token|中国力量在人工智能顶会崛起,这枚NLP“金牌”奥妙何在?( 三 )
MUV可以理解成为信息熵对词表大小的负一阶导数,也即是我们在逐个增加token来构建词表的时候,每增加一定量的token导致的信息熵增益。我们的目标,就是要在巨大的词表空间中寻找MUV的最高值。
这样就可以把词表学习转化为搜索具有最大MUV分数的词表问题。为了解决该问题,作者提出了一种基于最优运输的方案。
为了便于大家更方便地理解最优运输,这里对最优运输先做一个简单的回顾。
大约250年前,法国数学家蒙日在其作品中对这类问题进行了严格分析,下面是一个比较直观的例子。
假设在战争中,我方有一些前线(蓝色星星)发出了需要增兵的信号,而我们的士兵分散在不同的后方根据地(红色旗帜)。不同的前线需要的士兵个数不同,后方根据地的士兵个数也不同,前线距离后方根据地的距离也不同。问如何设计转移方案,使得总转移代价最低?这就是最优运输想要回答的问题。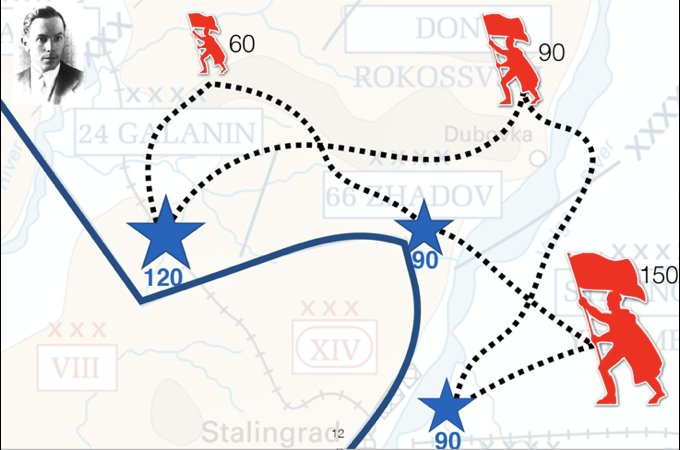
文章插图
那么,如果要用最优传输来解决词表学习问题,首先要将问题进行重建。作者们将句子拆分成字符后的表示看成是后方士兵,将候选词表看成是前线。为了避免不合法的搬运,作者们将不合法的搬运设为无穷大(比如字e搬运给词cat是不合法的)。每种搬运方式对应一种词表,那么我们只需要把搬运代价定义成MUV相关分数,就可以实现搜索的目的。
那么如何将词表学习的问题转化成为最优运输的代价呢?作者对问题进行了简化。简化过程分为两步,一个是对搜索空间进行压缩,一个是对目标进行近似。对技术细节感兴趣的读者,可以看看VOLT方法的伪代码:
文章插图
以下是VOLT生成的词表在双语翻译的结果,可以看出新方法学到的词表比经常使用的词表大小小很多,效果也很有竞争力。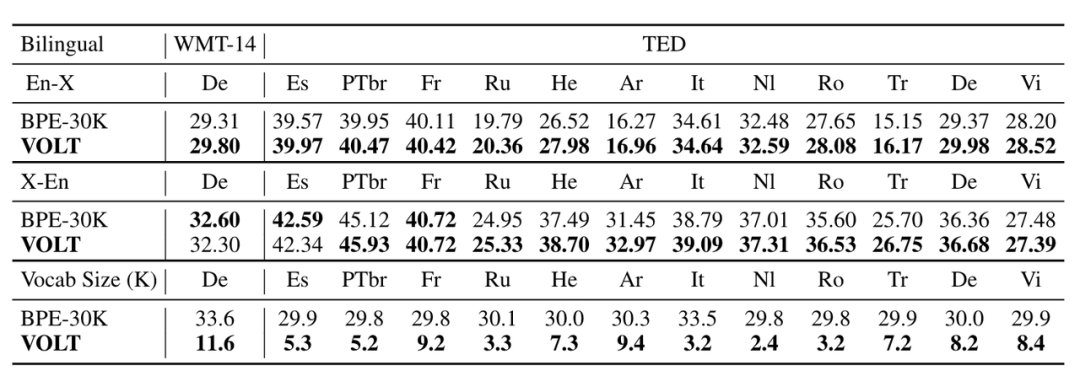
文章插图
以下是在多语翻译的结果,总体来看,在三分之二的数据集上效果也是较好的。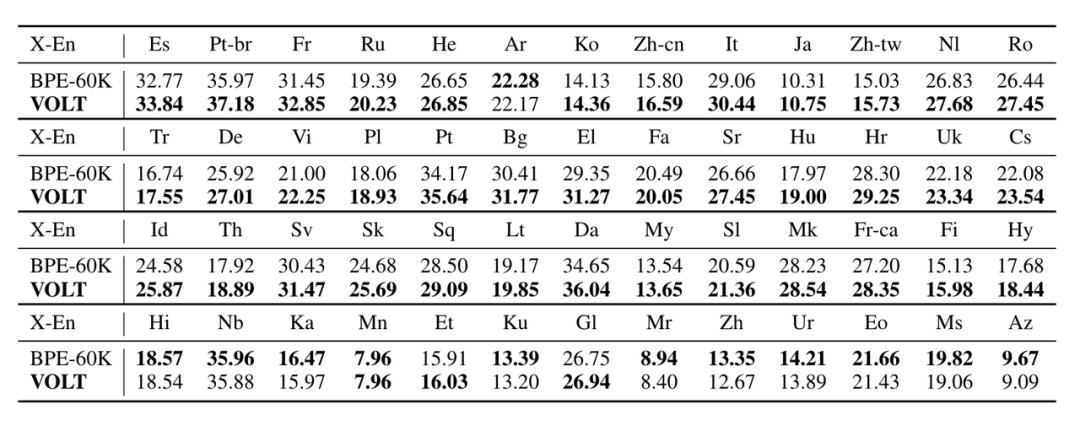
文章插图
