小鱼|可用性测试你不知道的Buff( 七 )
(2)有效度
主要理念在于是否密切关注到了你所在意的问题点,以及问卷问题是否与验证系统有关联性,对于效度也有效标效度(皮尔逊相关系数)和内容效度(因子分析)两种评估方法,不过并不一定要有很高的系数来证明很有效。
(3)灵敏度
指达到统计显著性所需的最小样本量,例如一个水果偏好二选一问卷,你问两个人可能是答案A,但是你问完10个人后却是B,当采量过小没能达到统计显著性所需最小样本量时,可能会获得不够准确的答案。
(4)客观性
一份问卷应该保持客观性,不能携带编辑者的个人偏好或主观意愿影响,这会让问卷有失统一性。
(5)重复性
尽可能的使问卷框架结构能够复用,一方面便于更多人可以研究验证,另一方面可以使得问卷本身价值最大化。
(6)可量化
对于问题的答复最好进行量化处理,而不是单纯的是或否,目的在于可使用高效的统计学方法来理解结果,或进行对比,亦或是数据可视化体现更加精密的差异。
所以说开发或调整一套标准可用的度量问卷也是一门富有学问的技术活,并非简单问几个问题这么简单。
2. 任务后评估问卷(ASQ)也叫场景后问卷,一般在可用性测试完毕后进行,它可以直观的在任务难度、完成效率和帮助信息上获取到测试者的直接反馈,主要就固定三道题目,答案采用5分制或7分制,所得分除以总分即可得到一个均分,该分值至少要大于0.6才能合格,要获得大部分人满意或认可,则要高于0.7。

文章插图
3. 系统可用性问卷(SUS)SUS总共10题,奇数项是正面描述题,偶数项是反面描述题,答题采用奇数的5分制。SUS益于它正反向问题结合,以及具有泛应用的可用性与易用性题型,在业内具有大量应用数据为基础,不论是客观性、灵敏度、可量化还是信度都具有较高的水准,这也是SUS能够成为可用性测试后问卷最主流的原因。

文章插图
(1)SUS量化分数计算
在SUS的相关创建者经过对大批数据的研究,其中可用性部分量表信度为0.91,易学性部分可行度为0.7,为使得整体量表得分兼容在0~100的范围,最终需要对可用性量表总分乘以3.125,易学性量表总分乘以12.5。而经过长期的应用迭代,最终分数的计算方式进行了定格:
