用户|KANO模型的量化处理( 二 )
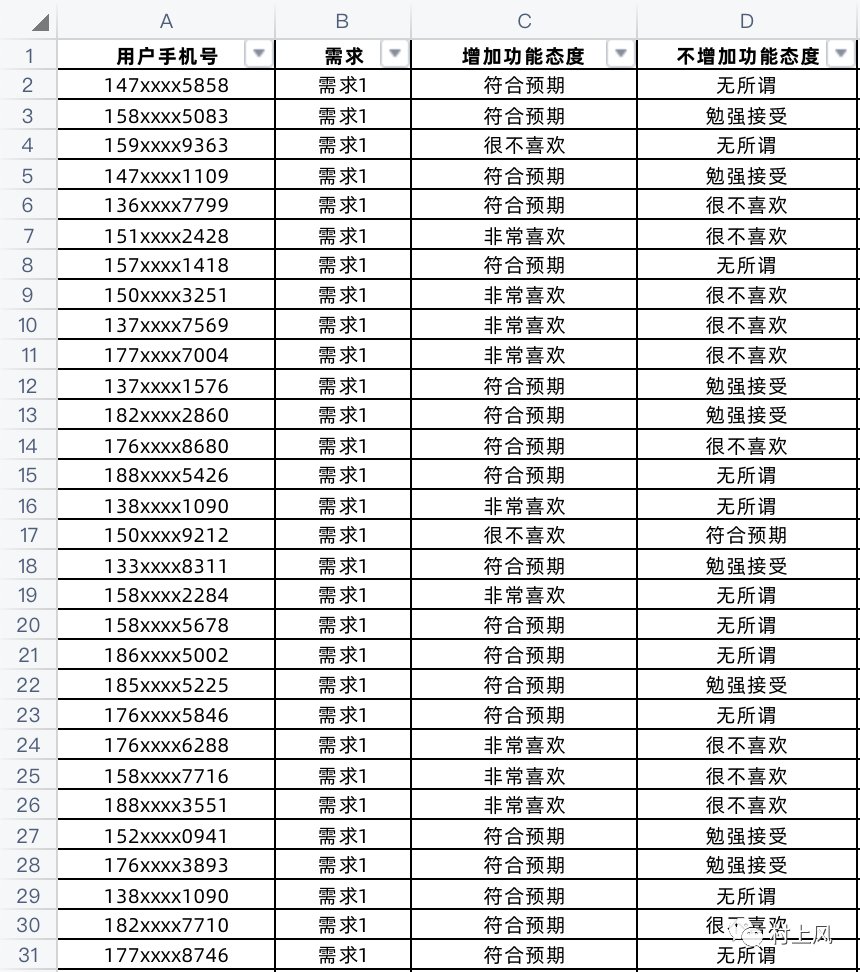
文章插图
四、对问卷进行需求分类再结合上面的不同需求类型的矩阵图,就可以针对每一条需求都划分出每个用户所认为的需求的类型是什么了,最终我们就定义出了需求的类型如下图所示: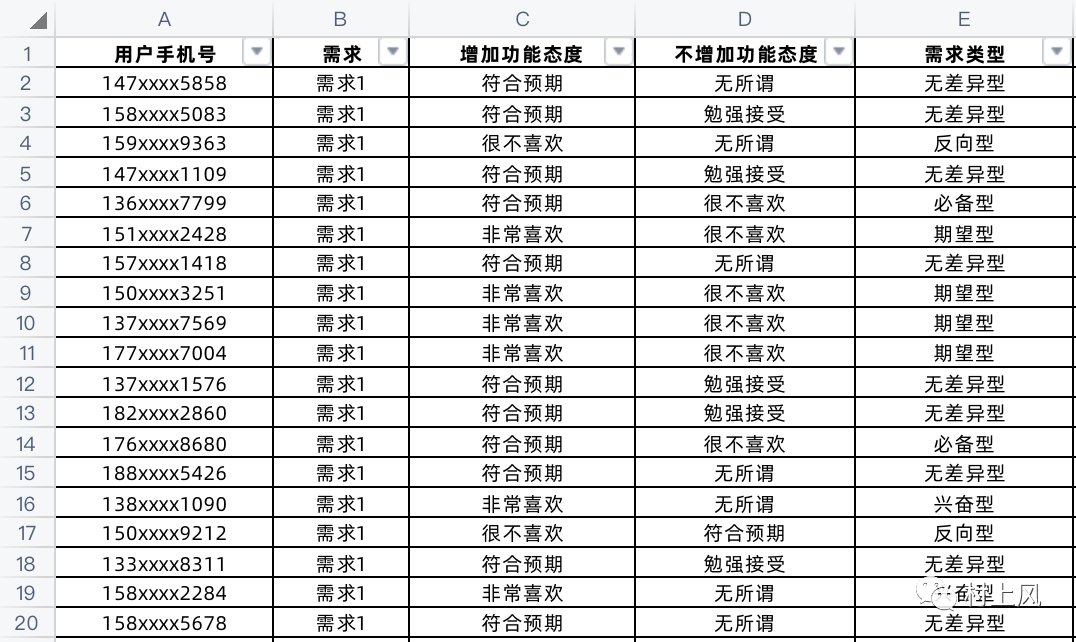
文章插图
到这里之后,其实问题就出现了。对于同样一条需求,不同用户所定义的需求类型是不一样的,那么,我们总得按照某种方式计算出一个最后的标准吧?最典型的思维方式就是少数服从多数,于是就可以考虑采用统计同一需求不用用户不同类型的定义,然后计算趋向于对用户带来好的方向影响的占比,再计算给用户带来不好的方向影响的占比,最后按照平均值划分进行定义。
在KANO模型里也是采用了上面的思考方式,只不过定义出了一个叫做better-worse系数的东西。
【 用户|KANO模型的量化处理】better系数 = (A+O)/(A+O+M+I)
worse系数绝对值 = |-(M+O)/(A+O+M+I)|
按照收集上来的问卷(包含了900份调查问卷的结果),统计和计算后的数据如下图所示: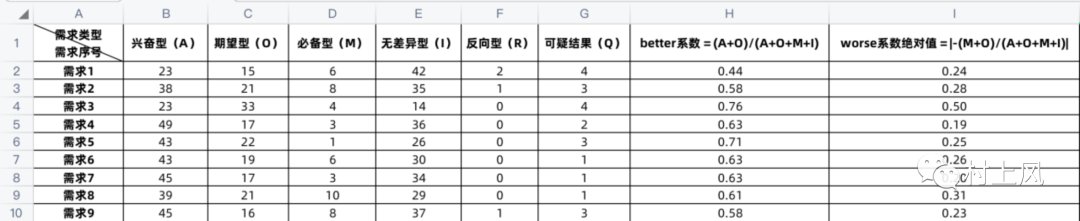
文章插图
