https|京东云语音语义领域8篇论文被国际顶会发表( 二 )
文章插图
表1:ROUGE scores on the CNN/DailyMail dataset.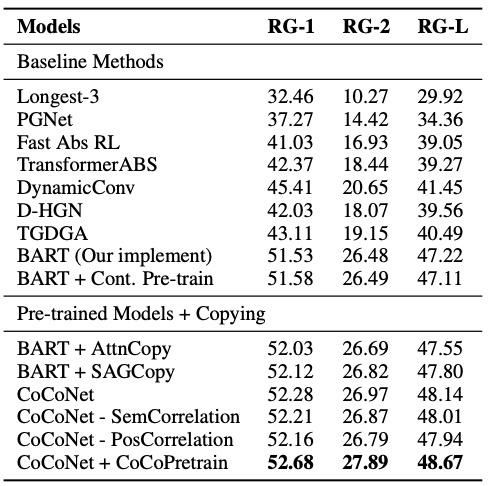
文章插图
表2:ROUGE scores on the SAMSum dataset.
论文标题:K-PLUG: Knowledge-injected Pre-trained Language Model for Natural Language Understanding and Generation in E-Commerce
论文链接:https://arxiv.org/abs/2104.06960
发表刊物:Findings of EMNLP 2021
Motivation: 预训练语言模型在多个NLP任务展示出超越非训练语言模型的效果。然而,预训练语言模型在领域迁移过程中,性能会受到影响。特定领域的预训练语言模型对该领域的下游应用会有很大帮助。
Solution: 本论文为电商领域设计了一个大规模预训练语言模型,定义了一系列电商领域知识,包括产品词、商品卖点、商品要素和商品属性。并针对这些知识,提出了相应的语言模型预训练任务,包括面向知识的掩码语言模型、面向知识的掩码序列到序列生成、商品实体的要素边界识别、商品实体的类别分类、商品实体的要素摘要生成。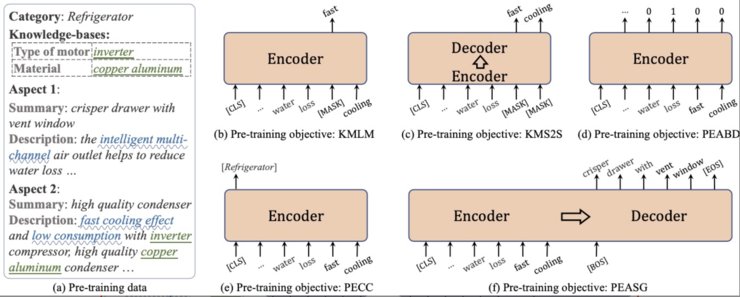
文章插图
Result:本论文提出的预训练语言模型可应用于多个电商领域的文本理解和生成任务,在包括电商知识图谱补齐、电商客服多轮对话、商品自动文摘等多个任务上取得最佳性能。
论文标题:RevCore: Review-Augmented Conversational Recommendation
论文链接:https://arxiv.org/abs/2106.00957
发表刊物:Findings of ACL 2021
Motivation: 对话推荐系统(Conversational Recommender System)是基于自然语言的多轮对话理解用户的需求和偏好,并根据当前动态的需求和偏好推荐商品和服务。对话推荐系统中长期存在2个挑战。1)对话中信息量较少导致的推荐准确度较低的问题; 2)数据收集过程缺乏专业性导致生成的对话回复信息量较少的问题。
Solution: 本论文提出使用非结构化的评论作为外部知识缓解对话推荐系统中由于信息量较少而存在的推荐准确度低且回复话术信息量不足的问题。该方法首先突破了非结构性文本(评论)与结构化知识(知识图谱)在对话推荐系统的技术性融合的问题。其次,通过在对话推荐过程中检索出情感一致的评论,进一步提高对用户推荐的契合度。本论文提出的RevCore系统框架图如下图。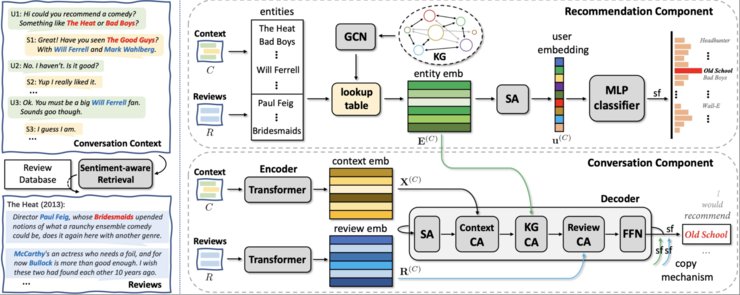
文章插图
Experimental Result: 本方法在保证外部文本与原始数据逻辑一致的前提下,在对话质量和推荐质量上均有较大提升。情感一致的用户评论的引入,首先提高了推荐系统的准确度。此外,由于更加丰富的实体信息以及适当的建模方式提高了对话回复的多样性和丰富度。该框架可较好的应用在工业界的对话推荐系统中,包括智能客服、智能家居、智能对话机器人等。该框架还具有较强的可移植性,RevCore在电影对话推荐领域获得的提升,将给予其他各个行业启发,利用外部评论数据创造更好的对话推荐引擎,提供更好的行业服务。
论文标题:DialogueBERT: A Self-Supervised Learning based Dialogue Pre-training Encoder
论文链接:https://arxiv.org/abs/2109.10480
发表刊物:CIKM 2021
Motivation:对话文本由于其特殊的角色信息和层次化结构,普通的文本编码器在对话任务的下游任务中往往不能发挥最好的效果。在这篇文章中,受到自监督学习在NLP任务中广泛应用的启发,我们提出了基于自监督学习、面向对话的预训练模型DialogueBERT。
Solution:这篇论文提出了五个面向对话的自监督预训练任务,包括消息掩码建模、单词掩码建模、消息替换建模、消息顺序交换建模、答复对比建模,基于Transformer模型架构,利用海量对话数据进行预训练,抽取其中的单词、对话轮次、对话角色信息作为输入,学习对话文本的上文结构信息和对话场景语义表示。
- 副董事长|京东方A董秘回复:公司与全球数千家供应商保持着良好的合作关系
- 京东|适合过年送长辈的数码好物,好用不贵+大牌保障,最后一个太实用
- 酷睿处理器|关键数据出炉,京东比阿里差远了
- 芯片|上市仅4个月,跌价1000元,微云台主摄+6nm芯片+4400mAh
- 京东正式上线“年礼无忧”服务
- 计算|雄安城市计算(超算云)中心主体结构封顶
- 百度|马化腾的一句话,腾讯市值一小时暴涨1400亿港币,马云格局还是小了
- 封顶|雄安新区:城市计算(超算云)中心提前完成主体结构封顶
- 封顶|雄安新区:城市计算(超算云)中心提前完成主体结构封顶
- CPU|阿里反贪第一人蒋芳,入职23年将7名高层送入狱,连马云都可以查