用户|KANO模型的量化处理
编辑导读:KANO模型主要是对用户需求分类和排序,通过分析用户对产品功能的满意程度,来对产品的功能进行升级,从而确定产品实现过程中的优先级。本文作者围绕“KANO模型的量化处理”进行分析,希望对你有帮助。
文章插图
很多大厂在产品商业化、产品设计以及运营方面已经达到了非常精细化程度,比如在对需求优先级进行排序的时候,大家都听说过KANO模型,很多产品经理也会采用该模型去“凭感觉”进行划分,但感觉的问题在于一些模糊不清的地带和一些需要通过互相说服来决策的时刻,这种定性的方式很难让人达成共识。于是很多公司的用研部门会将“定量”的方式引入其中进行辅助,尤其越是庞大的产品,越是会做这样的事情。
既然说到这,那就来聊聊KANO模型,在定量的方式上可以如何去实施。
背景就不去做交代了,假定目前已经确定了一些需求已经要做,但由于开发资源以及项目时间周期的限制,目前只能从中挑出一部分需求去进行设计,而且大家争执不下的情况下,于是通过收集到用户以及内部员工具体的一些答案通过统计结果来进行量化抉择,便挑选出合适的用户发出了调查问卷,设计问卷的时候为了方便后面的量化操作,问题需要存在一定的设计逻辑。
一、明确需求分类先基于KANO模型,可以把需求分成如下几类:
- M:必备型需求,即痛点
- O:期望型需求,即符合预期的
- A:兴奋型需求,即超出用户预期的
- I:无差异型需求,即用户不在意的
- R:反向型需求,即会引起用户反感的
你不觉得这玩意的底层逻辑跟之前接触过的很多东西都很像吗?比如,学校里面给学生打分的时候会有优秀、良好等方面的评级,公司里会按照不同岗位划分出不同的组织架构,哪怕去个奶茶店也会遇到小杯、中杯、大杯的区分。
这些东西的底层逻辑,要概括一下的话,其实都是基于MECE原则对某个事物按照“彼此独立,完全穷尽”的方式进行了分类而已。
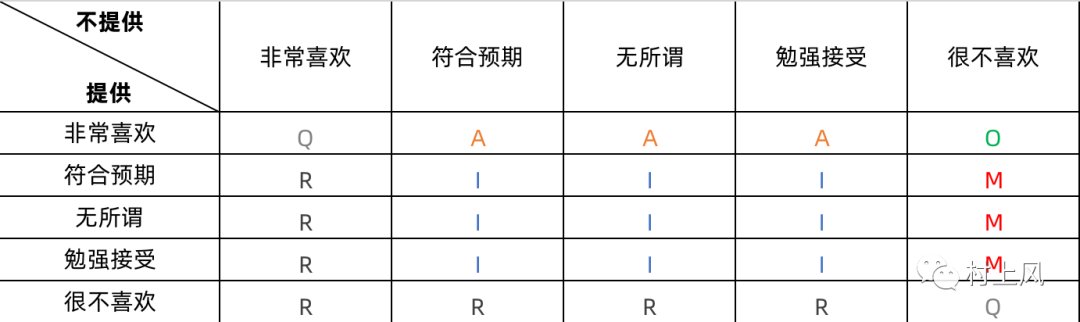
二、调查问卷设计为了更好的得到方便量化的结果,问题设计上可以分为两个方向并提供不同的选项供用户选择。
问题可以包含两个方向:增加某个功能后用户的态度以及不增加某个功能时用户的态度
答案则提供几种不同的程度,由喜欢程度的高到低分别是:非常喜欢、符合预期、无所谓、勉强接受、很不喜欢
最终构建出来的结果如下图所示:
文章插图
那么,在这里有一种比较特殊的情况,就是可疑结果(Q),毕竟对于一个功能的提供与否,用户都表现出了很喜欢或者很不喜欢这种自相矛盾的情况,所以,这样的结果在最终统计时,一般都需要排除掉。
同样,思维在这里稍微停一下,你会发现依然是一个仿佛接触过无数过的玩意。好像有点四象限法则的影子?好像还有点SWOT分析的赶脚?甚至这玩意还似曾相似的出现在你不知道要不要跳槽而感到迷茫时,你在纸上列出来的不同维度的对比……
其实,这些东西的底层就是矩阵思维,本质就是多角度纵横交叉的看待同样的一个问题。
三、调查问卷数据清洗加工在收集到问卷的结果后,对数据进行清洗并加工。下图所示就是之前我们在公司收集上来的调查问卷当中部分用户的反馈结果:
- 小米科技|预算只有两三千买这三款,颜值性能卓越,没有超高预算的用户看看
- 我们的生活|社交正在推动“孤独生意”多元化发展,天聊将重塑用户精神世界!
- 微信|数亿用户没白等,微信迎来更新,张小龙终于干正事了
- |OPPOK11x,精准的满足用户对于强续航,大存储、拍摄的需求
- iOS|苹果推送iOS15.2.1正式版修复漏洞为主 用户是否要更新看体验再说
- iPhone13用户后悔?14全系列标配120Hz屏幕,可选8GB运行内存!
- 【e汽车】做更懂你的智能出行伙伴 魏牌举办用户粉丝节
- 2022年1月15日|魏牌:向用户型品牌转型,构建To C用户体验模式
- 首发小魏同学2.0车机形象 智能车控手表 魏牌用户粉丝节干货满满
- 锐龙|iOS15.2.1真的不好用吗?重度使用两天后,已升级用户都这样说