VOLT不需要结合任务的下游任务训练,因此非常简单高效。但许晶晶转而说道,“这其实是一把双刃剑,如果可以结合下游任务的话,有机会针对特定情况或许可以获得更好的性能和效率。”
相比于对模型的关注,词表在NLP社区中相关的研究可能少一些,而词表又是非常重要的一环。如何去理解词表其实是一个很有意思的问题。
对于这项工作的泛化性,许晶晶也有所期待,“或许未来能在其他NLP任务上看到VOLT的身影。”
同时,这项技术也被团队用到了竞赛中。在今年的WMT2021中,字节跳动AI Lab在WMT机器翻译比赛中取得了好成绩。这次比赛中,除了VOLT,团队们还使用了非自回归的方法GLAT。
文章插图
论文链接:https://arxiv.org/abs/2008.07905
在WMT2021国际机器翻译大赛上,字节跳动火山翻译团队以“并行翻译”系统参赛,获得德语到英语方向机器翻译比赛自动评估第一名。“并行翻译”在国际大赛首次亮相,就成功击败了从左向右逐词翻译的“自回归模型”技术,打破后者在机器翻译领域的绝对统治地位。
许晶晶的团队同事周浩说道,“这充分说明并行(非自回归)生成模型未必比自回归模型差”。
WMT2021是由国际计算语言学协会ACL举办的世界顶级机器翻译比赛,德英语向是该赛事竞争最激烈的大语种项目之一。
- 产业|打造世界级产业地标 中国声谷冲刺5000亿产值
- 三星|试图挽回中国市场,国际大厂不断调价,从高端机皇跌到传统旗舰价
- 蓝思科技|苹果与34家中国供应商断绝合作,央视呼吁:尽快摆脱对苹果依赖
- 他是“中国氢弹之父”,他的名字曾绝密28年,他叫于敏
- 短信|关于5G消息,中国移动取得新进展,微信该做准备了
- 一个时代的结束!中国移动:10086 App将于1月30日起
- 信息科学技术学院|瞧不起中国芯?芯片女神出手,30岁斩获国际大奖,让美国哑口无言
- 智能手机|全球第17位!App Annie报告:2021年中国人均每天用手机3.3小时
- 本周华为小米相继报出的新闻,让我看到中国科技公司未来发展希望
- 中国电信|在Dolby Week,我见识了真正的杜比体验