将统计后的每个需求对应的坐标点放置在better-worse坐标系当中,并且在坐标系当中基于所有的坐标点,生成better的平均值对应的参考线以及worse的平均值对应的参考线,划分出最终的兴奋型、必备型、期望型、无差异型需求,按照优先级必备型>期望型>兴奋型>无差异型划分出优先级即可。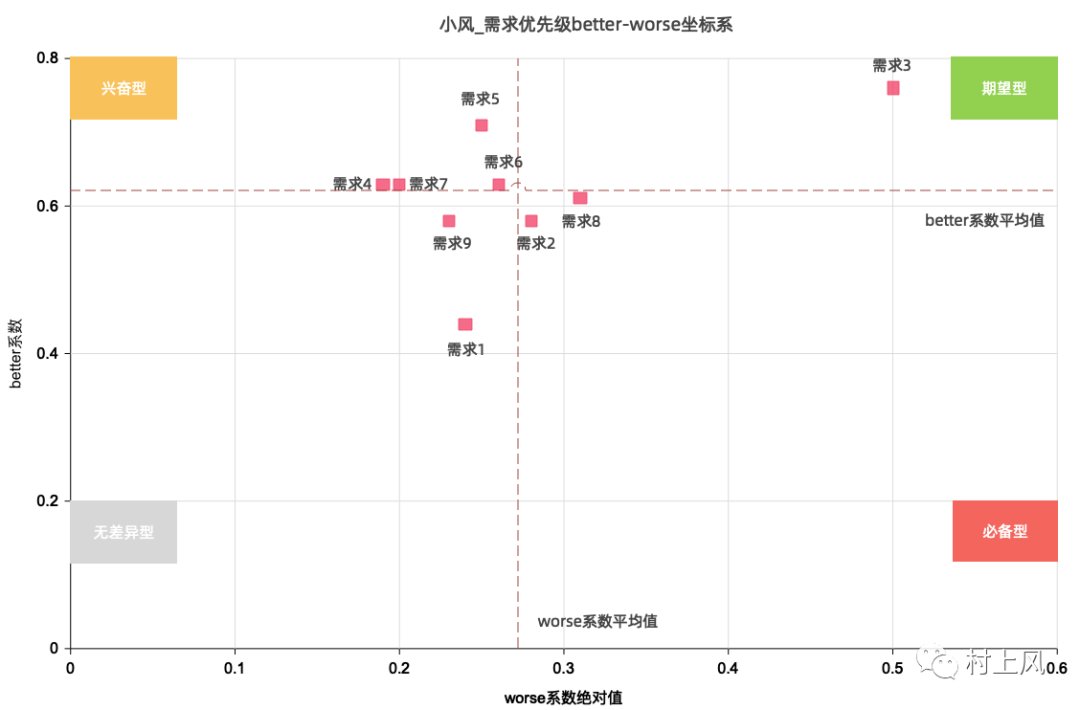
文章插图
至此,一个KANO模型在实际工作中的量化处理案例就讲完了。
作者:小风,产品经理;公众号:村上风
本文由 @小风 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自Unsplash,基于CC0协议。
- 小米科技|预算只有两三千买这三款,颜值性能卓越,没有超高预算的用户看看
- 我们的生活|社交正在推动“孤独生意”多元化发展,天聊将重塑用户精神世界!
- 微信|数亿用户没白等,微信迎来更新,张小龙终于干正事了
- |OPPOK11x,精准的满足用户对于强续航,大存储、拍摄的需求
- iOS|苹果推送iOS15.2.1正式版修复漏洞为主 用户是否要更新看体验再说
- iPhone13用户后悔?14全系列标配120Hz屏幕,可选8GB运行内存!
- 【e汽车】做更懂你的智能出行伙伴 魏牌举办用户粉丝节
- 2022年1月15日|魏牌:向用户型品牌转型,构建To C用户体验模式
- 首发小魏同学2.0车机形象 智能车控手表 魏牌用户粉丝节干货满满
- 锐龙|iOS15.2.1真的不好用吗?重度使用两天后,已升级用户都这样说