源1.0|源1.0开源开放,AI大模型再也不是“头部玩家”的奢侈品( 三 )
在计算效率上,源1.0训练用了2128张GPU、且在16天内就完成了训练,看上去是不小的算力和时间投资,不过相对同等量级的AI大模型效率却高了不少。“巨无霸”“MT-NLG”的训练需要的算力相当于4480块A100显卡,GPT-3的训练则是在超过28.5万个CPU核心以及超过1万个GPU上完成,训练时间均超过一个月。源1.0的训练共消耗约4095PD(PetaFlop/s-day),相较于“GPT-3”的3640PD,计算效率得到大幅提升。源1.0做到这一点的核心原因在于其采用了张量并行、流水线并行和数据并行的三维并行策略,这背后则是用好了浪潮智慧计算的“看家本领”。
其次,要有显著的差异化能力。
AI大模型只比拼参数远远不够。巨量数据与巨量算法一样重要,因此更要关注数据集特性与质量。源1.0在中文数据集上有独到优势,是最大的中文AI大模型,其爬取2017-2021近五年来中文互联网的全部网页数据、公开中文语料库、中文百科及电子书等,经过清洗及处理,最终获得5000GB高质量数据集,是GPT-3的近10倍,成为迄今业界最大的高质量中文数据集,拥有2000亿个词。
源1.0强调中文,这对我国的AI产业化意义非凡。中文数据集相对于英文数据集而言少得可怜。由于西方世界AI技术发展较早且参与者众多,因此英文高质量文本数据集相当丰富,知名的有HackerNews、Github、Stack Exchange、ArXiv以及基于YouTube字幕生成的The Pile,比如The Pile有着包含825GB的多样化开源语言建模数据,中文数据集最大开源项目CLUECorpus2020只包含100GB高质量数据集。源1.0的5000GB高质量中文数据集,补齐了AI大模型中文数据集短板。
文章插图
不过,中文NLP难度更大。中文是世界上最博大精深的语言,有着不同的分词方式、同一词组不同歧义以及新词汇等挑战,比如“武汉市长江大桥”就可以有截然不同的语义,机器训练难度比同等量级的英文大得多。
