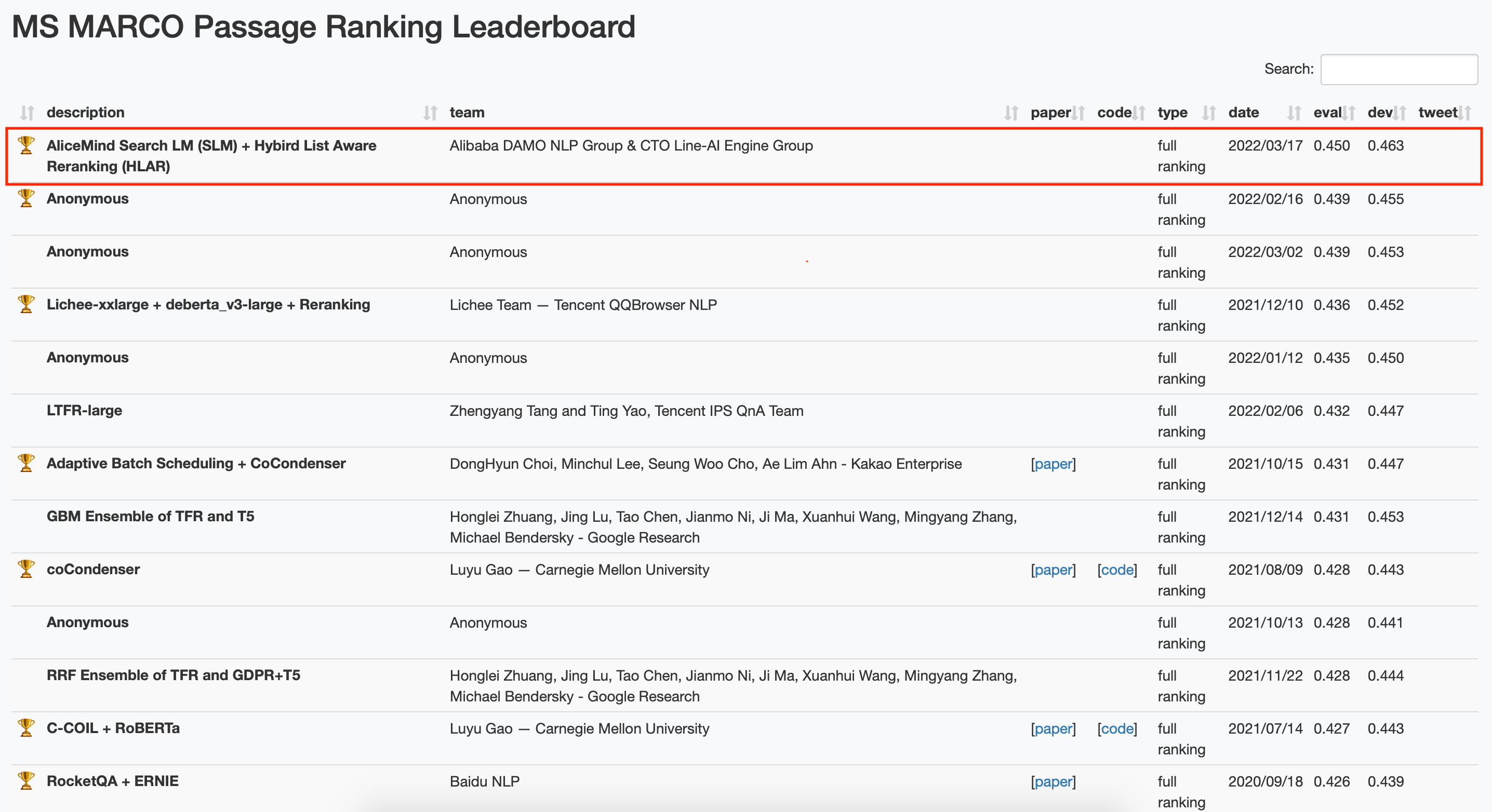
3月28日 , 阿里巴巴团队以0.450的得分 , 刷新了国际权威自然语言处理(NLP)榜单MS MARCO短文本检索排序任务历史纪录 。 据悉 , 该团队最新研发的文本检索及排序技术已通过阿里云智能搜索产品OpenSearch对外输出 。
【阿里巴巴|阿里推出文本搜索排序新技术,登顶国际权威NLP榜单MS MARCO】文本检索排序任务需根据指定查询词 , 检索数据集中所有文档并进行排序 。 相关技术在机器阅读理解、智能问答、搜索引擎等领域应用广泛 , 一直是NLP领域重要的研究课题 。 由于候选文档数量巨大 , 文本检索排序通常包括粗排(召回)和精排两个阶段 , 其核心是在每个阶段建模查询词和候选文档的语义相关性 。 近两年基于大规模预训练语言模型训练的文本检索排序模型 , 较传统的统计模型效果提升显著 , 但业界在针对该任务设计适用工业实践的预训练语言模型底座及下游模型上仍有待突破 。
MS MARCO是文本检索排序领域最具代表性的数据集 , 收录了微软Bing搜索引擎和Cortana智能助手近百万查询词与800万文档在内的真实搜索场景数据 。 自2018年MS MACRO短文本检索排序任务发布以来 , 在全球范围内吸引了包括谷歌、Facebook、卡内基梅隆大学等上百个研究团队竞相挑战 , 促进了文本检索排序技术的发展 。
3月28日 , 阿里巴巴团队采用全新研发的文本检索与排序技术 , 登上MS MARCO短文本检索排序榜单榜首较第二名得分提升2.5% 。
