源1.0|源1.0开源开放,AI大模型再也不是“头部玩家”的奢侈品( 四 )
文章插图
很多NLP大模型展示的是写文章、写新闻、写摘要、编程序等炫酷的应用,然而AI真正的应用场景却不是这些,相反,AI应用在我们的生活、工作和学习中无处不在,大多数都跟NLP有关:电商平台的智能客服、搜索引擎的智能搜索、短视频平台的千人千面、移动办公IM的智能会议纪要、智能设备的语音助理……底层都是NLP技术。
源1.0专注于NPL,却可面向多场景帮助开发者完成AI任务,在算法上其进行推理方法创新,进一步提升模型泛化能力,以更好地服务不同应用,实现“产学研用”的全场景覆盖。有着中文数据集的独特优势,拥有领先业界的参数规模、计算精度和训练效率,再加上较强的通用性,开源开放的源1.0有望成为产业挖掘AI大模型潜力的基础设施。
文章插图
AI大模型开放之路去向何方?各路科技巨头卯着劲建设AI大模型,将不会只将其用在各类AI竞赛的榜单争夺上。基于“强大的技术储备势必会形成溢出效应,最终以各种形式走向开放”这一逻辑,巨头们在纷纷布局AI大模型后,最终走向开放以及开源应该说是必然,就像它们在深度学习框架上走过的路一样。
那么,AI大模型开放开源的趋势是什么?
首先,AI大模型的发展趋势将是算力、算法与数据三位一体的高度融合。
AI大模型要走向工业化,提高性能、精度、效率与通用性,需要算力、算法与数据“三位一体”的高度协同。AI大模型需要在大规模计算集群上训练,提高大规模计算集群的计算效率至关重要。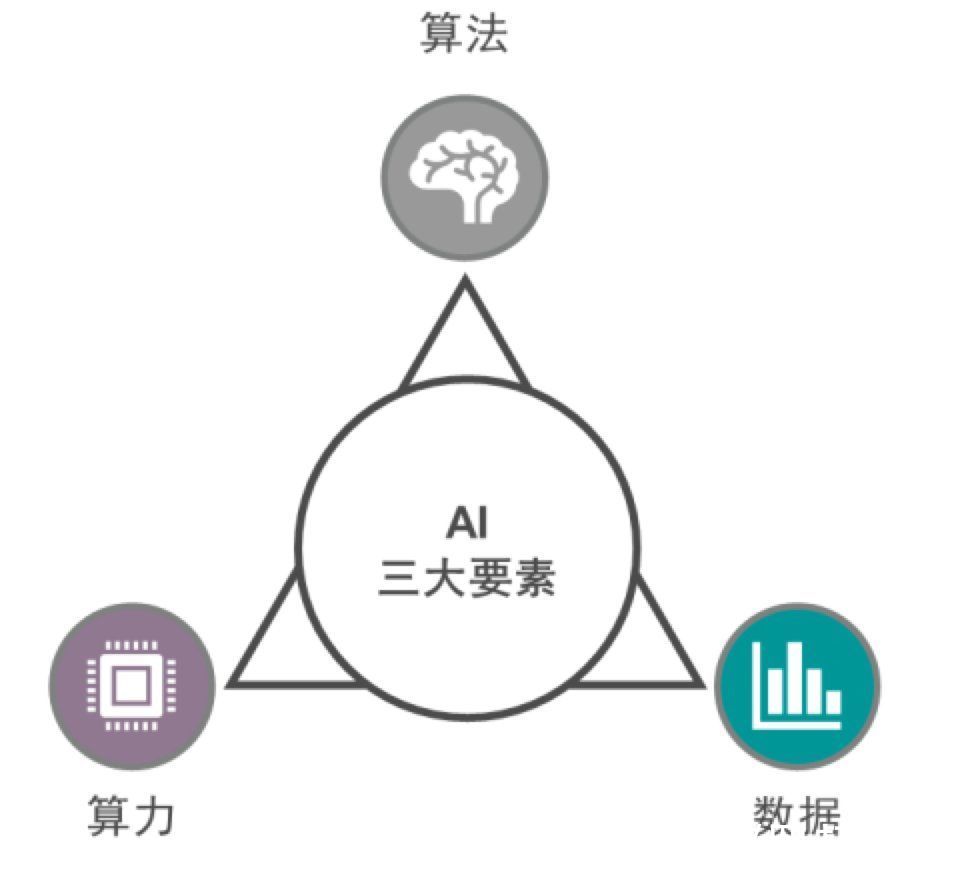
文章插图
源1.0表现出色的一大关键就是重视软硬件特别是算力、算法和数据的高度融合发展,其在模型分布式计算等各个层面上进行协同方面的一些设计、优化。
浪潮是智慧计算的主导者。算力层面浪潮在异构加速计算、大规模计算集群、AI服务器等领域有深厚积累,AI服务器市占率位居全球第一,中国市场连续四年占比超50%。算法层面浪潮积极布局深度学习框架等AI算法技术,推出Caffe-MPI、TensorFlow-Opt、全球首个FPGA高效AI计算开源框架TF2。浪潮在全球顶级AI赛事上率获佳绩,2020年在AI领域的专利贡献达到1174件,位居中国前列。
