研究者|计算机行业越来越卷,AI都会刷LeetCode了,网友:比我强( 二 )
为了创建 APPS 数据集,研究者手动处理了来自开放网站的问题,在这些网站中程序员可以相互分享问题,包括 Codewars、AtCoder、Kattis 和 Codeforces。为了提高数据集的质量和一致性,研究者对每个问题源使用自定义 HTML 解析器。必要时,研究者使用 MathPix API 将图像转换为 LaTeX。此外研究者还使用具有 SVD 降维和余弦相似度的 tf-idf 特征执行重复数据删除。
在数据分级上,数据集被分为三个难度。例如,Kattis 难度小于 3 的问题被归类为「入门级难度」,难度在 3 到 5 之间的问题被归类为「面试级难度」,难度大于 5 的问题被归类为「竞赛级难度」。
入门级难度:大多数有 1-2 年经验的程序员不需要复杂的算法就可以解决这些问题,有 3639 个;
面试级难度:问题会涉及数据结构,比如树或者图,或需要修改常见的算法,有 5000 个;
竞赛级难度:达到高中和大学编程比赛的水平,包括 USACO、IOI 和 ACM,有 1361 个。
实验
研究者使用 APPS 基准分析了各种 Transformer 模型。结果发现,微调和增加模型尺寸可以提高准确率,而准确率随着难度的增加而下降。此外,实验发现语法错误正在减少,生成的代码在质量是合理的。模型采用 GPT-2、GPT-3、GPT-Neo。GPT 体系架构特别适合于文本生成,因为它是自回归的。
评估指标
为了全面评估模型的代码生成能力,研究者使用了 APPS 提供的大量测试用例和实用的解决方案。测试用例允许自动评估,即使可能程序的空间组合起来可能很大。因此,与许多其他文本生成任务不同,不需要手动分析。将生成的代码在测试用例上的性能汇总为两个指标,即「测试用例平均值」和「严格准确性」。
模型性能分析
定性输出分析。模型有时可以生成正确的或表面上合理的代码。图 2 显示了通过所有测试用例的 GPT-2 1.5B 生成的代码。当模型没有通过测试用例时,有时乍一看它们生成的代码似乎仍然是合理的。例如,在图 3 给出了 1.5B 参数模型生成与问题陈述相关的代码,并进行了合理的尝试来解决它。
测试用例评估。表 2 显示了主要结果。研究者观察到,模型能够生成通过一些测试用例的代码,这意味着许多生成的程序都没有语法错误,并且可以成功处理输入测试用例以产生正确答案。请注意,对于入门性问题,GPT-Neo 通过了大约 15%的测试用例。研究者将图 4 中的「测试用例平均」结果可视化。这演示了模型在代码生成方面显示出明显的改进,并且现在开始对代码生成产生吸引力。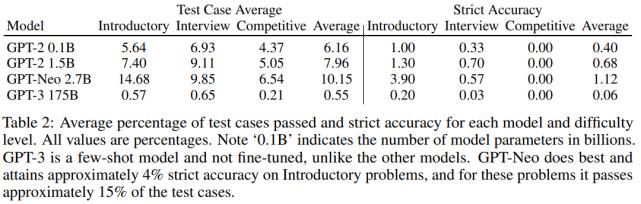
文章插图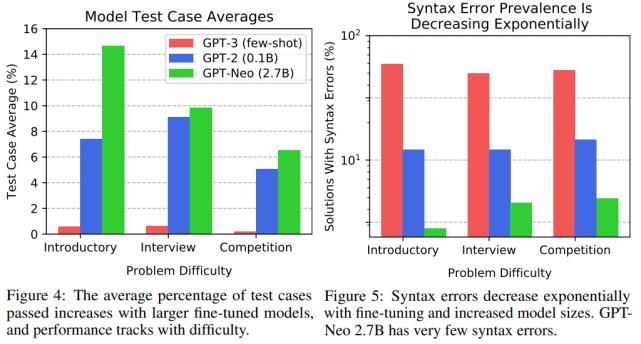
文章插图
语法错误。研究者评估了语法错误的频率,这些语法错误导致程序无法解释,包括间距不一致,括号不平衡,冒号丢失等。如图 5 所示,语法错误存在普遍性。虽然 GPT-3 针对入门问题生成的解决方案中大约有 59%存在语法错误,但 GPT-Neo 语法错误发生率约为 3%。请注意,Yasunaga 和 Liang(2020)等最近的工作创建了一个单独的模型来修复源代码以解决编译问题,但是该研究的结果表明,由于语法错误频率会自动降低,因此将来可能不需要这样做。
BLEU。为了评估 BLEU,研究者采用生成的解并针对给定问题用每个人工编写的解计算其 BLEU,然后记录最高的 BLEU 得分。在图 6 中观察到,即使模型在处理更棘手的问题上实际上表现较差,随着问题来源变得越来越困难,BLEU 也会增加。此外,较差的模型可能具有相似或更高的 BLEU 得分。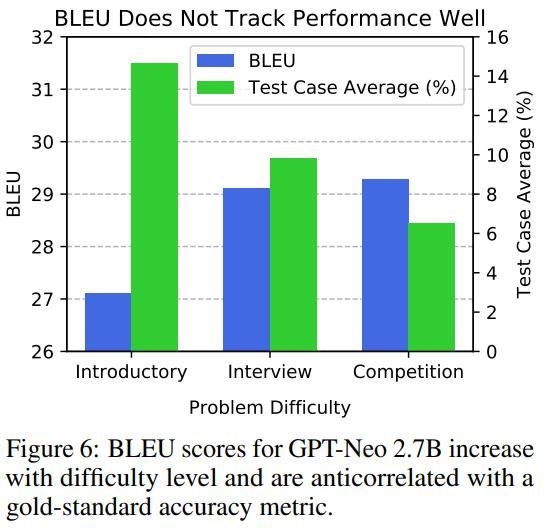
- 加盟行业|原来加盟行业是这么玩的!
- 图灵奖|中国科技团队创历史,360打破行业垄断,登顶世界最强人工智能榜
- 加速行业变革!比亚迪联手美国公司发布无人驾驶配送车
- 化州市富美家电维修店整合行业招商运营资源的专业平台
- javascript|奢侈品级别音响B&W加持,峰米向行业第一发起冲击?
- ROE雷迪奥到访芯映光电,共谈行业趋势,谱写合作新篇章
- 昌江区珠山区区县服务商整合行业招商运营资源的专业平台
- 买斗整合行业招商运营资源的专业平台
- 腾讯&复旦大学元宇宙报告,七大分类构造元宇宙生态,“元宇宙率”定义行业标准 | 智东西内参
- 产业链|航空装备制造行业产业链全景梳理及区域热力地图