据了解 , 阿里达摩院语言技术实验室与智能引擎团队提出了针对文本检索排序任务的新型预训练语言模型解决方案 , 即Search Language Model (SLM) + Hybird List Aware Reranking (HLAR) 。 在粗排阶段 , 团队针对文本召回任务的特征设计了新的预训练语言模型SLM在保证召回效率的同时将召回阶段的效果提升了3.9% 。 在精排阶段 , 以StructRobertaLarge模型为底座 , 团队提出了以Transformer结构为基础、组合粗排与精排特征的重排序模型HLAR 进一步提升了文本排序的效果 。
上述解决方案已通过阿里云智能搜索产品OpenSearch对外输出 , 在电商、教育、游戏等多个行业搜索应用中对比通用模型效果提升10%以上 。
为推动中文领域文本检索与排序技术的发展 , 近期阿里也公开了基于阿里巴巴真实搜索场景数据构建的多领域文本搜索数据集Multi-CPR(论文: https://arxiv.org/abs/2203.03367 ;数据: https://github.com/Alibaba-NLP/Multi-CPR) 。 未来团队将逐步推进相关文本排序模型的开源 。
- iPad Pro|新款iPad Pro带有 M2和 MagSafe可能会在 2022 年秋季推出
- B2C|192期: 抖音跨境电商;华为全栈方案;京东业务线优化;腾讯阿里互联
- 小米推出多看电纸书Pro II,搭载7.8寸墨水屏,1199元值得买吗
- 阿里巴巴|营销,是一辈子的智慧
- 三星|11.4毫米超薄!三星推出新款M8智慧显示器:自带OS
- 小米|立式215m3/h大风量 小米推出米家3匹新风空调:众筹6949元
- 指控|NFT周刊|美国司法部对NFT诈骗进行了指控;LINE计划推出全球NFT平台“DOSI”;?Cool Cats签署代理协议
- 蚂蚁集团推出可信密态计算技术,可支撑隐私计算落地大规模数据
- 阿里巴巴|阿里女员工,辞职到沙特干快递,4年拓展10国,赚了几十亿?
- 今日|PS4、PS5系统更新今日上线 VRR功能几个月后推出