文章图片
文章图片
文章图片
你一定听说过这句著名的数据科学名言:
如果你没有听过 , 那么请记住:数据清洗是数据科学工作流程的基础 。机器学习模型会根据你提供的数据执行 , 混乱的数据会导致性能下降甚至错误的结果 , 而干净的数据是良好模型性能的先决条件 。当然干净的数据并不意味着一直都有好的性能 , 模型的正确选择(剩余 20%)也很重要 , 但是没有干净的数据 , 即使是再强大的模型也无法达到预期的水平 。
在数据科学项目中 ,80% 的时间是在做数据处理 。
在本文中将列出数据清洗中需要解决的问题并展示可能的解决方案 , 通过本文可以了解如何逐步进行数据清洗 。
缺失值当数据集中包含缺失数据时 , 在填充之前可以先进行一些数据的分析 。因为空单元格本身的位置可以告诉我们一些有用的信息 。例如:
- NA值仅在数据集的尾部或中间出现 。这意味着在数据收集过程中可能存在技术问题 。可能需要分析该特定样本序列的数据收集过程 , 并尝试找出问题的根源 。
- 如果列NA数量超过 70–80% , 可以删除该列 。
- 如果 NA 值在表单中作为可选问题的列中 , 则该列可以被额外的编码为用户回答(1)或未回答(0) 。
import missingno as msno
msno.matrix(df)
对于缺失值的填补计算有很多方法 , 例如:
- 平均 , 中位数 , 众数
- kNN
- 零或常数等
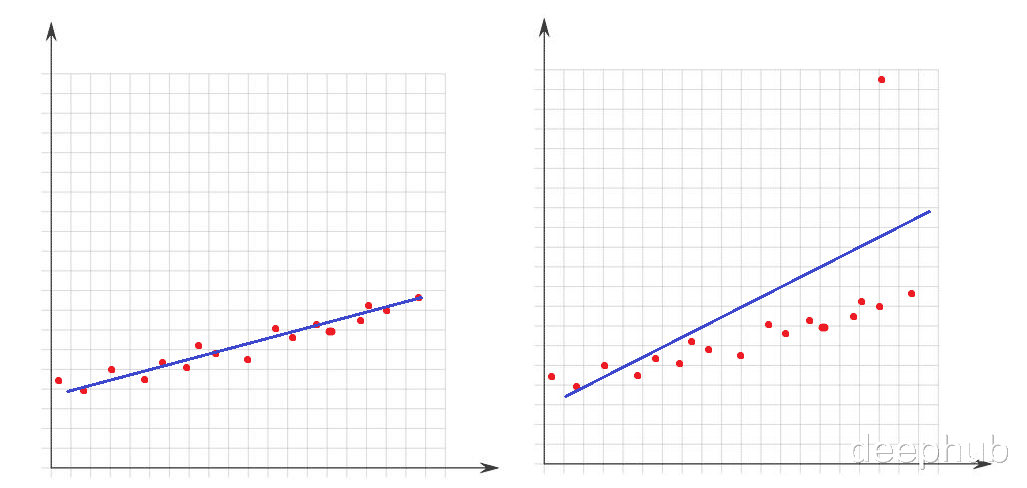
异常值异常值是相对于数据集的其他点而言非常大或非常小的值 。它们的存在极大地影响了数学模型的性能 。让我们看一下这个简单的示例:
在左图中没有异常值 , 我们的线性模型非常适合数据点 。在右图中有一个异常值 , 当模型试图覆盖数据集的所有点时 , 这个异常值的存在会改变模型的拟合方式 , 并且使我们的模型不适合至少一半的点 。
对于异常值来说我们有必要介绍一下如何确定异常 , 这就要从数学角度明确什么是极大或极小 。
大于Q3+1.5 x IQR或小于Q1-1.5 x IQR都可以作为异常值 。IQR(四分位距) 是 Q3 和 Q1 之间的差 (IQR = Q3-Q1) 。
可以使用下面函数来检查数据集中异常值的数量:
def number_of_outliers(df):
df = df.select_dtypes(exclude = 'object')
Q1 = df.quantile(0.25)
Q3 = df.quantile(0.75)
IQR = Q3 - Q1
return ((df < (Q1 - 1.5 * IQR)) | (df > (Q3 + 1.5 * IQR))).sum()
处理异常值的一种方法是可以让它们等于 Q3 或 Q1 。下面的lower_upper_range 函数使用 pandas 和 numpy 库查找其外部为异常值的范围 ,然后使用clip 函数将值裁剪到指定的范围 。
def lower_upper_range(datacolumn):
sorted(datacolumn)
Q1Q3 = np.percentile(datacolumn[2575
- 乳腺癌|乳腺癌患者进行即刻乳房再造被证明安全可行
- 棉签|采样拭子无毒无害,可放心使用
- AppleGlass|探索realityOS系统日常使用,科技博主自制苹果AR眼镜概念视频发布
- 2022年的安卓旗舰手机标配皆为新骁龙8或天玑9000|“钉子户”一加8t的使用感受
- |只需打开一个开关,手机就能开启“双系统”,同时使用互不干扰
- 华硕|华硕提醒:不要升级、卸载奥创智控中心 否则无法使用
- 微信|使用微信要注意:有一个“陷阱”很多人都不知道,早点告诉家里人
- 微信|【机器学习】Python编程语言的优势
- meta|美国的社交媒体改革正在盲目进行中!
- 产品设计|为什么SEO要对网站结构进行优化?