https|京东云语音语义领域8篇论文被国际顶会发表( 三 )
文章插图
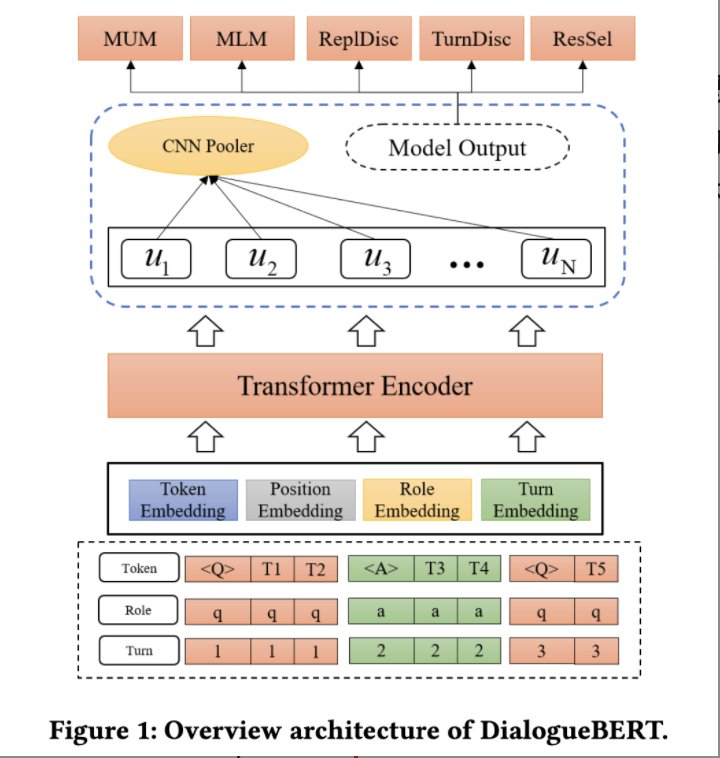
Experimental Result:实验证明我们的模型相比其他面向对话的预训练模型,可以较好的改进意图识别、实体识别以及情绪识别等下游对话理解任务的表现。DilaogueBERT直接利用海量无监督对话数据进行自监督学习,证明了基于对话语料的预训练的可行性。相比传统的基于监督学习的编码器和基于通用自然语言模型的编码器,DialogueBERT准确率更高,能够获得更加鲁棒的对话编码效果。本文还分析了多种针对自监督学习的任务特点,对于未来的对话自监督编码研究具有一定借鉴意义。
论文标题:Multi-hop Attention Graph Neural Networks
论文链接:https://arxiv.org/abs/2009.14332
发表刊物:IJCAI 2021
Motivation: 目前基于注意力机制的图神经网络中的Attention仅局限于直接邻居,因此每一层的感受域只局限在单跳结构中,学习多跳结构信息需叠加更多的层数,然而更多层数通常会带来过平滑问题(Over-smoothing Problem)。同时这些Attention的计算只与节点表示本身有关,并没有考虑到图结构的上下文信息,而将多跳近邻结构化信息考虑到图神经网络的注意力计算很少被研究。
Solution: 本论文提出一种基于多跳注意力机制的图神经网络模型(MAGNA),包括图注意力扩散模块, 深层Feed Forward聚合模块,Layer Normalization以及残差链接,基于图扩散(Graph Diffusion)的注意力计算,能够在单层图神经网络中具有多跳结构的感受域。同时给出了基于谱特征分析,证明多跳diffusion attention相比单跳attention具有更好的图结构学习能力。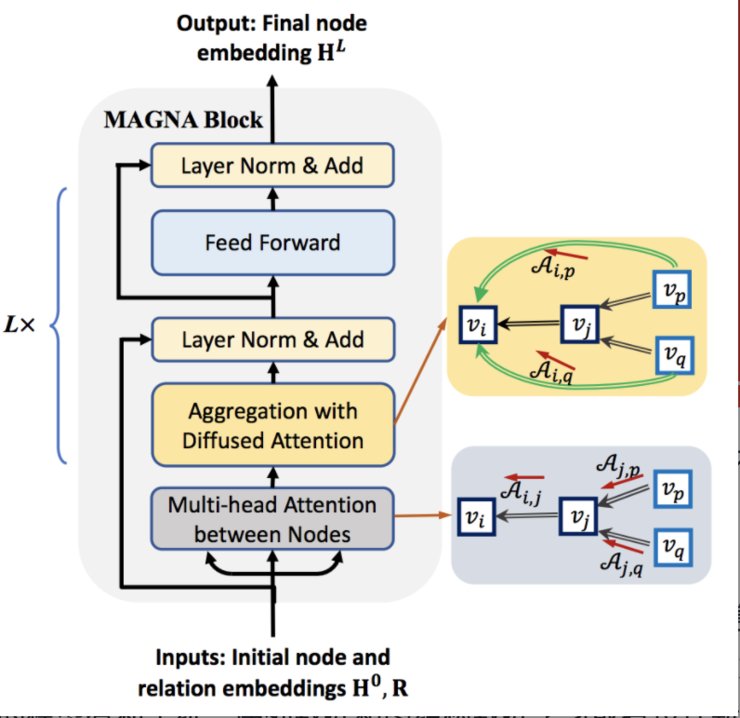
文章插图
Experimental Result:本论文提出的模型,在半监督图节点分类问题以及知识图谱补全任务上均取得SOTA的性能,同时能够解决深层图神经网络通常出现的过平滑问题。
