巨量|巨量模型时代,浪潮不做旁观者:2457亿,打造全球最大中文语言模型( 三 )
在“源1.0”的图灵测试中,将模型生成的对话、小说续写、新闻、诗歌、对联与由人类创作的同类作品进行混合并由人群进行分辨,测试结果表明,人群能够准确分辨人与“源1.0”作品差别的成功率已低于50%。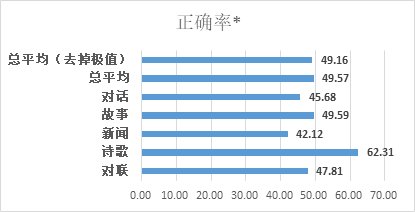
文章插图
如图,受访者的平均误判率为50.84%,在新闻生成领域误判率高达57.88%。
而抛开数据,源1.0的诗歌、对联的作品确实让人惊艳
五湖四海皆春色,三江八荒任我游
春来人入画,夜半月当灯
和风吹绿柳,细雨润青禾
三江顾客盈门至,四季财源滚滚来.
疑是九天有泪,
为我偷洒。
【 巨量|巨量模型时代,浪潮不做旁观者:2457亿,打造全球最大中文语言模型】滴进西湖水里,
沾湿一千里外的月光,
化为我梦里的云彩。
巨量模型的潜力炼大模型热潮的兴起,离不开谷歌微软、OpenAI、智源研究院等全球顶级科技企业和研发机构的追逐和热捧,在它们看来,巨量模型代表了实现通用人工智能最具潜力的路径,代表了当前传统产业实现智能化转型的新机遇.
而这次,浪潮重磅发布中文单体大模型源1.0,通过图灵测试和小样本学习能力再次印证了业界对超大模型潜力的普遍期望.前者为模型推理\走向认知智能提供了可能性,后者降低了不同场景的适配难度,提升了模型的泛化应用能力。相信未来这股"浪潮"还会越来越汹涌.
雷锋网雷锋网雷锋网
- 一个时代的结束!中国移动:10086 App将于1月30日起
- 智能制造|企业转型的新时代,夹缝中求生存
- 互联网时代|原极狐汽车总裁被挖至小米 担任小米汽车副总裁
- 在2021大中华区艾菲国际论坛上|玛雅文化施葵:新消费时代,如何助力品牌跑出“破圈”加速度?
- 互联网时代|华为走的是合作路线,跟传统厂家现在主打,物联网万物互联的模式
- 微商|朋友圈终于变干净了!网友:微商时代的终结
- 资费|中国关停国内的这些网络,500万人将失去通信,美国高通时代已过
- 对比度|大屏时代,MiniLED概念会成功领跑吗?
- 飞利浦·斯塔克|原价买显卡时代即将来临!英伟达:今年火力全开加大显卡产能
- Web3.0时代,数字人如何突破规模落地三大难点?百度李士岩:两