数据库|向量将死,哈希是 AI 未来

文章插图
事实上,人工智能的许多领域都可以从向量变为基于哈希的结构,带来飞跃的提升。本文将简要介绍哈希背后的应用逻辑,以及它为什么可能会成为 AI 的未来。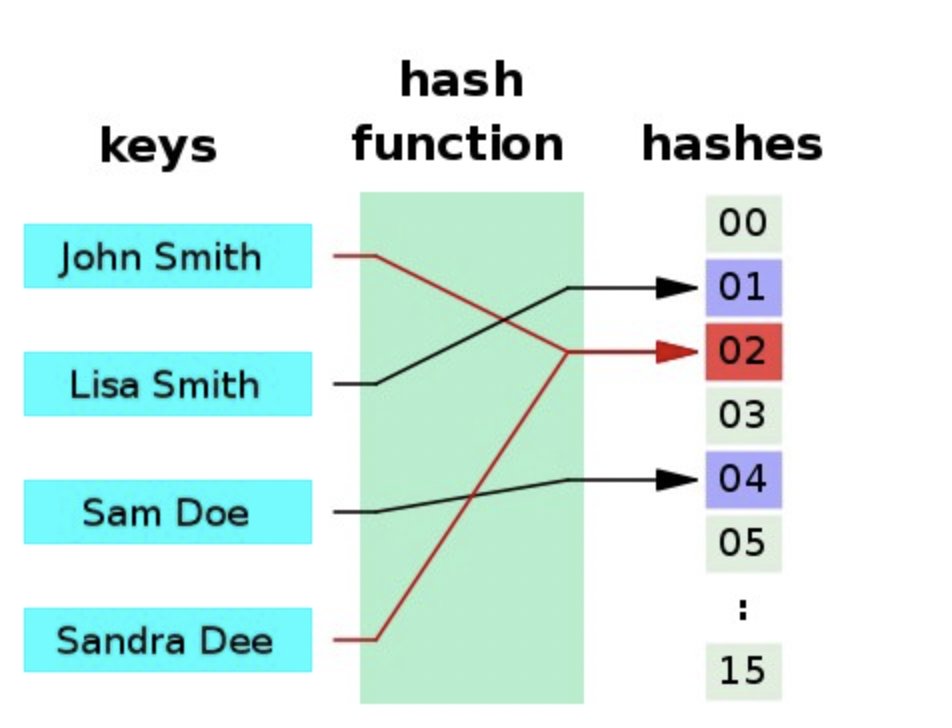
文章插图
哈希在数据的准确性识别、数据存储大小、性能、检索速度等方面具有突出的优势。更重要的是,它们本质上是概率性的,因此多个输入项可以共享相同的哈希值。
在向量表示中,浮点数往往是首选的数据表示形式,尽管它们在本质上比哈希更绝对,但它们却并不精确。
对于微小的数值变化(关于向量计算),二进制表示也可以有很大的不同,这些数值变化对模型预测几乎没有影响。
例如:取 0.65 vs 0.66 在 float64(64 位浮点)二进制中可以分别用这两个二进制数表示:
- 11111111100100110011001100110011001100110011001100110011001101
- 11111111100101000111101011100001010001111010111000010100011111
对于神经元来说,这听起来像是一件愚蠢的事情,人类的大脑肯定不会这样工作,它们显然不会使用浮点二进制表示来存储数字,除非有人可以记住圆周率小数点后六万多位。
事实上,我们的大脑神经网络是非常形象的,在处理复杂的小数和分数方面非常擅长。但是,当我们算到一半或四分之一时,就会立即想象出一些东西,比如半杯水、四分之一杯水或者披萨等其他东西,可能根本没有想到尾数和指数。
一个常用的提高浮点运算速度和使用更少空间的方法是将分辨率降低到 float16(16位),甚至是float8 (8位),它们的计算速度非常快,但缺点是,它会造成分辨率的明显下降。
由于浮点数运算很慢,所以它真的没有一点优势吗?
答案是否定的。芯片硬件和它们的指令集被设计来提高效率,并使更多的计算并行处理,而 GPU 和 TPU 现在正在被广泛使用,因为它们处理基于浮点的矢量算法更快。
研究表明,有一系列哈希算法的确可以做到这一点,它被称为局部敏感哈希(LSH)。原始项越接近,其哈希中的位也越接近相同。

文章插图
- 数据库|OPPO悄悄上新机,骁龙8核+5000mAh电池,256G仅售1599元
- 数据库|丁磊致歉“鱼眼观察”作者并回应:已撤回删稿函
- 数据库|刘强东:如果我失去对京东的控制权,我立刻把京东卖了
- 数据库|国产数据库后浪崛起,OceanBase如何打入千行百业?
- oce国产数据库后浪崛起,OceanBase如何打入千行百业?
- 数据库|抖音、快手走上了阿里、京东的老路
- 小米 12/Pro 即将全球发布,已出现在印度尼西亚电信数据库中
- 数据库|大淘宝更重视直播了,中小商家如何掘金?
- S7-1200/1500连接MS SQL数据库
- 数据库|下一个“双十一”?电商巨头疯狂烧钱,春节大战薅羊毛机会来了!