通过大量的研发工作,在强大的算力支持下,源1.0在精度上表现出色,在语言智能上表现优异,获得权威中文语言理解评测基准CLUE榜单的零样本学习和小样本学习两类总榜冠军。其对零样本和小样本支持较强,更适合不同场景的应用,其在零样本学习榜单中超越业界最佳成绩18.3%,在文献分类、新闻分类、商品分类、原生中文推理、成语阅读理解填空、名词代词关系6项任务中获得冠军;在小样本学习文献分类、商品分类、文献摘要识别、名词代词关系等4项任务获得冠军。在成语阅读理解填空项目中其表现超越人类。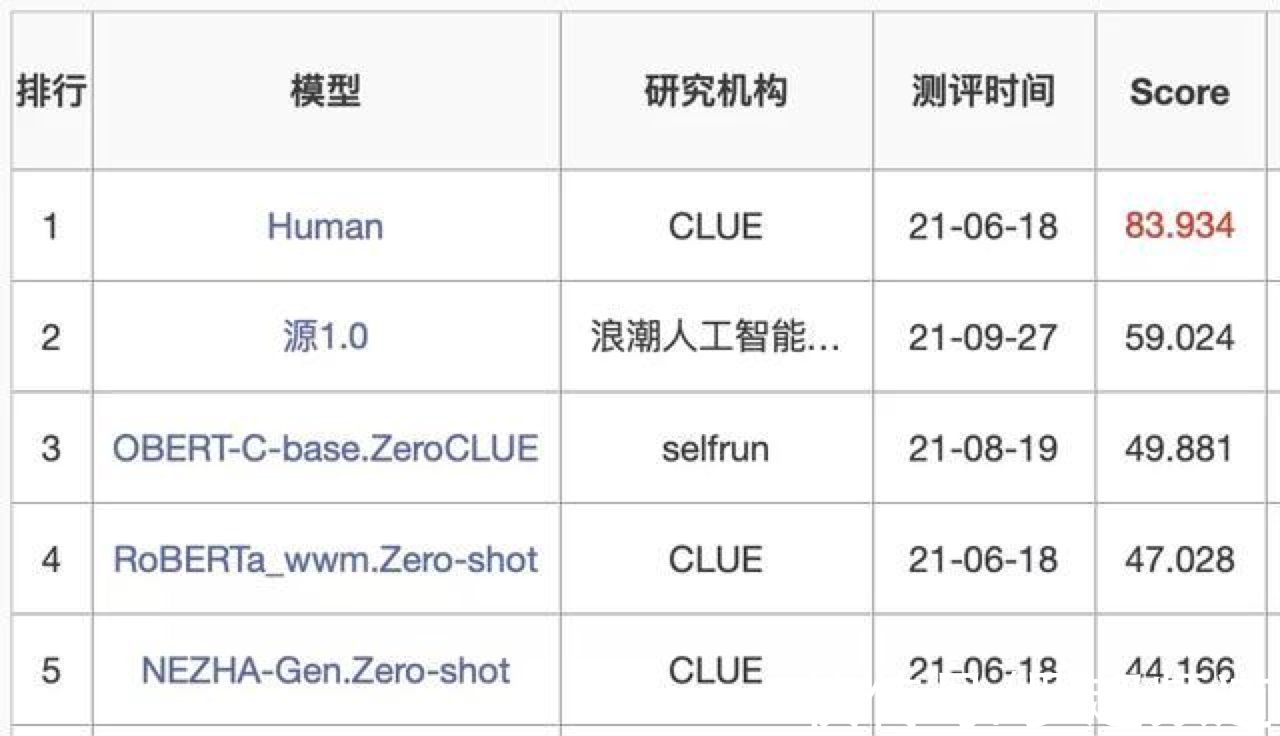
文章插图
而在对“源1.0”进行的“图灵测试”中,将源1.0模型生成的对话、小说续写、新闻、诗歌、对联与由人类创作的同类作品进行混合并由人群进行分辨,人群能够准确分辨人与“源1.0”作品差别的成功率已低于50%,换言之,超过一半的情况下人群根本无法分辨是源1.0的机器创作还是专人创作,这一指标在AI大模型中属于领先水平。
文章插图
最后,要有较高的通用性。
一些科研院校的AI大模型走向了极致化的发展方向,在特定维度发力,通用性较差,只能用于小众学术圈,难以工程化,沦为一次性模型,浪费大量资源,与AI大模型的初衷背道而驰。开源开放的AI大模型则要有较高的通用性,以适应更多场景。
作为专注于自然语言技术的AI大模型,源1.0具有广泛的应用场景。NLP是“AI技术皇冠上的明珠”,不只是因为NLP是最难的AI技术之一,而是因其关系到知识图谱、语义理解和认知智能等AI技术,每一项都是AI从弱AI跨越到强AI的关键。
- 供冷供热约占全球终端能源消耗的50%|吸附式制冷材料研究取得进展
- 运营商|手机六连靓号被运营商回收,拒绝补贴20万,运营商:浪费资源
- 化州市富美家电维修店整合行业招商运营资源的专业平台
- it|浪潮宣布加入 OpenCloudOS 操作系统开源社区
- 本文来源于微信公众号有趣青年(ID:v_danshen)“一分钟聊‘青年理想城市’”互动...|“我不敢在微信上表白。”
- 锐龙|为什么AMD只推出一款锐龙7 5800X3D?因为资源都优先给Milan-X了
- 蔚来发布Aspen 3.1.0更新 强化蓝牙链接功能/增加动态透明底盘
- 昌江区珠山区区县服务商整合行业招商运营资源的专业平台
- 买斗整合行业招商运营资源的专业平台
- 来源:楚天交通广播、微博、中新经纬版权归原作者所有|热搜第一,微信上线新功能!