token|中国力量在人工智能顶会崛起,这枚NLP“金牌”奥妙何在?( 二 )
团队成员们非常尊重和支持她的个人研究兴趣,当她最开始提出想要研究词表的时候,很快就获得了团队成员们的支持。
词表,也就是把句子拆分表示的参考表,有多种形式,比如词级别、字符级别、子词级别等等,如下图所示。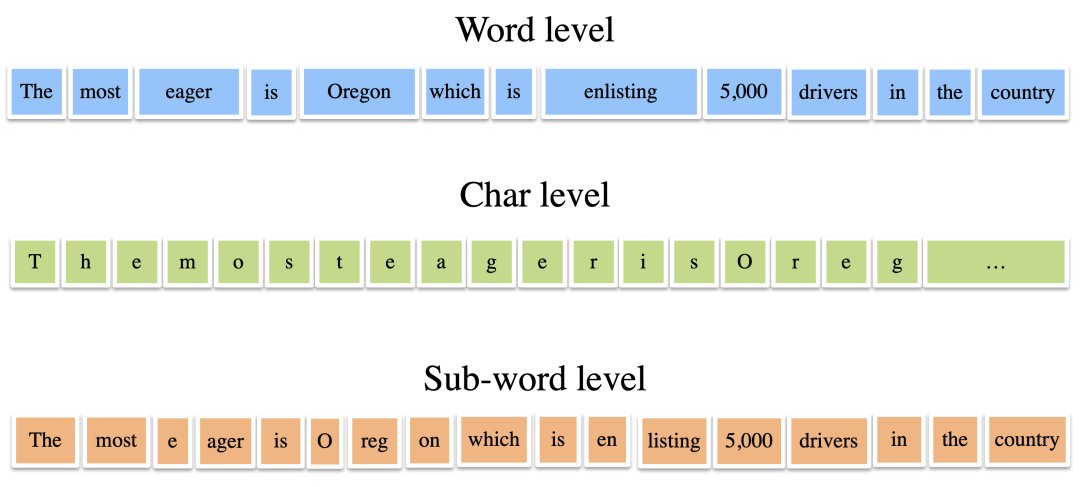
文章插图
在机器翻译架构中,这些句子在输入后会依据词表拆分成token(比如”Oregon“被拆分成“O”、“re”、“gon”三个token),然后将每个token分别表示为向量,再进行神经网络的编码、解码,然后先输出token级别的表示,再依据词表组合成完整的翻译句子输出。
在三种级别的词表中,词级别简单按照词汇水平对句子进行分割,对应的词表就是语料中所有的单词;字符级别把所有单词都拆分成字母。子词级别介于两者之间,比如在上图这句话中,”Oregon“被拆分成“O”、“re”、“gon”三个token,“enlisting”被拆分成“en”、“listing”。
目前为止,子词级别的词表使用比较多,并且已经在多个任务上验证了效果。因此,在目前的认知条件下,可以暂时认定子词为较好的选择。
在这项研究中,实验室团队就是希望找到最好的子词词表,以提高机器翻译的性能和效率。
如何理解子词表示的好处呢?比如在“enlisting”和“enlighten”这两个单词中,我们可以把它们拆分成“en”、“listing”,以及“en“、”lighten”,然后我们在向量空间中需要构建“en”、“listing”、“lighten”这三个词向量。在足够多的词汇量下,子词级别需要的词表比词级别的要小。
从一般的意义上讲,子词表示是一种信息压缩(相对于字符表示)。就好像为了理解大量的蛋白质数据,我们用氨基酸作为基本单元来进行分类,而不是直接用原子作为基本单元。但也因此,子词级别的词表相比字符级别会更大。
文章插图
那么词表是不是越大越好呢?实际上在BPE算法中随着词表增大,新增的子词匹配的多是稀疏单词,也就是信息熵降低,这样反倒不利于模型学习。
具体而言,对于每一种语言来说,常用的单词都是少数的。或者准确点说,每一种语言的单词使用频率是呈现长尾分布的。
文章插图
这意味着,整个机器翻译系统中,对这些低频词汇进行子词分解,在后续的编解码中,并不会对信息熵的变化带来太大收益。
因此除了信息熵,词表大小也是衡量词表的重要因素。
团队由此联想到了经济学中的经典现象——边际收益。
通俗来说,边际收益就是指“刚开始的几口蛋糕真香”以及“最后一口蛋糕好腻”。我们可以把“吃一口蛋糕”定义为投入,“真香感受”定义为产出,边际收益就是投入产出比。“刚开始的几口蛋糕真香”的投入产出比高,“最后一口蛋糕好腻”的投入产出比低。
文章插图
在子词词表构建中,随着词表大小的增加,一般来说,token的信息熵收益会在某个时刻之后达到巅峰并且下降。
而这个性价比临界点,正是团队要寻找的目标。
因此,团队为了建模这种平衡,引入了边际收益的概念。团队将信息熵看成是边际收益中的利益,词表大小看成是边际收益中的代价。随着词表的增加,不同大小的词表的信息熵收益是不同的。
团队使用边际收益的概念定义了衡量词表质量的指标MUV,并且观测到了MUV指标和下游任务的相关性。
- 产业|打造世界级产业地标 中国声谷冲刺5000亿产值
- 三星|试图挽回中国市场,国际大厂不断调价,从高端机皇跌到传统旗舰价
- 蓝思科技|苹果与34家中国供应商断绝合作,央视呼吁:尽快摆脱对苹果依赖
- 他是“中国氢弹之父”,他的名字曾绝密28年,他叫于敏
- 短信|关于5G消息,中国移动取得新进展,微信该做准备了
- 一个时代的结束!中国移动:10086 App将于1月30日起
- 信息科学技术学院|瞧不起中国芯?芯片女神出手,30岁斩获国际大奖,让美国哑口无言
- 智能手机|全球第17位!App Annie报告:2021年中国人均每天用手机3.3小时
- 本周华为小米相继报出的新闻,让我看到中国科技公司未来发展希望
- 中国电信|在Dolby Week,我见识了真正的杜比体验