
文章图片
文章图片
文章图片
文章图片
哈喽 , 大家好 , 今天我们继续来总结pandas面试题 。
1.隐藏索引
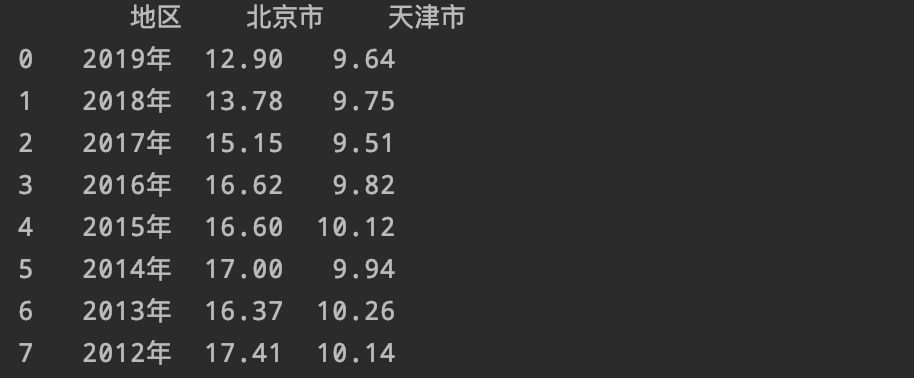
首先我们先导入数据:
import pandas as pd
df=pd.read_excel('北京结婚人数.xlsx')
然后设置好索引:
df.reset_index(drop=True)
然后hide_index进行隐藏索引:
df.style.hide_index()
2.高亮最大值
df.style.highlight_max(axis=0subset=['北京市'
)
3.高亮最小值
df.style.highlight_min(axis=0subset=['北京市'
)
4.高亮空值
df.style.highlight_null(axis=0subset=['北京市'
)
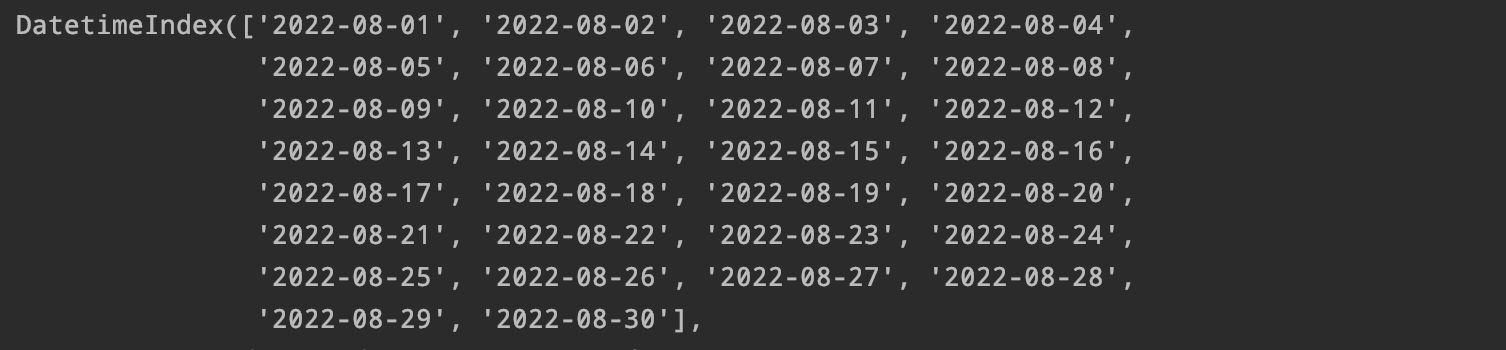
5.设置时间序列:
通过date-range设置好开始和结束的时间
pd.date_range(start='2022-8-01'end='2022-8-30')
同样可以通过频率设置 , 来呈现相同的效果:
df=pd.date_range(start='2022-8-01'periods=30)
6.设置时间戳
通过timestamp函数可以将精确的时间点展示出来:
pd.Timestamp('2022-08-15')
7.截断函数:
我们仍旧以上面的数据为例:
先导入数据:
import pandas as pd
df=pd.read_excel('北京结婚人数.xlsx')
我们通过截断函数 , 只要前5行数据:
df=df.truncate(before=0after=5)
8.merge函数怎么用?
