wenet|GPT-3 出圈一年后,中国公司跟进了吗?( 二 )
做出中文版 GPT-3,终究还是要落在服务公司业务上。「出门问问主要的核心竞争力在于全栈式的语音交互解决方案,所以我们现在也在研发将模型从纯文本单模态,延伸至同时能处理文本 / 声音 / 图像的单一多模态模型。
林士翔解释,出门问问主要在经营的有「听说读写」四个模块,「听」指的是语音识别,对应 AI + 可穿戴业务;「说」指的是语音合成,对应 AI + 办公效率;「读」指自然语言处理 / 计算机视觉,对应 AI + 车载;「写」指文本生成 / 图像生成。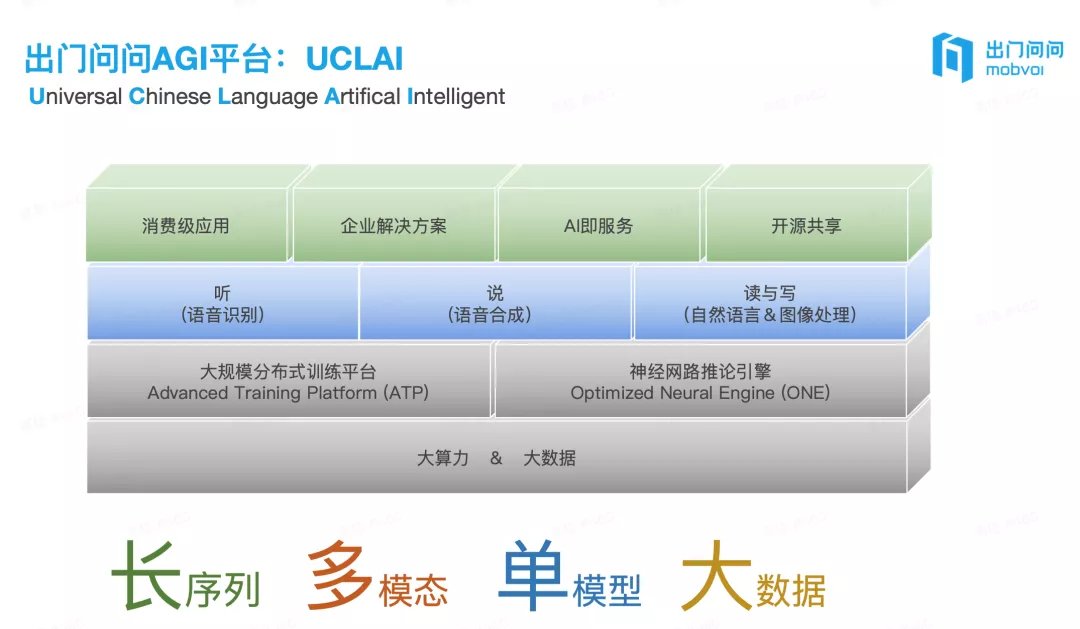
文章插图
现在团队在实践的就是将「听说读写」四个模块都放到 UCLAI 这个多模态单一通用模型上跑。但因为声音、图像、文本对于机器来说,都是不一样的信号,要做到各种模态能被理解、转换、表示仍是不小的挑战。
「现在用一个通用模型去处理,能达到的效率只是原来多个专用模型加起来的效率的六到七成。」林士翔说,「对于我们这种创业公司来说,假设我们之前要给每个模型配 3 个人,4 个模型就是 12 个人,那为什么我们不让这 12 个人集中精力就做一个通用的模型?这样的话,我们的研发成果可以相互积累,而且可以相互共用。另外,如何让这大模型可以更轻量化或更可控的工业化落地也是我们未来一个重要的研发方向。」
追求实用之外,他们还做了一些好玩的项目怎么把自然语言模型的魅力展示给普通大众,林士翔说做文本分类和情感分析「大众比较无感」,但用 AI 赋能古文却是每个人中国人都能共情的。
现有互联网上带有白话文翻读的古诗词大约在几千到几万篇,数十万篇诗词只有本文没任何白话翻译,更遑论其他中国经典古文,不是四散在互联网上不同平台网站里,就是以纸本方式存在,不能像互联网一样能让知识快速传播。
随着计算机科技的进步,互联网上开始出现利用计算机进行古文翻译的服务,但大多数的方法不外乎:根据汉语词典或规则查表进行逐词翻译;或是利用数据库进行片段信息检索的方式翻译,这些方法往往忽略了文章里上下文的信息,因此翻译出来的结果跟原文的意思南辕北辙,或是翻译完的文章跟原文一模一样,没做任何改变。