- 步骤一:所有奇数编号题目得分减一后相加;
- 步骤二:所有偶数编号题目得分由五减去后相加;
- 步骤三:将奇数项最终得分+偶数项最终得分后 乘以2.5 即最终SUS得分。
在经过创建者的研究与沉淀,最终构成了5层不同级别的评级,A即最优评价,并且对应0~100分,有趣的是5个评级并非是将100分平分,为了解释评级与得分的强关联性,创建者新增了第11题进行整体而言的数据收集与分析,最终得到了以下图中所对应的关系。
如果说结果是“Good(C)”,那么对应的平均分值则是“71.4”,如果说你的得分高于85.5分,那你的评级则处于“Excellent(B)”,这可能已经意味着你的产品优于绝大部分产品了。
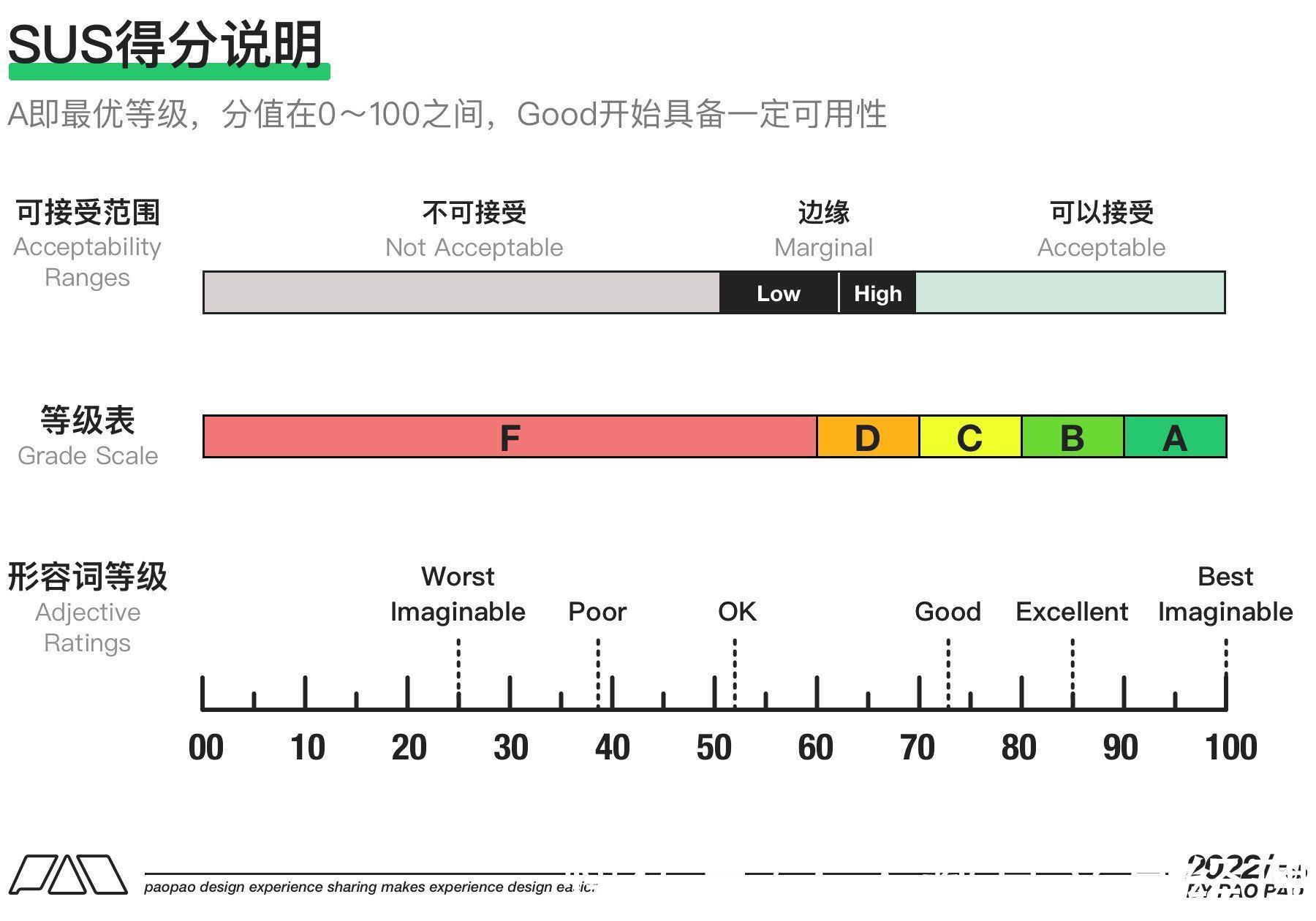
文章插图
4. 网站分析和测量表(WAMMI)WAMMI的建立是为了专门量化网站产品的,该问卷一共20道问题,采用5分制回答,整体信度高于0.9,但是吸引力、可控性、效率、帮助性、易学性多个因子测试信度只在0.63~0.74,因此该问卷对测试样本要求不少于30个。
若该产品属于学术或专业性较强类型,则样本量不少于100个,平均分值为50分,总分100分,但是也受样本量影响,WAMMI很难在可用性测试场景后使用,不过它的问题可以在小型可用性测试中进行应用或自检。
- 微软|微软 Win11 桌面贴纸功能上手体验:可自定义图案、调整大小
- 机械硬盘|切勿投机取巧囤硬盘:可能会被割
- 音箱|如果美国禁止出口安卓系统,鸿蒙系统可以一夜之间取代
- 4k|游戏玩家不可错过的几款电竞显示器,画面更真实更好看
- ipad怎么分屏两个应用
- swift|SWIFT来袭,威力可能被夸大
- 不拆分单词也可以做NLP,哈工大最新模型在多项任务中打败BERT
- NLP|不拆分单词也可以做NLP,哈工大最新模型在多项任务中打败BERT
- 苹果|可穿戴全凝胶多模态皮肤传感器可同时单点监测心脏相关的生物物理信号
- 36氪新风向|资本围猎虚拟人:腰缠万贯,无家可归