我们先准备两组数据:
left = pd.DataFrame({'key1': ['K0' 'K0' 'K1' 'K2'
'key2': ['K0' 'K1' 'K0' 'K1'
'A': ['A0' 'A1' 'A2' 'A3'
'B': ['B0' 'B1' 'B2' 'B3'
)
right = pd.DataFrame({'key1': ['K0' 'K1' 'K1' 'K2'
'key2': ['K0' 'K0' 'K0' 'K0'
'C': ['C0' 'C1' 'C2' 'C3'
'D': ['D0' 'D1' 'D2' 'D3'
)
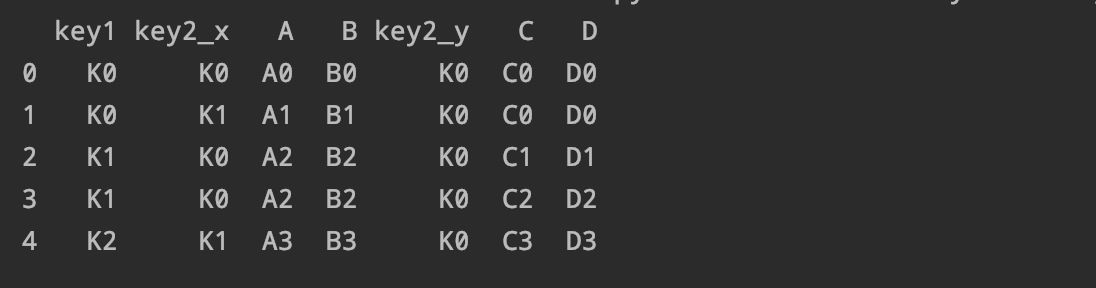
【北京市|【全面】pandas数据分析面试题(六)汇总!】我们通过key1进行合并这两组数据:
pd.merge(left right on='key1')
还可以通过多字段连接:
通过inner合并的数据 , 只会留下相同的字段:
pd.merge(left right on=['key1' 'key2'
how='inner')
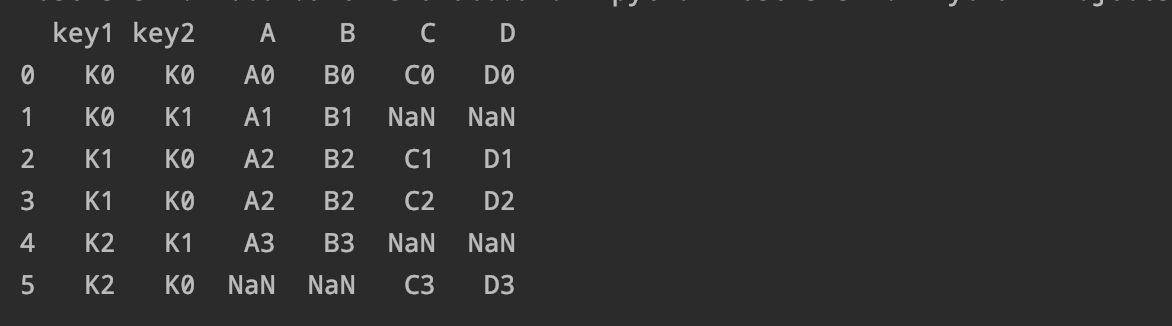
通过outer合并数据 , 不相同的数据也会保留:
pd.merge(left right on=['key1' 'key2'
how='outer')
- 小米科技|清仓大促销!小米30英寸准2K、200Hz高刷电竞屏跌至1099元
- 本文转自:多彩贵州网...|【“老物件”会说话】失而复得的相册
- 工业|全国工业和信息化技术技能大赛决赛举行
- 本文转自:北京日报世界机器人大会上|既能举重又能灵活抓取小物件 机器人“脑眼臂手”全面升级
- 鏖战3纳米!三星之后台积电宣布下半年量产,移动芯片先用
- Java|java视频教程之Java开发框架
- 本文转自:北京日报8月20日凌晨|破纪录!中国长征系列运载火箭连续103次发射成功
- 全面屏|新的手机全面屏方案曝光!超微孔前摄封装上边框,魅族:这个我熟
- 产能全面升级|峻宸与你相约2022TCT亚洲增材制造展会
- 笔记本电脑|6K价位最适合女生的笔记本电脑有哪些?全面分析之后,我推荐这台