巨量|巨量模型时代,浪潮不做旁观者:2457亿,打造全球最大中文语言模型( 二 )
官方数据显示:源1.0在零样本榜单中,以超越第二名18.3%的绝对优势遥遥领先。
l在文献分类、TNEWS,商品分类、OCNLIF、成语完型填空、名词代词关系6项任务中获得冠军。
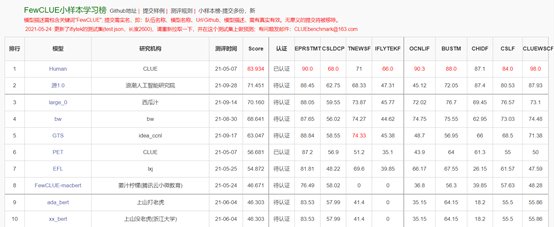
l在小样本榜单中,文献分类、商品分类、文献摘要识别真假、名词代词关系4项任务中获得冠军。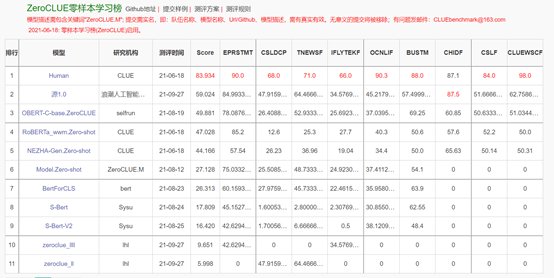
文章插图
https://www.cluebenchmarks.com/zeroclue.html
文章插图
https://www.cluebenchmarks.com/fewclue.html
"面对产业AI化挑战,巨量模型在多任务泛化及小样本学习上突出能力,以及其探索深度学习的极限和实现通用智能的可能性,浪潮前瞻性的做出了开发巨量模型的重要决策"。刘军表示,浪潮源1.0大模型只是一个开始,未来源1.0将面向学术研究单位和产业实践用户进行开源、开放、共享,降低巨量模型研究和应用的门槛,推进AI产业化和产业AI化的进步,
2457亿 是如何炼成的?大模型需要“大数据+大算力+强算法”三驾马车并驾齐驱,而对于大部分企业和机构来说,其中任意一项的研发投入都是沉重的负担,尤其是算力成本。比如1750亿参数的GPT-3单次训练需要 355 张 GPU,花费大约 2000 万美元。所以在炼大模型浪潮中,我们只看到了全球顶级的科技企业和科研机构的身影,而浪潮本潮也在其中。
浪潮 源1.0 在算力、算法和数据三个方面都做到了超大规模和巨量化。 
文章插图
首先是数据,浪潮创建了 5000GB 大规模的中文数据集,将近5年互联网上的内容浓缩成了2000亿词。2000亿词是什么概念?假如人一个月能读十本书,一年读一百本书,读 50 年,一生也就读 5000 本数,一本书假如 20 万字,加起来也就 10 亿字。也就是说,人类穷极一生也读不完2000亿词。
在大数据时代,比数据量更珍贵的数据质量。作为AI的底层燃料,模型对数据集质量提出了更高的要求。为此浪潮创新中文数据集生成方法,研制高质量文本分类模型,收集并清洗互联网数据过程中,有效过滤了垃圾文本,最终生成5000GB数据集可以说具备了够大、够真实、够丰富的特点。
文章插图
在算法层面,源1.0大模型使用了4095PD(PetaFlop/s-day)的计算量,获得高达2457亿的参数量,相对于GPT-3消耗3640PD计算量得到1750亿参数,计算效率大幅提升;在算力层面,源1.0通过算法与算力协同优化,使模型更利于GPU性能发挥,极大的提升了计算效率,实现业界第一训练性能的同时实现业界领先的精度。
谈起浪潮很多人还是停留在初级的印象,这是一家老牌硬件厂商,每年服务器市场占有率在全球范围内高居榜首。其实浪潮也一直活跃在AI前沿方向,自2018年成立浪潮人工智能研究院以来,其异构加速计算、深度学习框架、AI算法等领域已经战绩颇丰。例如,浪潮先后推出了深度学习并行计算框架Caffe-MPI、TensorFlow-Opt、全球首个FPGA高效AI计算开源框架TF2等;此外,在全球顶级的AI赛事上已累计获得56个MLPerf全球AI基准测试冠军。有了这些深厚的AI功底,浪潮在四个月内推出全球最大巨量模型不难理解了.
对于源1.0,业内专业人士评价称,其在巨量数据、超大规模分布式训练的扩展性、计算效率、巨量模型算法及精度提升等等难题上都有所创新和提升。
源1.0 更“博学”了吗?图灵测试一直被认为是人工智能学术界的”北极星“,也是检验机器是否具有人类智能的唯一标准。以GPT-3为代表的巨量模型出现后,机器开始在多项任务中逼近图灵测试,但直到源1.0之前,没有任何大模型突破30%的关卡。
- 一个时代的结束!中国移动:10086 App将于1月30日起
- 智能制造|企业转型的新时代,夹缝中求生存
- 互联网时代|原极狐汽车总裁被挖至小米 担任小米汽车副总裁
- 在2021大中华区艾菲国际论坛上|玛雅文化施葵:新消费时代,如何助力品牌跑出“破圈”加速度?
- 互联网时代|华为走的是合作路线,跟传统厂家现在主打,物联网万物互联的模式
- 微商|朋友圈终于变干净了!网友:微商时代的终结
- 资费|中国关停国内的这些网络,500万人将失去通信,美国高通时代已过
- 对比度|大屏时代,MiniLED概念会成功领跑吗?
- 飞利浦·斯塔克|原价买显卡时代即将来临!英伟达:今年火力全开加大显卡产能
- Web3.0时代,数字人如何突破规模落地三大难点?百度李士岩:两