于是,出门问问在 UCLAI 模型的基础上数百 G 互联网上的中文语料收集及清洗,以及利用数百张英伟达 V-100GPU 显卡,完成了百亿级参数量的模型训练。
得益于模型对语言知识的建模能力,古文宝不仅能将文言文翻译成白话文,甚至是其他外语,对白话文翻译成文言文的能力也是不在话下。出门问问还针对 GPT-3 底层的 Transfomer 架构进一步改造优化,让模型除了可以处理文本信息外,也具备生成图像与声音的能力,古文宝除了自动翻译出对应的古文外,还会跟据内容自动生成一张古画。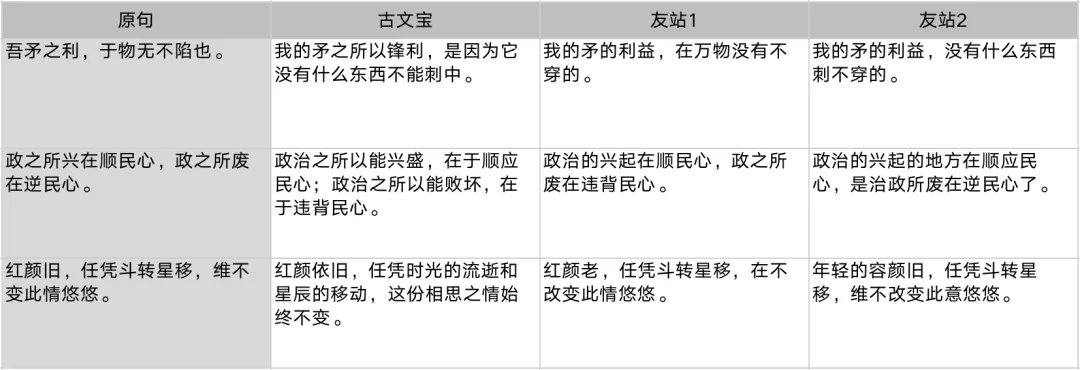
文章插图
古文宝翻译效果展示|出门问问
「古文宝的发布只是一个开始,我们也乐见更多对中文有研究的机构或学者能和我们一起合作,大家协力让语言智能黑科技做得更好,能将中国传统文化以更多元的方式普惠大众。」李志飞说。
但目前,古文宝目前也还有一些问题待解决?比如,诗句与生成古画之间的内在关联度、古画的解析度、文言文转白话文的翻译质量等还需继续提升。
团队还透露,除了古文宝之外,团队还在做一个用 AI 合成音乐的项目,「你给我一个音乐的前奏,给我一段歌词,系统可以自动生成出一首歌来,而且是可以唱出来的。它会是一首全新的歌。」让 AI 为中国传统文化的传承赋能,同时也让中国人更多才多艺,是 UCLAI 的实用愿景。
- 虚拟人频频出圈,下一个“同事”还会是人么?
- 崔筱盼|数字虚拟人频频出圈 能在多大程度上替代真人?
- 人工智能|数字虚拟人频频出圈 能在多大程度上替代真人?
- 人工智能|数字虚拟人频频出圈,能在多大程度上替代真人?
- 数字虚拟人频频出圈能在多大程度上替代人?
- 京东|霸屏综艺,牵手明星,扩列神器皮皮APP的出圈始末
- 潮玩IP联名火出圈,中消协点名全家桶盲盒
- 魅族18|魅族18s Pro出圈,什么手机才配得上年度高端旗舰称号?
- 脉脉|非刚需、不出圈,脉脉成不了下一个领英
- 时尚先生们的潮流Vlog神器,荣耀60又出圈了