Impact: 基于图扩散注意力计算是将稀疏图信息和自注意力计算统一到一个模型中的关键步骤,在避免过拟合的同时提高了模型性能,并且只引入了常数因子的训练时间开销。自注意力机制在序列(如NLP)数据上取得巨大成功,而基于图扩散的注意力机制在计算任何两点之间的注意力的同时兼顾到结构信息。因此,本论文提出的模型有利于统一序列数据和图结构数据学习或者设计新的算法在考虑结构化信息的同时进行序列分析(如将语法树信息融合进文本情感分析/利用Diffusion Attention方法实现稀疏化Transformer)。
论文标题:Incremental Learning for End-to-End Automatic Speech Recognition
论文链接:https://arxiv.org/abs/2005.04288v3
发表刊物:ASRU 2021
Motivation: 语音识别增量学习旨在保留模型原有识别能力的同时,提高其在新场景下的语音识别能力,具有广泛的应用价值。然而,在模型原始训练数据因隐私、存储等问题而不再可用的情况下,语音识别模型在增量学习过程中往往面临“灾难性遗忘”。
Solution: 本论文提出了一种新的基于模型可解释性的知识蒸馏方法,并将其与基于模型输出响应的知识蒸馏方法相结合,以使得在仅采用新场景数据进行语音识别增量学习的过程中,保留原模型的输出结果和得到该输出结果的“原因”,从而有效抑制模型对原有知识的遗忘。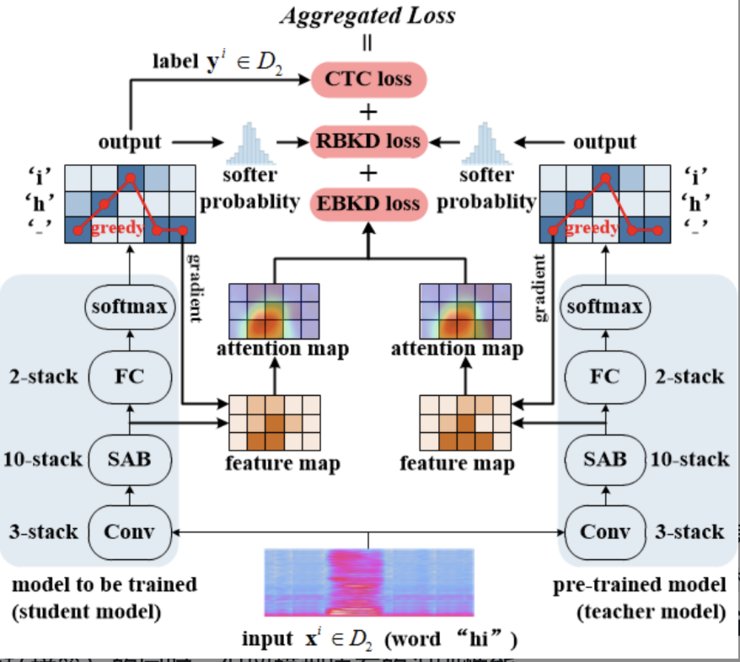
文章插图
Experimental Result:在开源数据集和实际应用场景数据集上的增量学习实验结果表明,在抑制模型对原有知识的遗忘方面,本论文方法显著优于现有方法。本论文提出的方法在无需访问模型原始训练数据的条件下,仅利用原模型和新场景的语音数据进行增量训练,能够在让模型快速适应新任务场景(如新口音、新术语、新声学环境等)的同时,保留模型原有的识别性能。
- 副董事长|京东方A董秘回复:公司与全球数千家供应商保持着良好的合作关系
- 京东|适合过年送长辈的数码好物,好用不贵+大牌保障,最后一个太实用
- 酷睿处理器|关键数据出炉,京东比阿里差远了
- 芯片|上市仅4个月,跌价1000元,微云台主摄+6nm芯片+4400mAh
- 京东正式上线“年礼无忧”服务
- 计算|雄安城市计算(超算云)中心主体结构封顶
- 百度|马化腾的一句话,腾讯市值一小时暴涨1400亿港币,马云格局还是小了
- 封顶|雄安新区:城市计算(超算云)中心提前完成主体结构封顶
- 封顶|雄安新区:城市计算(超算云)中心提前完成主体结构封顶
- CPU|阿里反贪第一人蒋芳,入职23年将7名高层送入狱,连马云都可以查