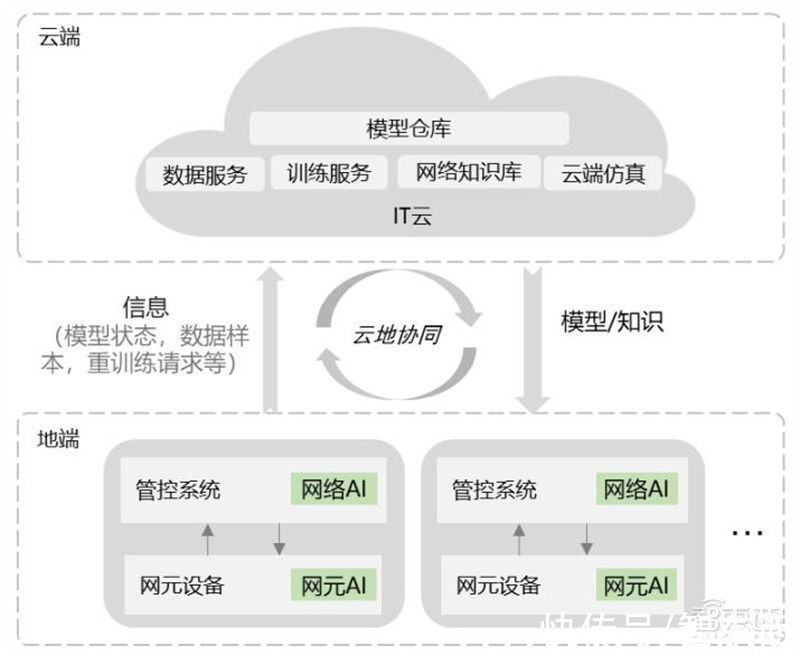
文章插图
云地协同全栈 AI 示意图
3、智能分析预测技术网络出现问题后生成告警, 触发故障定位和修复是当前网络运维的普遍方式, 海量告警上报导致故障根因定位困难、 静默故障无告警上报导致无法定位故障根因, 是根因告警分析的两大难题。 为了进一步提升网络可靠性和运营效率, 对网络故障、 业务资源需求等进行提前预测, 也是当前研究的热点问题。
智能关联分析是光网络根因告警分析和静默故障定位的关键能力。 由于网络数据量大、 维度多和故障模式多样化, 且关联影响发散, 需要精准的筛查和多维度关联分析能力, 需要通过智能分析技术, 构建关联模型和进行相关训练, 实现根因告警识别和静默故障定位。 智能资源预测和故障风险预测可提前发现资源瓶颈和故障风险, 提升业务 TTM 和业务可靠性。
- 荣耀|今年过节不乱跑,荣耀智慧屏1499起,和年夜饭一样真香
- 苹果|国内首款支持苹果HomeKit的智能门锁发布:iPhone一碰即开门
- CPU|元宇宙+高端制造+人工智能!公司已投高科技超100亿,股价仅3元
- 智能|地震救人新突破!中科院研制出触嗅一体智能仿生机械手
- 智能制造|企业转型的新时代,夹缝中求生存
- DeepMind首席科学家:比起机器智能,我更担心人类智能造成的灾难
- Aqara 智能门锁 A100 Pro 发布:支持苹果“家庭钥匙”解锁
- 资讯丨智能DHT+高阶智能驾驶辅助,魏牌开启“0焦虑智能电动”新赛道
- 智能手机|全球第17位!App Annie报告:2021年中国人均每天用手机3.3小时
- 赵明路|华为终端申请注册鸿蒙智联商标,国际分类涉服装鞋帽