巨量|巨量模型时代,浪潮不做旁观者:2457亿,打造全球最大中文语言模型
战鼓催征千嶂寒,阴阳交会九皋盘。
飞军万里浮云外,铁骑丛中明月边。
看到这首诗歌,有超过50%的人误以为是人类的杰作
但其实,它出自巨量模型 源1.0
经过图灵测试认证,源1.0 写诗歌、写对联、生成新闻、续写小说的能力已经让人类的平均误判率达到了50.84%。(超过30%即具备人类智能)
9月28日,浪潮人工智能研究院正式发布全球最大中文预训练语言模型“源1.0”。历时四个月研发,源1.0参数量已达2457亿,约GPT-3的1.4倍。
文章插图
中国工程院院士、浪潮首席科学家王恩东表示,源1.0巨量模型旨在打造更“博学”的AI能力,未来将聚合AI最强算力平台、最优质的算法开发能力,支撑和加速行业智能转型升级,以更具备通用性的智能大模型成就行业AI大脑。
“源1.0”定位中文语言模型,由5000GB中文数据集训练而成。在国内,以中文语言理解为核心的大模型不在少数,参数规模均在亿级以上,如悟道· 文源 26 亿,阿里PLUG 270 亿;华为&循环智能「盘古」1100亿。相比之下,2457亿的 源1.0 可以说是单体模型中绝对的王者。
更值得关注的是,源1.0是业界首个挑战“图灵测试”并且使平均误判率超过50%的巨量模型。图灵测试是判断机器是否具有智能的最经典的方法。通常认为,进行多次测试后,如果人工智能让平均每个参与者做出超过30%的误判,那么这台机器就通过了测试,并被认为具有人类智能。源1.0逼近通过图灵测试,再次证明了大模型实现认知智能的潜力。
为何加入这股“浪潮”?近几年,巨量模型在人工智能领域大行其道,BERT、GPT-3、Switch Transformer、悟道2.0相继问世,出道即巅峰,在产学各界掀起一阵阵巨浪。如今“巨量模型”一词已经成功破圈,成为全民热词。那么,人工智能遭遇了哪些瓶颈,巨量模型又带来了哪些可能性?
在会后采访中,浪潮信息副总裁、AI&HPC;产品线总经理刘军表示,人工智能模型目前存在诸多挑战,当前最首要的问题是模型的通用性不高,即某一个模型往往专用于特定领域,应用于其他领域时效果不好。

文章插图
也就是说,面对众多行业、诸多业务场景,人工智能需求正呈现出碎片化、多样化的特点,而现阶段的AI模型研发仍处于手工作坊式,从研发、调参、优化、迭代到应用,研发成本极高且难以满足市场定制化需求。而训练超大规模模型在一定程度上解决通用性问题,它可以被应用于翻译,问答,文本生成等等,涵盖自然语言理解的所有领域。
具体来说,从手工作坊式走向“工场模式”,大模型提供了一种可行方案:预训练+下游微调”,大规模预训练可以有效地从大量标记和未标记的数据中捕获知识,通过将知识存储到大量的参数中并对特定任务进行微调,极大地扩展了模型的泛化能力。同时大模型的自监督学习方法,使数据无需标注成为可能,在一定程度上解决了人工标注成本高、周期长、准确度不高的问题。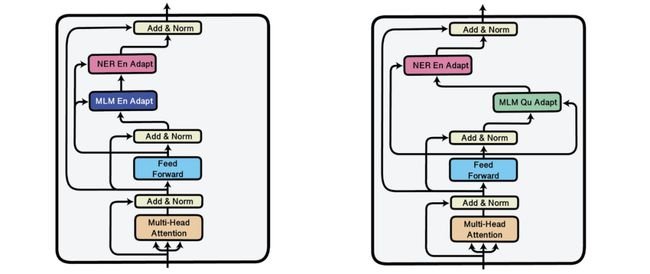
文章插图
刘军解释说,大模型最重要的优势是表明进入了大规模可复制的产业落地阶段,只需小样本的学习也能达到比以前更好的能力,且模型参数规模越大这种优势越明显,不需要开发使用者再进行大规模的训练,使用小样本就可以训练自己所需模型,能够大大降低开发使用成本。
现阶段,零样本学习和小样本学习是最能衡量巨量模型智能程度的两项测试。而源1.0在CLUE基准上刷新了多项任务的SOTA。
- 一个时代的结束!中国移动:10086 App将于1月30日起
- 智能制造|企业转型的新时代,夹缝中求生存
- 互联网时代|原极狐汽车总裁被挖至小米 担任小米汽车副总裁
- 在2021大中华区艾菲国际论坛上|玛雅文化施葵:新消费时代,如何助力品牌跑出“破圈”加速度?
- 互联网时代|华为走的是合作路线,跟传统厂家现在主打,物联网万物互联的模式
- 微商|朋友圈终于变干净了!网友:微商时代的终结
- 资费|中国关停国内的这些网络,500万人将失去通信,美国高通时代已过
- 对比度|大屏时代,MiniLED概念会成功领跑吗?
- 飞利浦·斯塔克|原价买显卡时代即将来临!英伟达:今年火力全开加大显卡产能
- Web3.0时代,数字人如何突破规模落地三大难点?百度李士岩:两