作为浪潮智慧计算战略的一环,源1.0是在浪潮AI算力与算法上的厚积薄发,其进行了大量的算法算力协同优化,优化巨量模型结构,使模型更利于AI算力性能发挥,大幅提升计算效率,在同比算力提升12%的情况下,参数集规模提升40%,达到业界第一训练性能的同时实现了精度的领先。
不只是源1.0,商汤科技推出的SenseCore商汤AI大装置同样强调算力、数据与算法的融合,其计算峰值速度达到3740 Petaflops,集大数据、大模型和超强算力三位一体。可以展望,未来AI大模型或许将与量子计算、超级计算机等计算技术融合发展,进一步提高训练效率和AI性能。
其次, AI大模型要重视工业化场景,在软硬件上进一步深度结合,所见即所得。
AI大模型现在有些过度追求参数规模、数据集大小或者算力模型性能等单一指标。浪潮人工智能研究院首席科学家吴韶华说,AI大模型“大不是目的,通用智能才是,因为AI的下一步是从系统1到系统2,从感知到认知,从专用智能走向通用智能。”而AI大模型的“大”可以带来算法、结构的改进,以及前沿技术的探索。
AI大模型的终点还是通用智能的应用,因此AI大模型设计时就要预先重视工业化需要关注的点。优秀的AI大模型要面向行业场景,重视软硬件结合,包括与芯片等底层计算模块结合,提升各方面能力,这样才能减少应用侧的算力负担、开发成本、应用成本和运行时间,甚至像云计算一样“所见即所得”地按需调用。
- 供冷供热约占全球终端能源消耗的50%|吸附式制冷材料研究取得进展
- 运营商|手机六连靓号被运营商回收,拒绝补贴20万,运营商:浪费资源
- 化州市富美家电维修店整合行业招商运营资源的专业平台
- it|浪潮宣布加入 OpenCloudOS 操作系统开源社区
- 本文来源于微信公众号有趣青年(ID:v_danshen)“一分钟聊‘青年理想城市’”互动...|“我不敢在微信上表白。”
- 锐龙|为什么AMD只推出一款锐龙7 5800X3D?因为资源都优先给Milan-X了
- 蔚来发布Aspen 3.1.0更新 强化蓝牙链接功能/增加动态透明底盘
- 昌江区珠山区区县服务商整合行业招商运营资源的专业平台
- 买斗整合行业招商运营资源的专业平台
- 来源:楚天交通广播、微博、中新经纬版权归原作者所有|热搜第一,微信上线新功能!