研究者|计算机行业越来越卷,AI都会刷LeetCode了,网友:比我强
机器之心报道
机器之心编辑部
终究还是「卷」到了自家。
来看一道经典的编程题目:
已知一个论文引用量序列,其中每个引用量都是非负整数,请编写一个输出为 h_index 的同名函数 h_index()。其中 h_index 指至多有 h 篇论文分别被引用了至少 h 次。
一种解答代码如下:
文章插图
这段代码虽然在细节上存在一些问题,却能够顺利通过部分样例测试。而它居然是 AI 写的!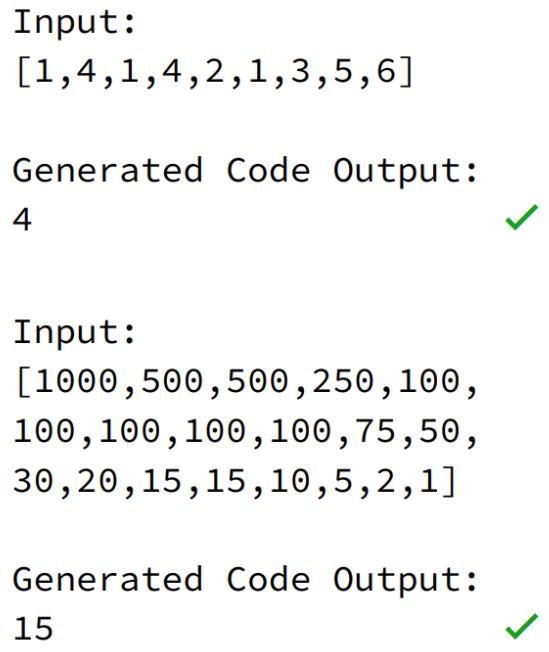
文章插图
上述代码顺利通过了部分样例测试。
随着深度学习的兴起,AI 让许多行业实现了自动化,包括将 AI 用于编程。人们在编程时通常会使用大量的有意识和潜意识思维机制发现新问题并探索不同的解决方案,然而大多数机器学习算法都需要定义明确的问题和大量带有注释的数据才能够开发出解决相同编程问题的模型,因此用 AI 编程并非易事。此外,准确地评估模型的代码生成性能可能是很困难的,并且很少有既灵活又严格的方式来评估代码生成的研究。
基于此,来自 UC 伯克利等机构的研究者提出了 APPS(Automated Programming Progress Standard),一个代码生成基准,该基准测试能够衡量模型的代码生成能力,并检查代码是否符合问题要求。与公司评估候选软件开发人员的方式类似,该研究通过检查生成的代码在测试用例上的结果来评估模型。基准测试包括 10000 个问题,包含单行代码解决的简单问题和具有大量代码的复杂算法挑战等多多种问题。上述 AI 生成代码示例在 APPS 数据集中被视为「面试级别」的问题。
对此,有网友说道:「如果我不能通过编码面试,但我写的算法通过了,那么会怎样?」
文章插图
那大概会录用「算法」?
我们再来看一个例子:
问题:已知两个整数 n 和 m。计算数组(a,b)对数,使两个数组的长度都等于 m;每个数组的元素都是 1 到 n 之间的整数;对于任意索引 i 从 1 到 m,都有 a_i≤ b_i;数组 a 按非降序排列;数组 b 按非升序排序。结果可能很大,应该打印它的 modulo10^9+7。输入:唯一的行包含两个整数 n 和 m(1≤ n≤ 1000,1≤ m≤ 10)。输出:打印一个整数,满足上述 modulo10^9+7 所述条件的数组 a 和 b 的数量。
根据问题描述,AI 自动生成代码,尽管生成的代码通过了 0 个测试用例,但第一眼看起来似乎是可行的:
文章插图
研究者在 GitHub 和训练集上对大型语言模型进行了微调,并发现微调后语法错误率呈指数级下降。在 GPT-Neo 等模型上可以通过大约 15% 的入门问题测试用例。
文章插图
论文地址:https://arxiv.org/pdf/2105.09938.pdf
GitHub 地址:https://github.com/hendrycks/apps
APPS 数据集
APPS 数据集包括从 Codeforces、Kattis 等不同的开放编码网站收集的问题。APPS 基准试图通过以不受限制的自然语言提出编码问题并评估解决方案的正确性来反映人类程序员的评估方式。问题的难度范围从入门到大学竞赛水平,用来衡量编码能力和解决问题的能力。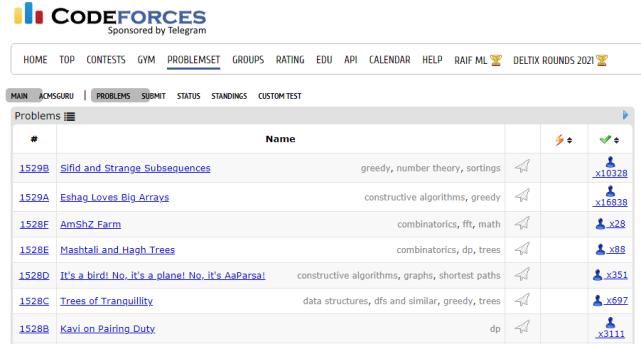
文章插图
APPS 总共包含 10000 个编码问题,其中包括 131836 个用于检查解决方案的测试用例和 232444 个由人类编写的真实解决方案。里面的问题可能是很复杂,因为平均长度为 293.2 个词。数据集被平均分为训练集和测试集,每部分都有 5000 个问题。在测试集中,每个问题都有多个测试用例,平均测试用例数为 21.2。每个测试用例都是针对相应问题而专门设计的,能够严格评估程序功能。
- 加盟行业|原来加盟行业是这么玩的!
- 图灵奖|中国科技团队创历史,360打破行业垄断,登顶世界最强人工智能榜
- 加速行业变革!比亚迪联手美国公司发布无人驾驶配送车
- 化州市富美家电维修店整合行业招商运营资源的专业平台
- javascript|奢侈品级别音响B&W加持,峰米向行业第一发起冲击?
- ROE雷迪奥到访芯映光电,共谈行业趋势,谱写合作新篇章
- 昌江区珠山区区县服务商整合行业招商运营资源的专业平台
- 买斗整合行业招商运营资源的专业平台
- 腾讯&复旦大学元宇宙报告,七大分类构造元宇宙生态,“元宇宙率”定义行业标准 | 智东西内参
- 产业链|航空装备制造行业产业链全景梳理及区域热力地图